 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Loss Kernel: A Geometric Probe for Deep Learning Interpretability
Sep 30, 2025



We introduce the loss kernel, an interpretability method for measuring similarity between data points according to a trained neural network. The kernel is the covariance matrix of per-sample losses computed under a distribution of low-loss-preserving parameter perturbations. We first validate our method on a synthetic multitask problem, showing it separates inputs by task as predicted by theory. We then apply this kernel to Inception-v1 to visualize the structure of ImageNet, and we show that the kernel's structure aligns with the WordNet semantic hierarchy. This establishes the loss kernel as a practical tool for interpretability and data attribution.
Bayesian Influence Functions for Hessian-Free Data Attribution
Sep 30, 2025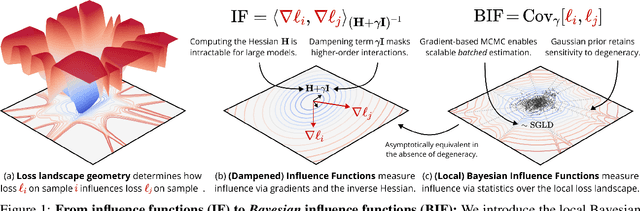


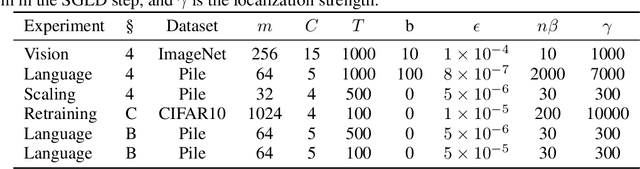
Classical influence functions face significant challenges when applied to deep neural networks, primarily due to non-invertible Hessians and high-dimensional parameter spaces. We propose the local Bayesian influence function (BIF), an extension of classical influence functions that replaces Hessian inversion with loss landscape statistics that can be estimated via stochastic-gradient MCMC sampling. This Hessian-free approach captures higher-order interactions among parameters and scales efficiently to neural networks with billions of parameters. We demonstrate state-of-the-art results on predicting retraining experiments.
Differentiation and Specialization of Attention Heads via the Refined Local Learning Coefficient
Oct 03, 2024



We introduce refined variants of the Local Learning Coefficient (LLC), a measure of model complexity grounded in singular learning theory, to study the development of internal structure in transformer language models during training. By applying these \textit{refined LLCs} (rLLCs) to individual components of a two-layer attention-only transformer, we gain novel insights into the progressive differentiation and specialization of attention heads. Our methodology reveals how attention heads differentiate into distinct functional roles over the course of training, analyzes the types of data these heads specialize to process, and discovers a previously unidentified multigram circuit. These findings demonstrate that rLLCs provide a principled, quantitative toolkit for \textit{developmental interpretability}, which aims to understand models through their evolution across the learning process. More broadly, this work takes a step towards establishing the correspondence between data distributional structure, geometric properties of the loss landscape, learning dynamics, and emergent computational structures in neural networks.
Estimating the Local Learning Coefficient at Scale
Feb 06, 2024



The \textit{local learning coefficient} (LLC) is a principled way of quantifying model complexity, originally derived in the context of Bayesian statistics using singular learning theory (SLT). Several methods are known for numerically estimating the local learning coefficient, but so far these methods have not been extended to the scale of modern deep learning architectures or data sets. Using a method developed in {\tt arXiv:2308.12108 [stat.ML]} we empirically show how the LLC may be measured accurately and self-consistently for deep linear networks (DLNs) up to 100M parameters. We also show that the estimated LLC has the rescaling invariance that holds for the theoretical quantity.
Eliciting Latent Predictions from Transformers with the Tuned Lens
Mar 15, 2023



We analyze transformers from the perspective of iterative inference, seeking to understand how model predictions are refined layer by layer. To do so, we train an affine probe for each block in a frozen pretrained model, making it possible to decode every hidden state into a distribution over the vocabulary. Our method, the tuned lens, is a refinement of the earlier "logit lens" technique, which yielded useful insights but is often brittle. We test our method on various autoregressive language models with up to 20B parameters, showing it to be more predictive, reliable and unbiased than the logit lens. With causal experiments, we show the tuned lens uses similar features to the model itself. We also find the trajectory of latent predictions can be used to detect malicious inputs with high accuracy. All code needed to reproduce our results can be found at https://github.com/AlignmentResearch/tuned-lens.