 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Slip Detection and Friction Coefficient Estimation for Autonomous Racing
Sep 18, 2025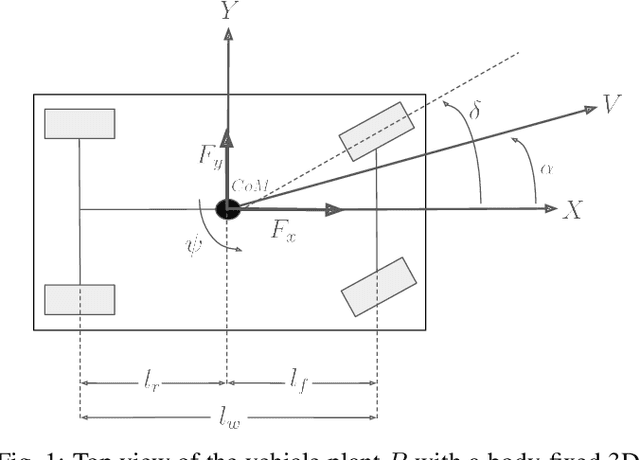
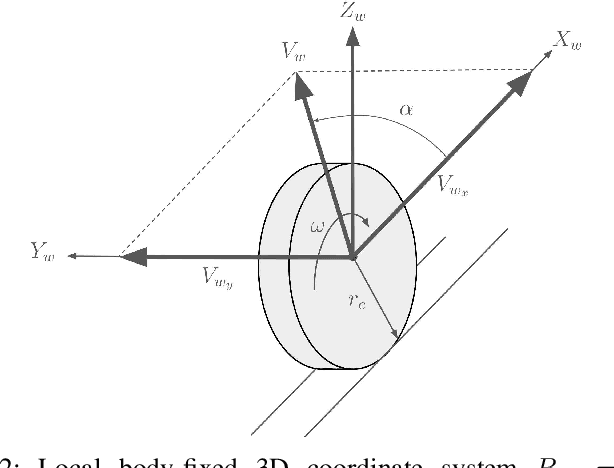
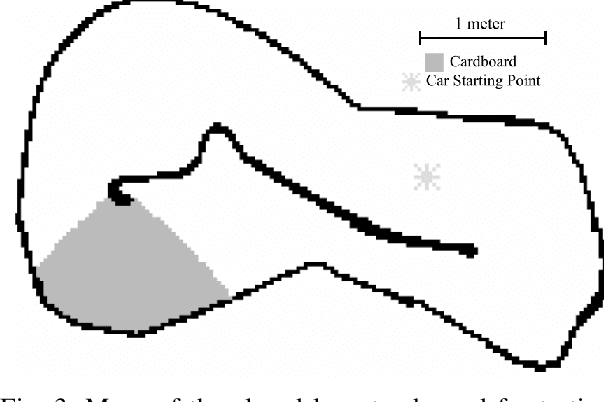
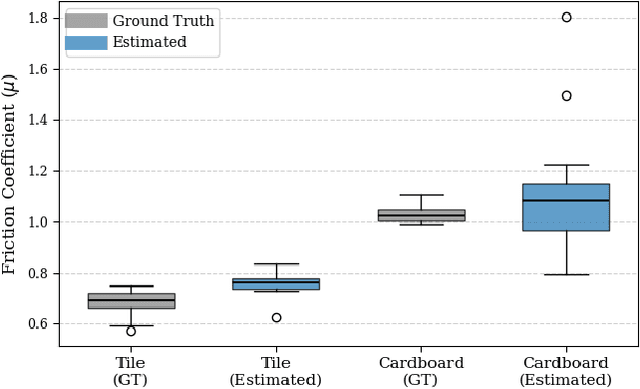
Accurate knowledge of the tire-road friction coefficient (TRFC) is essential for vehicle safety, stability, and performance, especially in autonomous racing, where vehicles often operate at the friction limit. However, TRFC cannot be directly measured with standard sensors, and existing estimation methods either depend on vehicle or tire models with uncertain parameters or require large training datasets. In this paper, we present a lightweight approach for online slip detection and TRFC estimation. Our approach relies solely on IMU and LiDAR measurements and the control actions, without special dynamical or tire models, parameter identification, or training data. Slip events are detected in real time by comparing commanded and measured motions, and the TRFC is then estimated directly from observed accelerations under no-slip conditions. Experiments with a 1:10-scale autonomous racing car across different friction levels demonstrate that the proposed approach achieves accurate and consistent slip detections and friction coefficients, with results closely matching ground-truth measurements. These findings highlight the potential of our simple, deployable, and computationally efficient approach for real-time slip monitoring and friction coefficient estimation in autonomous driving.
Generalizable Image Repair for Robust Visual Autonomous Racing
Mar 07, 2025
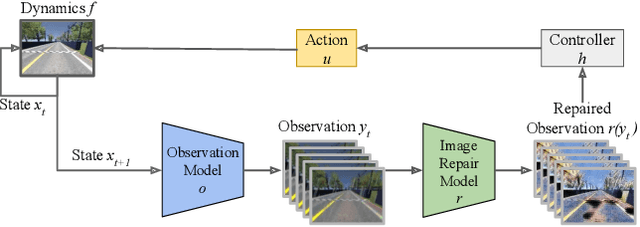
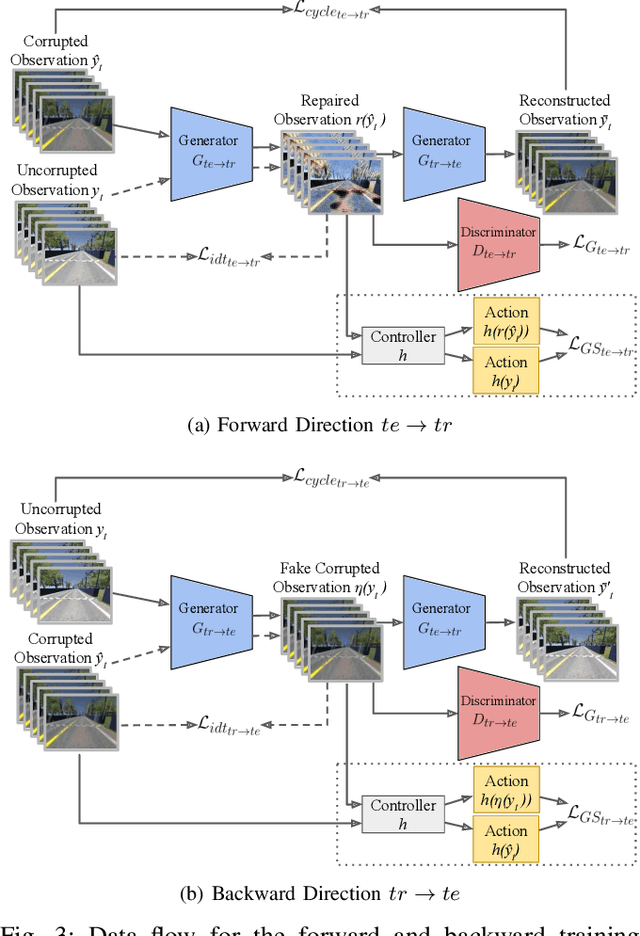

