 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebating with More Persuasive LLMs Leads to More Truthful Answers
Feb 15, 2024Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is \textit{debate}, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76\% and 88\% accuracy respectively (naive baselines obtain 48\% and 60\%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
AI Control: Improving Safety Despite Intentional Subversion
Dec 14, 2023As large language models (LLMs) become more powerful and are deployed more autonomously, it will be increasingly important to prevent them from causing harmful outcomes. Researchers have investigated a variety of safety techniques for this purpose, e.g. using models to review the outputs of other models, or red-teaming techniques to surface subtle failure modes. However, researchers have not evaluated whether such techniques still ensure safety if the model is itself intentionally trying to subvert them. In this paper, we develop and evaluate pipelines of safety techniques ("protocols") that are robust to intentional subversion. We investigate a scenario in which we want to solve a sequence of programming problems, using access to a powerful but untrusted model (in our case, GPT-4), access to a less powerful trusted model (in our case, GPT-3.5), and limited access to human contractors who provide high-quality trusted labor. We investigate protocols that aim to never submit solutions containing backdoors, which we operationalize here as logical errors that are not caught by test cases. We investigate a range of protocols and test each against strategies that the untrusted model could use to subvert them. One protocol is what we call trusted editing. This protocol first asks GPT-4 to write code, and then asks GPT-3.5 to rate the suspiciousness of that code. If the code is below some suspiciousness threshold, it is submitted. Otherwise, GPT-3.5 edits the solution to remove parts that seem suspicious and then submits the edited code. Another protocol is untrusted monitoring. This protocol asks GPT-4 to write code, and then asks another instance of GPT-4 whether the code is backdoored, using various techniques to prevent the GPT-4 instances from colluding. These protocols improve substantially on simple baselines.
Polysemanticity and Capacity in Neural Networks
Oct 04, 2022
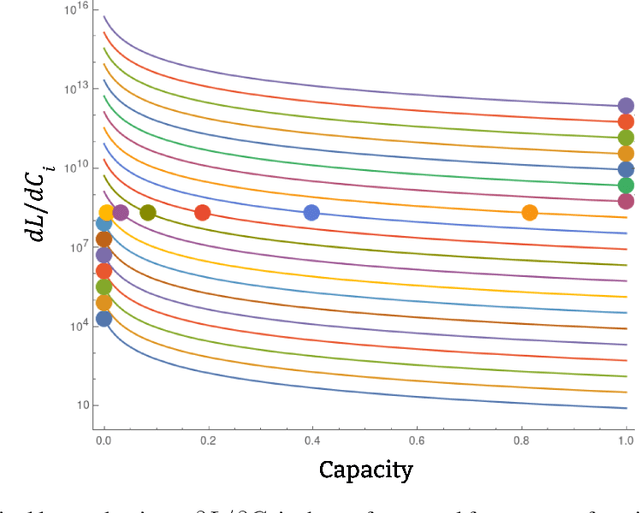
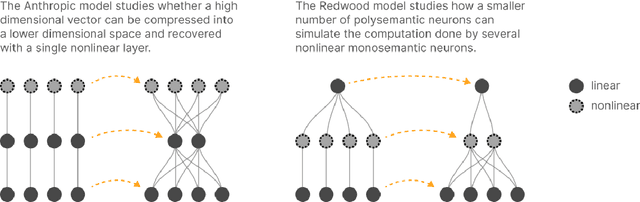
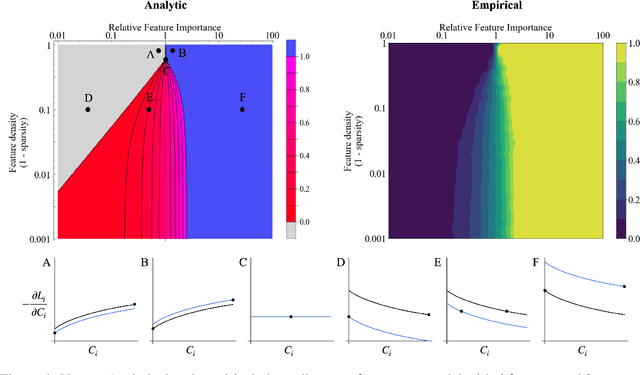
Individual neurons in neural networks often represent a mixture of unrelated features. This phenomenon, called polysemanticity, can make interpreting neural networks more difficult and so we aim to understand its causes. We propose doing so through the lens of feature \emph{capacity}, which is the fractional dimension each feature consumes in the embedding space. We show that in a toy model the optimal capacity allocation tends to monosemantically represent the most important features, polysemantically represent less important features (in proportion to their impact on the loss), and entirely ignore the least important features. Polysemanticity is more prevalent when the inputs have higher kurtosis or sparsity and more prevalent in some architectures than others. Given an optimal allocation of capacity, we go on to study the geometry of the embedding space. We find a block-semi-orthogonal structure, with differing block sizes in different models, highlighting the impact of model architecture on the interpretability of its neurons.