 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering Monosemanticity in Toy Models
Nov 16, 2022



In some neural networks, individual neurons correspond to natural ``features'' in the input. Such \emph{monosemantic} neurons are of great help in interpretability studies, as they can be cleanly understood. In this work we report preliminary attempts to engineer monosemanticity in toy models. We find that models can be made more monosemantic without increasing the loss by just changing which local minimum the training process finds. More monosemantic loss minima have moderate negative biases, and we are able to use this fact to engineer highly monosemantic models. We are able to mechanistically interpret these models, including the residual polysemantic neurons, and uncover a simple yet surprising algorithm. Finally, we find that providing models with more neurons per layer makes the models more monosemantic, albeit at increased computational cost. These findings point to a number of new questions and avenues for engineering monosemanticity, which we intend to study these in future work.
Polysemanticity and Capacity in Neural Networks
Oct 04, 2022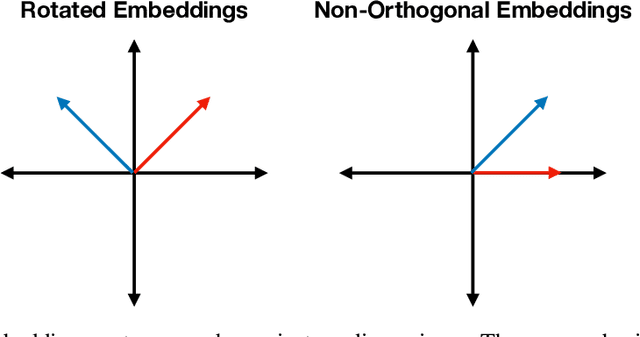
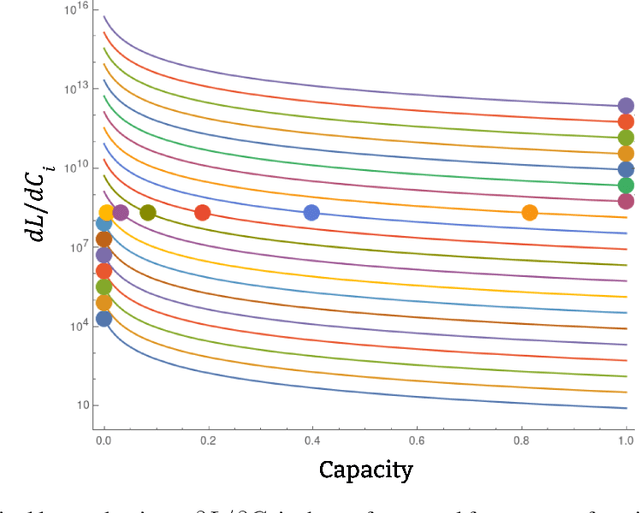
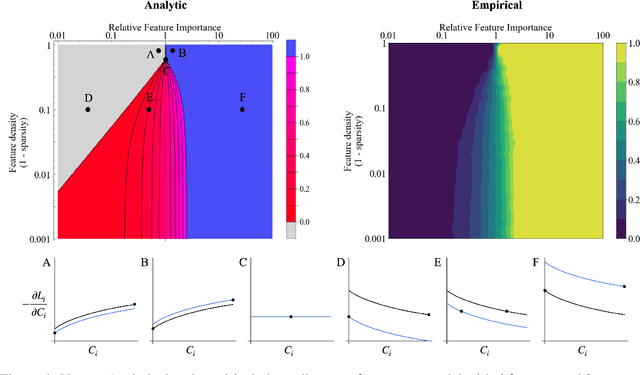
Individual neurons in neural networks often represent a mixture of unrelated features. This phenomenon, called polysemanticity, can make interpreting neural networks more difficult and so we aim to understand its causes. We propose doing so through the lens of feature \emph{capacity}, which is the fractional dimension each feature consumes in the embedding space. We show that in a toy model the optimal capacity allocation tends to monosemantically represent the most important features, polysemantically represent less important features (in proportion to their impact on the loss), and entirely ignore the least important features. Polysemanticity is more prevalent when the inputs have higher kurtosis or sparsity and more prevalent in some architectures than others. Given an optimal allocation of capacity, we go on to study the geometry of the embedding space. We find a block-semi-orthogonal structure, with differing block sizes in different models, highlighting the impact of model architecture on the interpretability of its neurons.
Algorithms for Tensor Network Contraction Ordering
Jan 15, 2020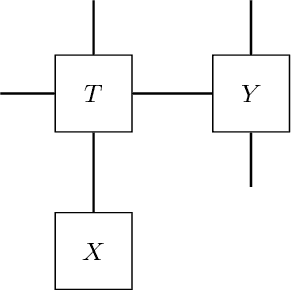
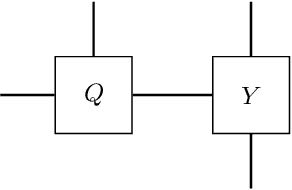
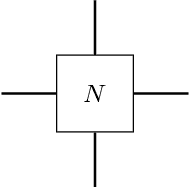
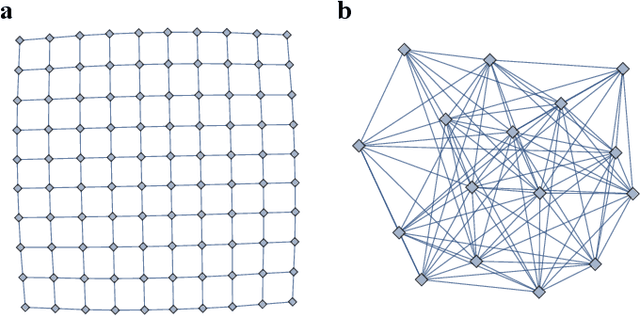
Contracting tensor networks is often computationally demanding. Well-designed contraction sequences can dramatically reduce the contraction cost. We explore the performance of simulated annealing and genetic algorithms, two common discrete optimization techniques, to this ordering problem. We benchmark their performance as well as that of the commonly-used greedy search on physically relevant tensor networks. Where computationally feasible, we also compare them with the optimal contraction sequence obtained by an exhaustive search. We find that the algorithms we consider consistently outperform a greedy search given equal computational resources, with an advantage that scales with tensor network size. We compare the obtained contraction sequences and identify signs of highly non-local optimization, with the more sophisticated algorithms sacrificing run-time early in the contraction for better overall performance.