 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardNet++: Nonlinear Constraint Enforcement in Neural Networks
Apr 21, 2026Enforcing constraint satisfaction in neural network outputs is critical for safety, reliability, and physical fidelity in many control and decision-making applications. While soft-constrained methods penalize constraint violations during training, they do not guarantee constraint adherence during inference. Other approaches guarantee constraint satisfaction via specific parameterizations or a projection layer, but are tailored to specific forms (e.g., linear constraints), limiting their utility in other general problem settings. Many real-world problems of interest are nonlinear, motivating the development of methods that can enforce general nonlinear constraints. To this end, we introduce HardNet++, a constraint-enforcement method that simultaneously satisfies linear and nonlinear equality and inequality constraints. Our approach iteratively adjusts the network output via damped local linearizations. Each iteration is differentiable, admitting an end-to-end training framework, where the constraint satisfaction layer is active during training. We show that under certain regularity conditions, this procedure can enforce nonlinear constraint satisfaction to arbitrary tolerance. Finally, we demonstrate tight constraint adherence without loss of optimality in a learning-for-optimization context, where we apply this method to a model predictive control problem with nonlinear state constraints.
LMI-Net: Linear Matrix Inequality--Constrained Neural Networks via Differentiable Projection Layers
Apr 07, 2026Linear matrix inequalities (LMIs) have played a central role in certifying stability, robustness, and forward invariance of dynamical systems. Despite rapid development in learning-based methods for control design and certificate synthesis, existing approaches often fail to preserve the hard matrix inequality constraints required for formal guarantees. We propose LMI-Net, an efficient and modular differentiable projection layer that enforces LMI constraints by construction. Our approach lifts the set defined by LMI constraints into the intersection of an affine equality constraint and the positive semidefinite cone, performs the forward pass via Douglas-Rachford splitting, and supports efficient backward propagation through implicit differentiation. We establish theoretical guarantees that the projection layer converges to a feasible point, certifying that LMI-Net transforms a generic neural network into a reliable model satisfying LMI constraints. Evaluated on experiments including invariant ellipsoid synthesis and joint controller-and-certificate design for a family of disturbed linear systems, LMI-Net substantially improves feasibility over soft-constrained models under distribution shift while retaining fast inference speed, bridging semidefinite-program-based certification and modern learning techniques.
Reverse Flow Matching: A Unified Framework for Online Reinforcement Learning with Diffusion and Flow Policies
Jan 13, 2026Diffusion and flow policies are gaining prominence in online reinforcement learning (RL) due to their expressive power, yet training them efficiently remains a critical challenge. A fundamental difficulty in online RL is the lack of direct samples from the target distribution; instead, the target is an unnormalized Boltzmann distribution defined by the Q-function. To address this, two seemingly distinct families of methods have been proposed for diffusion policies: a noise-expectation family, which utilizes a weighted average of noise as the training target, and a gradient-expectation family, which employs a weighted average of Q-function gradients. Yet, it remains unclear how these objectives relate formally or if they can be synthesized into a more general formulation. In this paper, we propose a unified framework, reverse flow matching (RFM), which rigorously addresses the problem of training diffusion and flow models without direct target samples. By adopting a reverse inferential perspective, we formulate the training target as a posterior mean estimation problem given an intermediate noisy sample. Crucially, we introduce Langevin Stein operators to construct zero-mean control variates, deriving a general class of estimators that effectively reduce importance sampling variance. We show that existing noise-expectation and gradient-expectation methods are two specific instances within this broader class. This unified view yields two key advancements: it extends the capability of targeting Boltzmann distributions from diffusion to flow policies, and enables the principled combination of Q-value and Q-gradient information to derive an optimal, minimum-variance estimator, thereby improving training efficiency and stability. We instantiate RFM to train a flow policy in online RL, and demonstrate improved performance on continuous-control benchmarks compared to diffusion policy baselines.
ATOM-CBF: Adaptive Safe Perception-Based Control under Out-of-Distribution Measurements
Nov 13, 2025Ensuring the safety of real-world systems is challenging, especially when they rely on learned perception modules to infer the system state from high-dimensional sensor data. These perception modules are vulnerable to epistemic uncertainty, often failing when encountering out-of-distribution (OoD) measurements not seen during training. To address this gap, we introduce ATOM-CBF (Adaptive-To-OoD-Measurement Control Barrier Function), a novel safe control framework that explicitly computes and adapts to the epistemic uncertainty from OoD measurements, without the need for ground-truth labels or information on distribution shifts. Our approach features two key components: (1) an OoD-aware adaptive perception error margin and (2) a safety filter that integrates this adaptive error margin, enabling the filter to adjust its conservatism in real-time. We provide empirical validation in simulations, demonstrating that ATOM-CBF maintains safety for an F1Tenth vehicle with LiDAR scans and a quadruped robot with RGB images.
