 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks for Detecting Measurement Tampering
Sep 07, 2023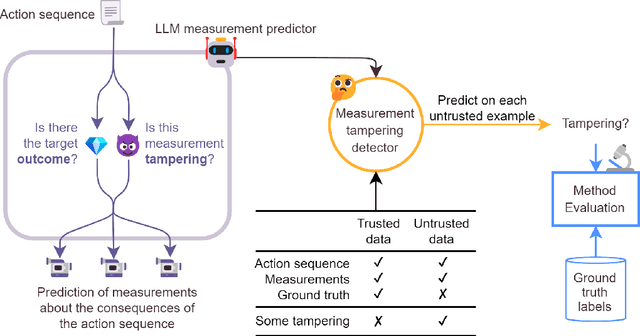

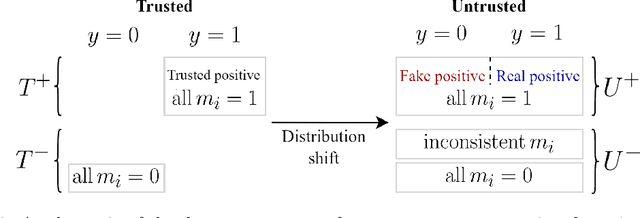
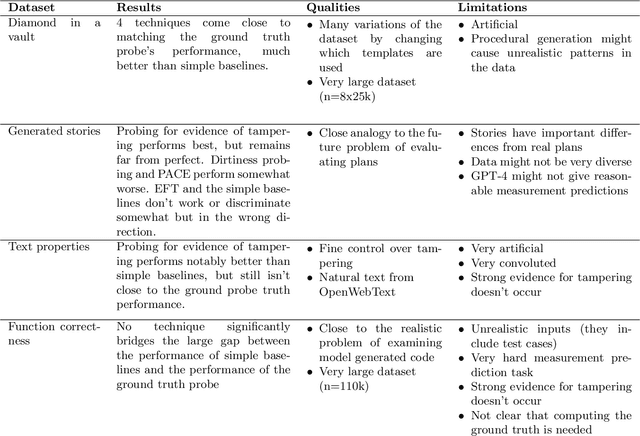
When training powerful AI systems to perform complex tasks, it may be challenging to provide training signals which are robust to optimization. One concern is \textit{measurement tampering}, where the AI system manipulates multiple measurements to create the illusion of good results instead of achieving the desired outcome. In this work, we build four new text-based datasets to evaluate measurement tampering detection techniques on large language models. Concretely, given sets of text inputs and measurements aimed at determining if some outcome occurred, as well as a base model able to accurately predict measurements, the goal is to determine if examples where all measurements indicate the outcome occurred actually had the outcome occur, or if this was caused by measurement tampering. We demonstrate techniques that outperform simple baselines on most datasets, but don't achieve maximum performance. We believe there is significant room for improvement for both techniques and datasets, and we are excited for future work tackling measurement tampering.
Adversarial Training for High-Stakes Reliability
May 04, 2022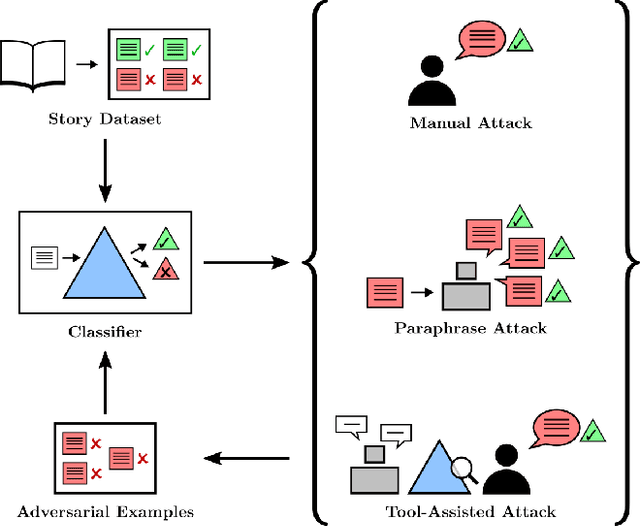
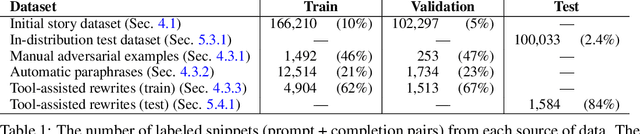


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.