 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemanticity and Capacity in Neural Networks
Paper and Code
Oct 04, 2022
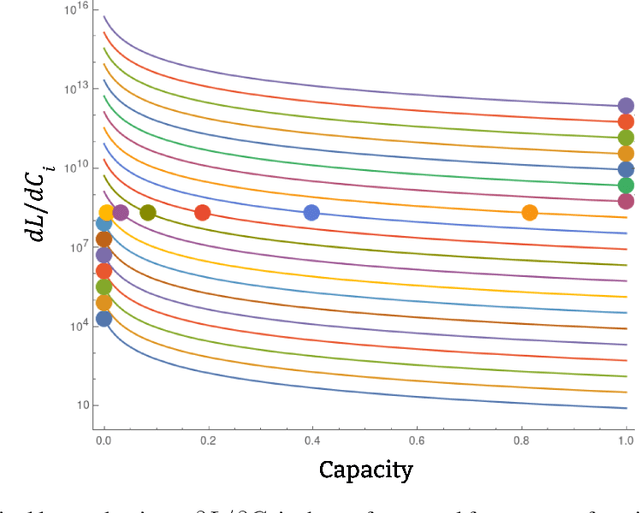
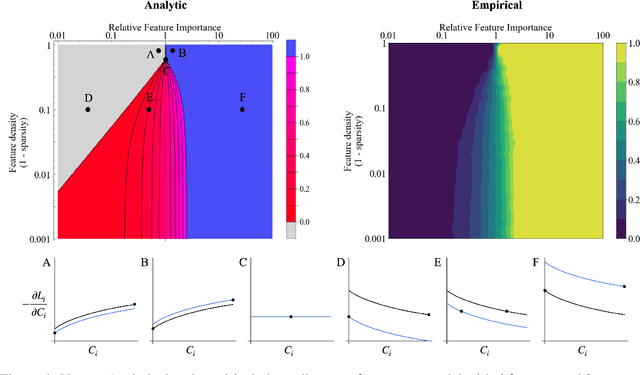
Individual neurons in neural networks often represent a mixture of unrelated features. This phenomenon, called polysemanticity, can make interpreting neural networks more difficult and so we aim to understand its causes. We propose doing so through the lens of feature \emph{capacity}, which is the fractional dimension each feature consumes in the embedding space. We show that in a toy model the optimal capacity allocation tends to monosemantically represent the most important features, polysemantically represent less important features (in proportion to their impact on the loss), and entirely ignore the least important features. Polysemanticity is more prevalent when the inputs have higher kurtosis or sparsity and more prevalent in some architectures than others. Given an optimal allocation of capacity, we go on to study the geometry of the embedding space. We find a block-semi-orthogonal structure, with differing block sizes in different models, highlighting the impact of model architecture on the interpretability of its neurons.