HardFlow: Hard-Constrained Sampling for Flow-Matching Models via Trajectory Optimization
Nov 11, 2025Diffusion and flow-matching have emerged as powerful methodologies for generative modeling, with remarkable success in capturing complex data distributions and enabling flexible guidance at inference time. Many downstream applications, however, demand enforcing hard constraints on generated samples (for example, robot trajectories must avoid obstacles), a requirement that goes beyond simple guidance. Prevailing projection-based approaches constrain the entire sampling path to the constraint manifold, which is overly restrictive and degrades sample quality. In this paper, we introduce a novel framework that reformulates hard-constrained sampling as a trajectory optimization problem. Our key insight is to leverage numerical optimal control to steer the sampling trajectory so that constraints are satisfied precisely at the terminal time. By exploiting the underlying structure of flow-matching models and adopting techniques from model predictive control, we transform this otherwise complex constrained optimization problem into a tractable surrogate that can be solved efficiently and effectively. Furthermore, this trajectory optimization perspective offers significant flexibility beyond mere constraint satisfaction, allowing for the inclusion of integral costs to minimize distribution shift and terminal objectives to further enhance sample quality, all within a unified framework. We provide a control-theoretic analysis of our method, establishing bounds on the approximation error between our tractable surrogate and the ideal formulation. Extensive experiments across diverse domains, including robotics (planning), partial differential equations (boundary control), and vision (text-guided image editing), demonstrate that our algorithm, which we name $\textit{HardFlow}$, substantially outperforms existing methods in both constraint satisfaction and sample quality.
Test-Time-Scaling for Zero-Shot Diagnosis with Visual-Language Reasoning
Jun 11, 2025As a cornerstone of patient care, clinical decision-making significantly influences patient outcomes and can be enhanced by large language models (LLMs). Although LLMs have demonstrated remarkable performance, their application to visual question answering in medical imaging, particularly for reasoning-based diagnosis, remains largely unexplored. Furthermore, supervised fine-tuning for reasoning tasks is largely impractical due to limited data availability and high annotation costs. In this work, we introduce a zero-shot framework for reliable medical image diagnosis that enhances the reasoning capabilities of LLMs in clinical settings through test-time scaling. Given a medical image and a textual prompt, a vision-language model processes a medical image along with a corresponding textual prompt to generate multiple descriptions or interpretations of visual features. These interpretations are then fed to an LLM, where a test-time scaling strategy consolidates multiple candidate outputs into a reliable final diagnosis. We evaluate our approach across various medical imaging modalities -- including radiology, ophthalmology, and histopathology -- and demonstrate that the proposed test-time scaling strategy enhances diagnostic accuracy for both our and baseline methods. Additionally, we provide an empirical analysis showing that the proposed approach, which allows unbiased prompting in the first stage, improves the reliability of LLM-generated diagnoses and enhances classification accuracy.
Know What You Don't Know: Uncertainty Calibration of Process Reward Models
Jun 11, 2025Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated and often overestimate success probabilities. To address this, we present a calibration approach, performed via quantile regression, that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an \emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the inference budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach successfully adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method successfully achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective adaptive scaling, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired.
Constrained Online Decision-Making: A Unified Framework
May 16, 2025Contextual online decision-making problems with constraints appear in various real-world applications, such as personalized recommendation with resource limits and dynamic pricing with fairness constraints. In this paper, we investigate a general formulation of sequential decision-making with stage-wise feasibility constraints, where at each round, the learner must select an action based on observed context while ensuring a problem-specific feasibility criterion. We propose a unified algorithmic framework that captures many existing constrained learning problems, including constrained bandits, stream active learning, online hypothesis testing, and model calibration. Central to our approach is the concept of upper counterfactual confidence bound, which enables the design of practically efficient online algorithms using any offline conditional density estimation oracle. Technically, to handle feasibility constraints, we introduce a generalized notion of the eluder dimension, extending it from the classical setting based on square loss to a broader class of metric-like probability divergences, which could capture the complexity of various density function classes and characterize the loss incurred due to feasibility constraint uncertainty. Our result offers a principled foundation for constrained sequential decision-making in both theory and practice.
