 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained AI Model Assisted Online Decision-Making under Missing Covariates: A Theoretical Perspective
Jul 10, 2025We study a sequential contextual decision-making problem in which certain covariates are missing but can be imputed using a pre-trained AI model. From a theoretical perspective, we analyze how the presence of such a model influences the regret of the decision-making process. We introduce a novel notion called "model elasticity", which quantifies the sensitivity of the reward function to the discrepancy between the true covariate and its imputed counterpart. This concept provides a unified way to characterize the regret incurred due to model imputation, regardless of the underlying missingness mechanism. More surprisingly, we show that under the missing at random (MAR) setting, it is possible to sequentially calibrate the pre-trained model using tools from orthogonal statistical learning and doubly robust regression. This calibration significantly improves the quality of the imputed covariates, leading to much better regret guarantees. Our analysis highlights the practical value of having an accurate pre-trained model in sequential decision-making tasks and suggests that model elasticity may serve as a fundamental metric for understanding and improving the integration of pre-trained models in a wide range of data-driven decision-making problems.
Constrained Online Decision-Making: A Unified Framework
May 16, 2025Contextual online decision-making problems with constraints appear in various real-world applications, such as personalized recommendation with resource limits and dynamic pricing with fairness constraints. In this paper, we investigate a general formulation of sequential decision-making with stage-wise feasibility constraints, where at each round, the learner must select an action based on observed context while ensuring a problem-specific feasibility criterion. We propose a unified algorithmic framework that captures many existing constrained learning problems, including constrained bandits, stream active learning, online hypothesis testing, and model calibration. Central to our approach is the concept of upper counterfactual confidence bound, which enables the design of practically efficient online algorithms using any offline conditional density estimation oracle. Technically, to handle feasibility constraints, we introduce a generalized notion of the eluder dimension, extending it from the classical setting based on square loss to a broader class of metric-like probability divergences, which could capture the complexity of various density function classes and characterize the loss incurred due to feasibility constraint uncertainty. Our result offers a principled foundation for constrained sequential decision-making in both theory and practice.
Constrained Online Decision-Making with Density Estimation Oracles
May 11, 2025Contextual online decision-making problems with constraints appear in a wide range of real-world applications, such as personalized recommendation with resource limits, adaptive experimental design, and decision-making under safety or fairness requirements. In this paper, we investigate a general formulation of sequential decision-making with stage-wise feasibility constraints, where at each round, the learner must select an action based on observed context while ensuring that a problem-specific feasibility criterion is satisfied. We propose a unified algorithmic framework that captures many existing constrained learning problems, including constrained bandits, active learning with label budgets, online hypothesis testing with Type I error control, and model calibration. Central to our approach is the concept of upper counterfactual confidence bounds, which enables the design of practically efficient online algorithms with strong theoretical guarantee using any offline conditional density estimation oracle. Technically, to handle feasibility constraints in complex environments, we introduce a generalized notion of the eluder dimension - extending it from the classical setting based on square loss to a broader class of metric-like probability divergences. This allows us to capture the complexity of various density function classes and characterize the utility regret incurred due to feasibility constraint uncertainty. Our result offers a principled foundation for constrained sequential decision-making in both theory and practice.
Contextual Online Decision Making with Infinite-Dimensional Functional Regression
Jan 30, 2025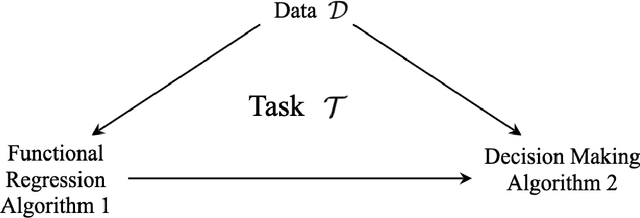
Contextual sequential decision-making problems play a crucial role in machine learning, encompassing a wide range of downstream applications such as bandits, sequential hypothesis testing and online risk control. These applications often require different statistical measures, including expectation, variance and quantiles. In this paper, we provide a universal admissible algorithm framework for dealing with all kinds of contextual online decision-making problems that directly learns the whole underlying unknown distribution instead of focusing on individual statistics. This is much more difficult because the dimension of the regression is uncountably infinite, and any existing linear contextual bandits algorithm will result in infinite regret. To overcome this issue, we propose an efficient infinite-dimensional functional regression oracle for contextual cumulative distribution functions (CDFs), where each data point is modeled as a combination of context-dependent CDF basis functions. Our analysis reveals that the decay rate of the eigenvalue sequence of the design integral operator governs the regression error rate and, consequently, the utility regret rate. Specifically, when the eigenvalue sequence exhibits a polynomial decay of order $\frac{1}{\gamma}\ge 1$, the utility regret is bounded by $\tilde{\mathcal{O}}\Big(T^{\frac{3\gamma+2}{2(\gamma+2)}}\Big)$. By setting $\gamma=0$, this recovers the existing optimal regret rate for contextual bandits with finite-dimensional regression and is optimal under a stronger exponential decay assumption. Additionally, we provide a numerical method to compute the eigenvalue sequence of the integral operator, enabling the practical implementation of our framework.
Offline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff
May 28, 2024
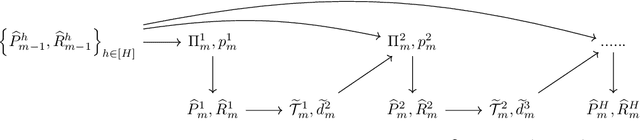
Motivated by the recent discovery of a statistical and computational reduction from contextual bandits to offline regression (Simchi-Levi and Xu, 2021), we address the general (stochastic) Contextual Markov Decision Process (CMDP) problem with horizon H (as known as CMDP with H layers). In this paper, we introduce a reduction from CMDPs to offline density estimation under the realizability assumption, i.e., a model class M containing the true underlying CMDP is provided in advance. We develop an efficient, statistically near-optimal algorithm requiring only O(HlogT) calls to an offline density estimation algorithm (or oracle) across all T rounds of interaction. This number can be further reduced to O(HloglogT) if T is known in advance. Our results mark the first efficient and near-optimal reduction from CMDPs to offline density estimation without imposing any structural assumptions on the model class. A notable feature of our algorithm is the design of a layerwise exploration-exploitation tradeoff tailored to address the layerwise structure of CMDPs. Additionally, our algorithm is versatile and applicable to pure exploration tasks in reward-free reinforcement learning.