 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-Constrained Neural Networks with Universal Approximation Guarantees
Oct 14, 2024Incorporating prior knowledge or specifications of input-output relationships into machine learning models has gained significant attention, as it enhances generalization from limited data and leads to conforming outputs. However, most existing approaches use soft constraints by penalizing violations through regularization, which offers no guarantee of constraint satisfaction -- an essential requirement in safety-critical applications. On the other hand, imposing hard constraints on neural networks may hinder their representational power, adversely affecting performance. To address this, we propose HardNet, a practical framework for constructing neural networks that inherently satisfy hard constraints without sacrificing model capacity. Specifically, we encode affine and convex hard constraints, dependent on both inputs and outputs, by appending a differentiable projection layer to the network's output. This architecture allows unconstrained optimization of the network parameters using standard algorithms while ensuring constraint satisfaction by construction. Furthermore, we show that HardNet retains the universal approximation capabilities of neural networks. We demonstrate the versatility and effectiveness of HardNet across various applications: fitting functions under constraints, learning optimization solvers, optimizing control policies in safety-critical systems, and learning safe decision logic for aircraft systems.
SketchOGD: Memory-Efficient Continual Learning
May 25, 2023



When machine learning models are trained continually on a sequence of tasks, they are liable to forget what they learned on previous tasks -- a phenomenon known as catastrophic forgetting. Proposed solutions to catastrophic forgetting tend to involve storing information about past tasks, meaning that memory usage is a chief consideration in determining their practicality. This paper proposes a memory-efficient solution to catastrophic forgetting, improving upon an established algorithm known as orthogonal gradient descent (OGD). OGD utilizes prior model gradients to find weight updates that preserve performance on prior datapoints. However, since the memory cost of storing prior model gradients grows with the runtime of the algorithm, OGD is ill-suited to continual learning over arbitrarily long time horizons. To address this problem, this paper proposes SketchOGD. SketchOGD employs an online sketching algorithm to compress model gradients as they are encountered into a matrix of a fixed, user-determined size. In contrast to existing memory-efficient variants of OGD, SketchOGD runs online without the need for advance knowledge of the total number of tasks, is simple to implement, and is more amenable to analysis. We provide theoretical guarantees on the approximation error of the relevant sketches under a novel metric suited to the downstream task of OGD. Experimentally, we find that SketchOGD tends to outperform current state-of-the-art variants of OGD given a fixed memory budget.
Data-Driven Control with Inherent Lyapunov Stability
Mar 06, 2023Recent advances in learning-based control leverage deep function approximators, such as neural networks, to model the evolution of controlled dynamical systems over time. However, the problem of learning a dynamics model and a stabilizing controller persists, since the synthesis of a stabilizing feedback law for known nonlinear systems is a difficult task, let alone for complex parametric representations that must be fit to data. To this end, we propose a method for jointly learning parametric representations of a nonlinear dynamics model and a stabilizing controller from data. To do this, our approach simultaneously learns a parametric Lyapunov function which intrinsically constrains the dynamics model to be stabilizable by the learned controller. In addition to the stabilizability of the learned dynamics guaranteed by our novel construction, we show that the learned controller stabilizes the true dynamics under certain assumptions on the fidelity of the learned dynamics. Finally, we demonstrate the efficacy of our method on a variety of simulated nonlinear dynamical systems.
DS-K3DOM: 3-D Dynamic Occupancy Mapping with Kernel Inference and Dempster-Shafer Evidential Theory
Sep 16, 2022


Occupancy mapping has been widely utilized to represent the surroundings for autonomous robots to perform tasks such as navigation and manipulation. While occupancy mapping in 2-D environments has been well-studied, there have been few approaches suitable for 3-D dynamic occupancy mapping which is essential for aerial robots. This paper presents a novel 3-D dynamic occupancy mapping algorithm called DSK3DOM. We first establish a Bayesian method to sequentially update occupancy maps for a stream of measurements based on the random finite set theory. Then, we approximate it with particles in the Dempster-Shafer domain to enable real time computation. Moreover, the algorithm applies kernel based inference with Dirichlet basic belief assignment to enable dense mapping from sparse measurements. The efficacy of the proposed algorithm is demonstrated through simulations and real experiments.
One-Pass Learning via Bridging Orthogonal Gradient Descent and Recursive Least-Squares
Jul 28, 2022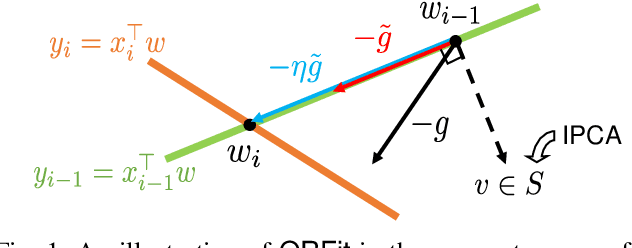

