 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Jul 31, 2024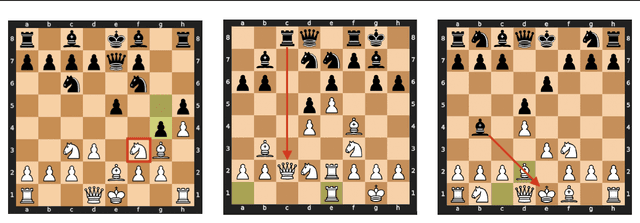
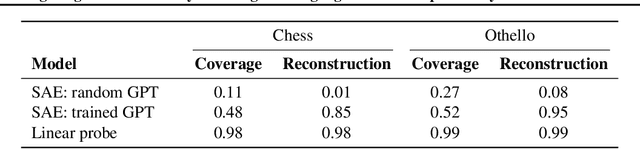
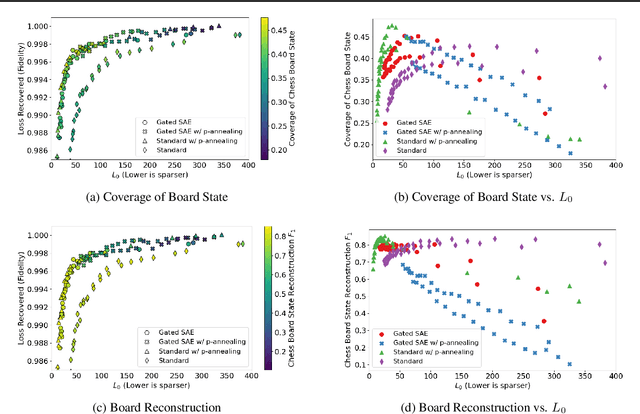
What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features that we expect good SAEs to recover. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on chess and Othello transcripts. These settings carry natural collections of interpretable features -- for example, "there is a knight on F3" -- which we leverage into $\textit{supervised}$ metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $\textit{p-annealing}$, which improves performance on prior unsupervised metrics as well as our new metrics.
Eliciting Latent Predictions from Transformers with the Tuned Lens
Mar 15, 2023We analyze transformers from the perspective of iterative inference, seeking to understand how model predictions are refined layer by layer. To do so, we train an affine probe for each block in a frozen pretrained model, making it possible to decode every hidden state into a distribution over the vocabulary. Our method, the tuned lens, is a refinement of the earlier "logit lens" technique, which yielded useful insights but is often brittle. We test our method on various autoregressive language models with up to 20B parameters, showing it to be more predictive, reliable and unbiased than the logit lens. With causal experiments, we show the tuned lens uses similar features to the model itself. We also find the trajectory of latent predictions can be used to detect malicious inputs with high accuracy. All code needed to reproduce our results can be found at https://github.com/AlignmentResearch/tuned-lens.
Researching Alignment Research: Unsupervised Analysis
Jun 06, 2022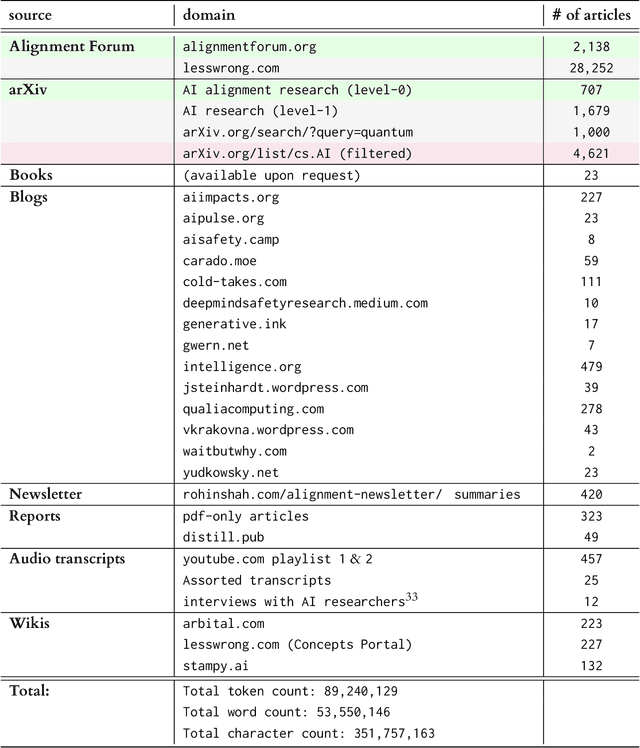
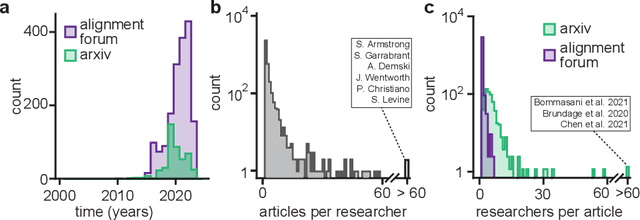
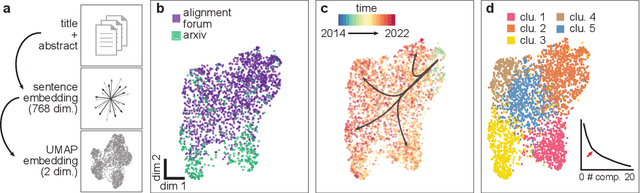

AI alignment research is the field of study dedicated to ensuring that artificial intelligence (AI) benefits humans. As machine intelligence gets more advanced, this research is becoming increasingly important. Researchers in the field share ideas across different media to speed up the exchange of information. However, this focus on speed means that the research landscape is opaque, making it difficult for young researchers to enter the field. In this project, we collected and analyzed existing AI alignment research. We found that the field is growing quickly, with several subfields emerging in parallel. We looked at the subfields and identified the prominent researchers, recurring topics, and different modes of communication in each. Furthermore, we found that a classifier trained on AI alignment research articles can detect relevant articles that we did not originally include in the dataset. We are sharing the dataset with the research community and hope to develop tools in the future that will help both established researchers and young researchers get more involved in the field.