 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThousands of AI Authors on the Future of AI
Jan 05, 2024



In the largest survey of its kind, 2,778 researchers who had published in top-tier artificial intelligence (AI) venues gave predictions on the pace of AI progress and the nature and impacts of advanced AI systems The aggregate forecasts give at least a 50% chance of AI systems achieving several milestones by 2028, including autonomously constructing a payment processing site from scratch, creating a song indistinguishable from a new song by a popular musician, and autonomously downloading and fine-tuning a large language model. If science continues undisrupted, the chance of unaided machines outperforming humans in every possible task was estimated at 10% by 2027, and 50% by 2047. The latter estimate is 13 years earlier than that reached in a similar survey we conducted only one year earlier [Grace et al., 2022]. However, the chance of all human occupations becoming fully automatable was forecast to reach 10% by 2037, and 50% as late as 2116 (compared to 2164 in the 2022 survey). Most respondents expressed substantial uncertainty about the long-term value of AI progress: While 68.3% thought good outcomes from superhuman AI are more likely than bad, of these net optimists 48% gave at least a 5% chance of extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes. Between 38% and 51% of respondents gave at least a 10% chance to advanced AI leading to outcomes as bad as human extinction. More than half suggested that "substantial" or "extreme" concern is warranted about six different AI-related scenarios, including misinformation, authoritarian control, and inequality. There was disagreement about whether faster or slower AI progress would be better for the future of humanity. However, there was broad agreement that research aimed at minimizing potential risks from AI systems ought to be prioritized more.
Adversarial Training for High-Stakes Reliability
May 04, 2022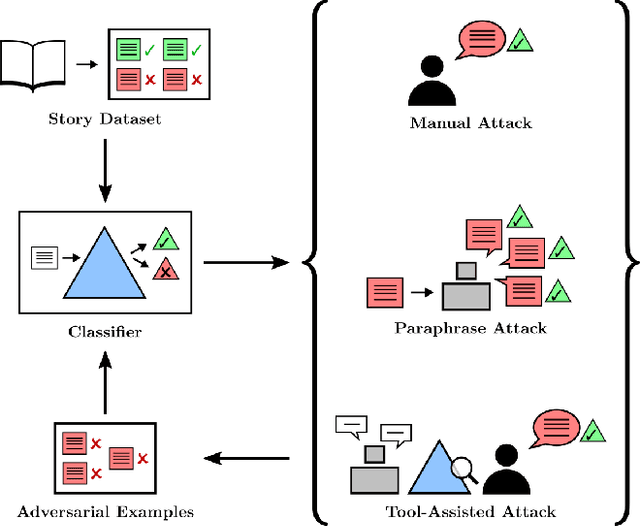
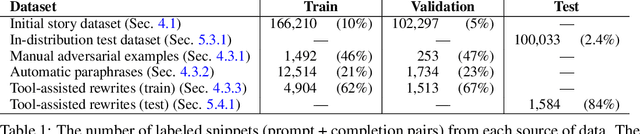


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.