 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Policy Optimization: Towards Stronger Generalization in Reinforcement Learning
Paper and Code
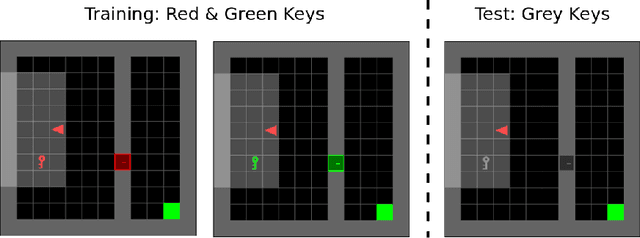


A fundamental challenge in reinforcement learning is to learn policies that generalize beyond the operating domain experienced during training. In this paper, we approach this challenge through the following invariance principle: an agent must find a representation such that there exists an action-predictor built on top of this representation that is simultaneously optimal across all training domains. Intuitively, the resulting invariant policy enhances generalization by finding causes of successful actions. We propose a novel learning algorithm, Invariant Policy Optimization (IPO), that explicitly enforces this principle and learns an invariant policy during training. We compare our approach with standard policy gradient methods and demonstrate significant improvements in generalization performance on unseen domains for Linear Quadratic Regulator (LQR) problems and our own benchmark in the MiniGrid Gym environment.