 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff
Paper and Code
May 28, 2024
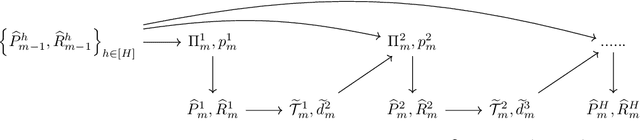
Motivated by the recent discovery of a statistical and computational reduction from contextual bandits to offline regression (Simchi-Levi and Xu, 2021), we address the general (stochastic) Contextual Markov Decision Process (CMDP) problem with horizon H (as known as CMDP with H layers). In this paper, we introduce a reduction from CMDPs to offline density estimation under the realizability assumption, i.e., a model class M containing the true underlying CMDP is provided in advance. We develop an efficient, statistically near-optimal algorithm requiring only O(HlogT) calls to an offline density estimation algorithm (or oracle) across all T rounds of interaction. This number can be further reduced to O(HloglogT) if T is known in advance. Our results mark the first efficient and near-optimal reduction from CMDPs to offline density estimation without imposing any structural assumptions on the model class. A notable feature of our algorithm is the design of a layerwise exploration-exploitation tradeoff tailored to address the layerwise structure of CMDPs. Additionally, our algorithm is versatile and applicable to pure exploration tasks in reward-free reinforcement learning.