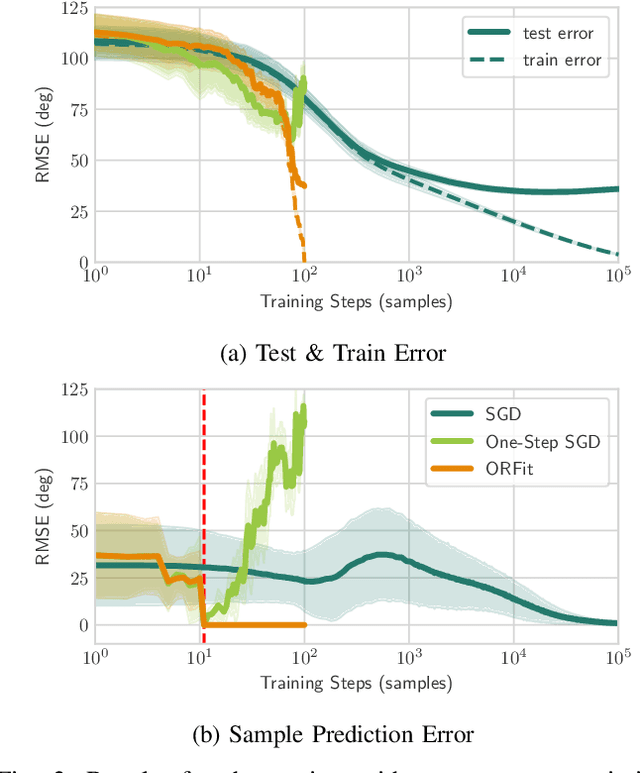
While deep neural networks are capable of achieving state-of-the-art performance in various domains, their training typically requires iterating for many passes over the dataset. However, due to computational and memory constraints and potential privacy concerns, storing and accessing all the data is impractical in many real-world scenarios where the data arrives in a stream. In this paper, we investigate the problem of one-pass learning, in which a model is trained on sequentially arriving data without retraining on previous datapoints. Motivated by the increasing use of overparameterized models, we develop Orthogonal Recursive Fitting (ORFit), an algorithm for one-pass learning which seeks to perfectly fit every new datapoint while changing the parameters in a direction that causes the least change to the predictions on previous datapoints. By doing so, we bridge two seemingly distinct algorithms in adaptive filtering and machine learning, namely the recursive least-squares (RLS) algorithm and orthogonal gradient descent (OGD). Our algorithm uses the memory efficiently by exploiting the structure of the streaming data via an incremental principal component analysis (IPCA). Further, we show that, for overparameterized linear models, the parameter vector obtained by our algorithm is what stochastic gradient descent (SGD) would converge to in the standard multi-pass setting. Finally, we generalize the results to the nonlinear setting for highly overparameterized models, relevant for deep learning. Our experiments show the effectiveness of the proposed method compared to the baselines.
Shallow Neural Network can Perfectly Classify an Object following Separable Probability Distribution
Apr 19, 2019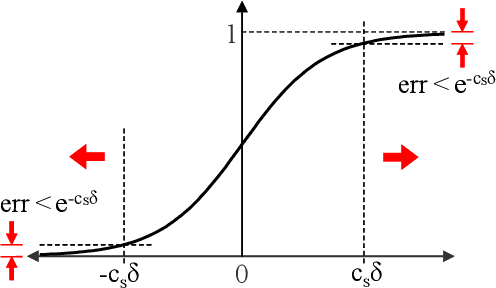



Guiding the design of neural networks is of great importance to save enormous resources consumed on empirical decisions of architectural parameters. This paper constructs shallow sigmoid-type neural networks that achieve 100% accuracy in classification for datasets following a linear separability condition. The separability condition in this work is more relaxed than the widely used linear separability. Moreover, the constructed neural network guarantees perfect classification for any datasets sampled from a separable probability distribution. This generalization capability comes from the saturation of sigmoid function that exploits small margins near the boundaries of intervals formed by the separable probability distribution.