Vision-based autonomous racing relies on accurate perception for robust control. However, image distribution changes caused by sensor noise, adverse weather, and dynamic lighting can degrade perception, leading to suboptimal control decisions. Existing approaches, including domain adaptation and adversarial training, improve robustness but struggle to generalize to unseen corruptions while introducing computational overhead. To address this challenge, we propose a real-time image repair module that restores corrupted images before they are used by the controller. Our method leverages generative adversarial models, specifically CycleGAN and pix2pix, for image repair. CycleGAN enables unpaired image-to-image translation to adapt to novel corruptions, while pix2pix exploits paired image data when available to improve the quality. To ensure alignment with control performance, we introduce a control-focused loss function that prioritizes perceptual consistency in repaired images. We evaluated our method in a simulated autonomous racing environment with various visual corruptions. The results show that our approach significantly improves performance compared to baselines, mitigating distribution shift and enhancing controller reliability.
Identifying Reliable Predictions in Detection Transformers
Dec 02, 2024



DEtection TRansformer (DETR) has emerged as a promising architecture for object detection, offering an end-to-end prediction pipeline. In practice, however, DETR generates hundreds of predictions that far outnumber the actual number of objects present in an image. This raises the question: can we trust and use all of these predictions? Addressing this concern, we present empirical evidence highlighting how different predictions within the same image play distinct roles, resulting in varying reliability levels across those predictions. More specifically, while multiple predictions are often made for a single object, our findings show that most often one such prediction is well-calibrated, and the others are poorly calibrated. Based on these insights, we demonstrate identifying a reliable subset of DETR's predictions is crucial for accurately assessing the reliability of the model at both object and image levels. Building on this viewpoint, we first tackle the shortcomings of widely used performance and calibration metrics, such as average precision and various forms of expected calibration error. Specifically, they are inadequate for determining which subset of DETR's predictions should be trusted and utilized. In response, we present Object-level Calibration Error (OCE), which is capable of assessing the calibration quality both across different models and among various configurations within a specific model. As a final contribution, we introduce a post hoc Uncertainty Quantification (UQ) framework that predicts the accuracy of the model on a per-image basis. By contrasting the average confidence scores of positive (i.e., likely to be matched) and negative predictions determined by OCE, the framework assesses the reliability of the DETR model for each test image.
How Safe Am I Given What I See? Calibrated Prediction of Safety Chances for Image-Controlled Autonomy
Aug 23, 2023



End-to-end learning has emerged as a major paradigm for developing autonomous systems. Unfortunately, with its performance and convenience comes an even greater challenge of safety assurance. A key factor of this challenge is the absence of the notion of a low-dimensional and interpretable dynamical state, around which traditional assurance methods revolve. Focusing on the online safety prediction problem, this paper proposes a configurable family of learning pipelines based on generative world models, which do not require low-dimensional states. To implement these pipelines, we overcome the challenges of learning safety-informed latent representations and missing safety labels under prediction-induced distribution shift. These pipelines come with statistical calibration guarantees on their safety chance predictions based on conformal prediction. We perform an extensive evaluation of the proposed learning pipelines on two case studies of image-controlled systems: a racing car and a cartpole.