Constrained Online Decision-Making with Density Estimation Oracles
May 11, 2025Contextual online decision-making problems with constraints appear in a wide range of real-world applications, such as personalized recommendation with resource limits, adaptive experimental design, and decision-making under safety or fairness requirements. In this paper, we investigate a general formulation of sequential decision-making with stage-wise feasibility constraints, where at each round, the learner must select an action based on observed context while ensuring that a problem-specific feasibility criterion is satisfied. We propose a unified algorithmic framework that captures many existing constrained learning problems, including constrained bandits, active learning with label budgets, online hypothesis testing with Type I error control, and model calibration. Central to our approach is the concept of upper counterfactual confidence bounds, which enables the design of practically efficient online algorithms with strong theoretical guarantee using any offline conditional density estimation oracle. Technically, to handle feasibility constraints in complex environments, we introduce a generalized notion of the eluder dimension - extending it from the classical setting based on square loss to a broader class of metric-like probability divergences. This allows us to capture the complexity of various density function classes and characterize the utility regret incurred due to feasibility constraint uncertainty. Our result offers a principled foundation for constrained sequential decision-making in both theory and practice.
Activation-Informed Merging of Large Language Models
Feb 04, 2025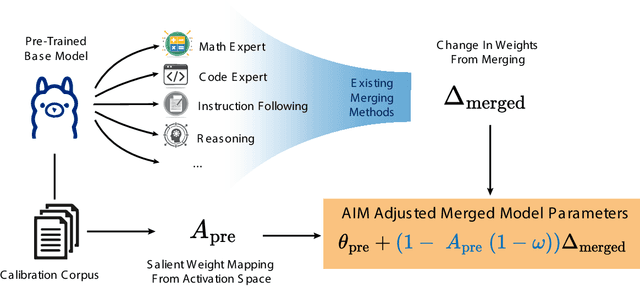
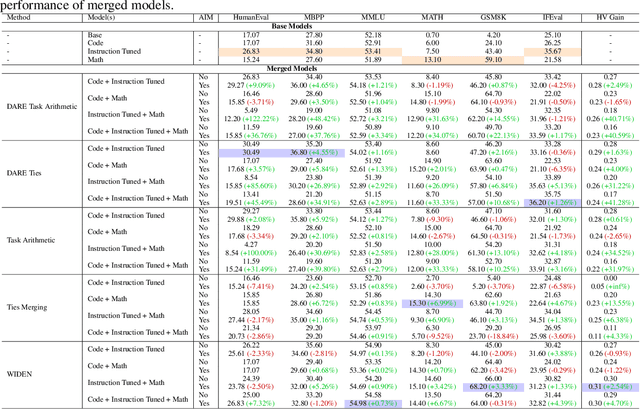
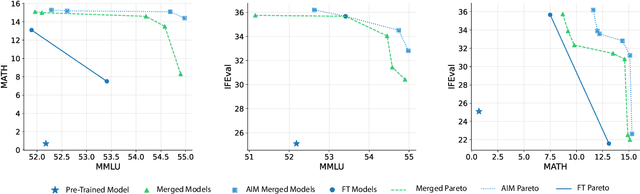
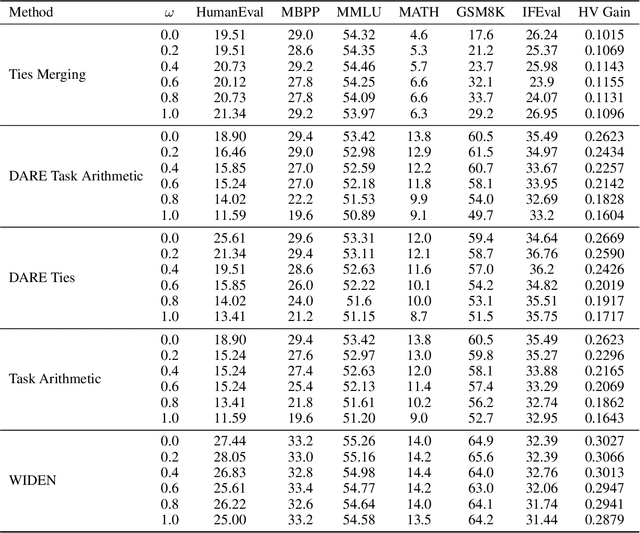
Model merging, a method that combines the parameters and embeddings of multiple fine-tuned large language models (LLMs), offers a promising approach to enhance model performance across various tasks while maintaining computational efficiency. This paper introduces Activation-Informed Merging (AIM), a technique that integrates the information from the activation space of LLMs into the merging process to improve performance and robustness. AIM is designed as a flexible, complementary solution that is applicable to any existing merging method. It aims to preserve critical weights from the base model, drawing on principles from continual learning~(CL) and model compression. Utilizing a task-agnostic calibration set, AIM selectively prioritizes essential weights during merging. We empirically demonstrate that AIM significantly enhances the performance of merged models across multiple benchmarks. Our findings suggest that considering the activation-space information can provide substantial advancements in the model merging strategies for LLMs with up to 40\% increase in benchmark performance.