 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-Constrained Neural Networks with Universal Approximation Guarantees
Oct 14, 2024Incorporating prior knowledge or specifications of input-output relationships into machine learning models has gained significant attention, as it enhances generalization from limited data and leads to conforming outputs. However, most existing approaches use soft constraints by penalizing violations through regularization, which offers no guarantee of constraint satisfaction -- an essential requirement in safety-critical applications. On the other hand, imposing hard constraints on neural networks may hinder their representational power, adversely affecting performance. To address this, we propose HardNet, a practical framework for constructing neural networks that inherently satisfy hard constraints without sacrificing model capacity. Specifically, we encode affine and convex hard constraints, dependent on both inputs and outputs, by appending a differentiable projection layer to the network's output. This architecture allows unconstrained optimization of the network parameters using standard algorithms while ensuring constraint satisfaction by construction. Furthermore, we show that HardNet retains the universal approximation capabilities of neural networks. We demonstrate the versatility and effectiveness of HardNet across various applications: fitting functions under constraints, learning optimization solvers, optimizing control policies in safety-critical systems, and learning safe decision logic for aircraft systems.
Invariant Policy Optimization: Towards Stronger Generalization in Reinforcement Learning
Jun 01, 2020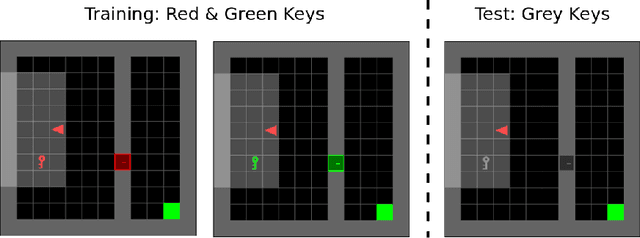

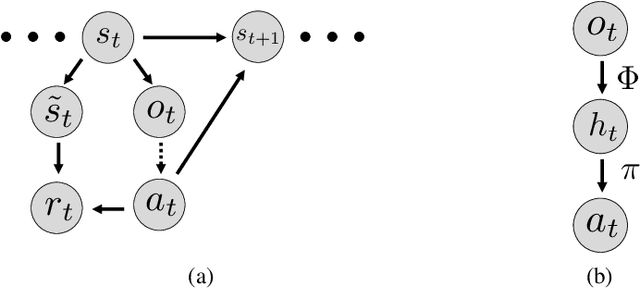

A fundamental challenge in reinforcement learning is to learn policies that generalize beyond the operating domain experienced during training. In this paper, we approach this challenge through the following invariance principle: an agent must find a representation such that there exists an action-predictor built on top of this representation that is simultaneously optimal across all training domains. Intuitively, the resulting invariant policy enhances generalization by finding causes of successful actions. We propose a novel learning algorithm, Invariant Policy Optimization (IPO), that explicitly enforces this principle and learns an invariant policy during training. We compare our approach with standard policy gradient methods and demonstrate significant improvements in generalization performance on unseen domains for Linear Quadratic Regulator (LQR) problems and our own benchmark in the MiniGrid Gym environment.