 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Goal-Directedness of Large Language Models
Apr 16, 2025
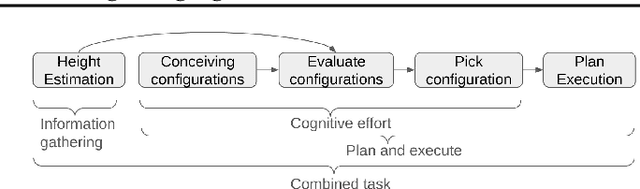
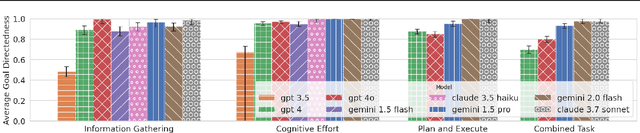
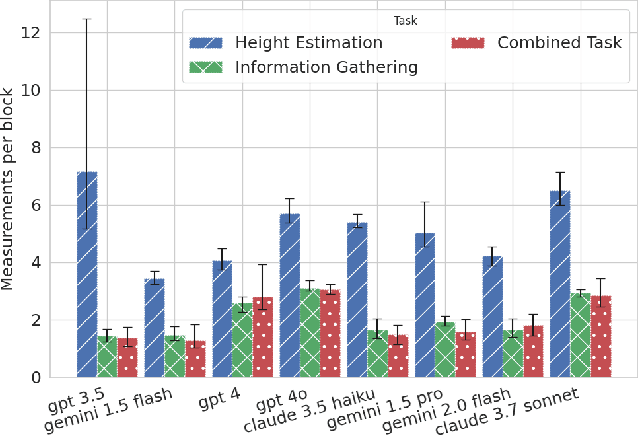
To what extent do LLMs use their capabilities towards their given goal? We take this as a measure of their goal-directedness. We evaluate goal-directedness on tasks that require information gathering, cognitive effort, and plan execution, where we use subtasks to infer each model's relevant capabilities. Our evaluations of LLMs from Google DeepMind, OpenAI, and Anthropic show that goal-directedness is relatively consistent across tasks, differs from task performance, and is only moderately sensitive to motivational prompts. Notably, most models are not fully goal-directed. We hope our goal-directedness evaluations will enable better monitoring of LLM progress, and enable more deliberate design choices of agentic properties in LLMs.
Mapping AI Benchmark Data to Quantitative Risk Estimates Through Expert Elicitation
Mar 06, 2025The literature and multiple experts point to many potential risks from large language models (LLMs), but there are still very few direct measurements of the actual harms posed. AI risk assessment has so far focused on measuring the models' capabilities, but the capabilities of models are only indicators of risk, not measures of risk. Better modeling and quantification of AI risk scenarios can help bridge this disconnect and link the capabilities of LLMs to tangible real-world harm. This paper makes an early contribution to this field by demonstrating how existing AI benchmarks can be used to facilitate the creation of risk estimates. We describe the results of a pilot study in which experts use information from Cybench, an AI benchmark, to generate probability estimates. We show that the methodology seems promising for this purpose, while noting improvements that can be made to further strengthen its application in quantitative AI risk assessment.
A Frontier AI Risk Management Framework: Bridging the Gap Between Current AI Practices and Established Risk Management
Feb 10, 2025

The recent development of powerful AI systems has highlighted the need for robust risk management frameworks in the AI industry. Although companies have begun to implement safety frameworks, current approaches often lack the systematic rigor found in other high-risk industries. This paper presents a comprehensive risk management framework for the development of frontier AI that bridges this gap by integrating established risk management principles with emerging AI-specific practices. The framework consists of four key components: (1) risk identification (through literature review, open-ended red-teaming, and risk modeling), (2) risk analysis and evaluation using quantitative metrics and clearly defined thresholds, (3) risk treatment through mitigation measures such as containment, deployment controls, and assurance processes, and (4) risk governance establishing clear organizational structures and accountability. Drawing from best practices in mature industries such as aviation or nuclear power, while accounting for AI's unique challenges, this framework provides AI developers with actionable guidelines for implementing robust risk management. The paper details how each component should be implemented throughout the life-cycle of the AI system - from planning through deployment - and emphasizes the importance and feasibility of conducting risk management work prior to the final training run to minimize the burden associated with it.
Linear Probe Penalties Reduce LLM Sycophancy
Dec 01, 2024Large language models (LLMs) are often sycophantic, prioritizing agreement with their users over accurate or objective statements. This problematic behavior becomes more pronounced during reinforcement learning from human feedback (RLHF), an LLM fine-tuning stage intended to align model outputs with human values. Instead of increasing accuracy and reliability, the reward model learned from RLHF often rewards sycophancy. We develop a linear probing method to identify and penalize markers of sycophancy within the reward model, producing rewards that discourage sycophantic behavior. Our experiments show that constructing and optimizing against this surrogate reward function reduces sycophantic behavior in multiple open-source LLMs. Our results suggest a generalizable methodology for reducing unwanted LLM behaviors that are not sufficiently disincentivized by RLHF fine-tuning.