 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-Play with Large Language Models
May 25, 2023As dialogue agents become increasingly human-like in their performance, it is imperative that we develop effective ways to describe their behaviour in high-level terms without falling into the trap of anthropomorphism. In this paper, we foreground the concept of role-play. Casting dialogue agent behaviour in terms of role-play allows us to draw on familiar folk psychological terms, without ascribing human characteristics to language models they in fact lack. Two important cases of dialogue agent behaviour are addressed this way, namely (apparent) deception and (apparent) self-awareness.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Researching Alignment Research: Unsupervised Analysis
Jun 06, 2022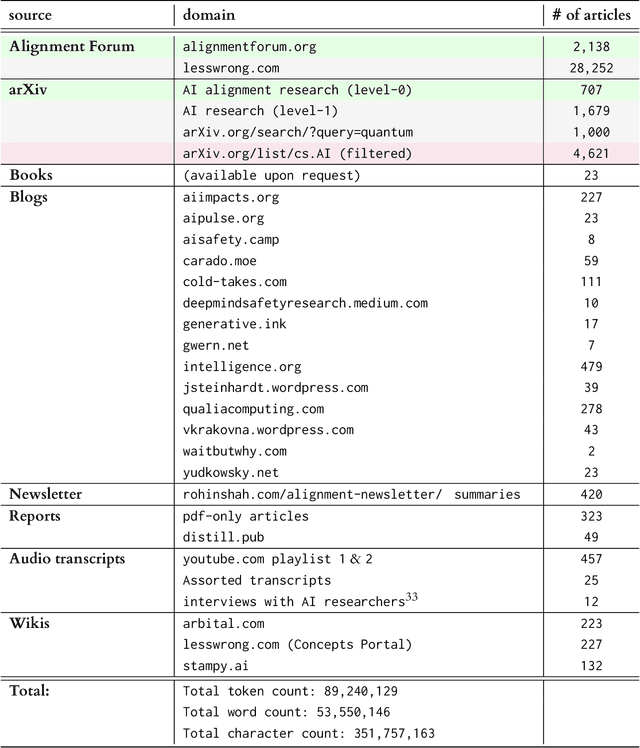
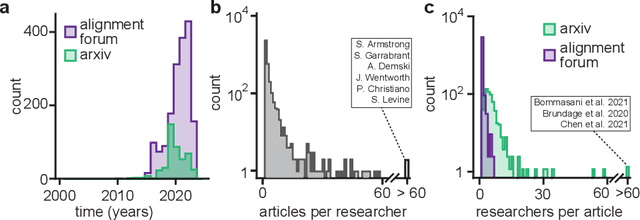
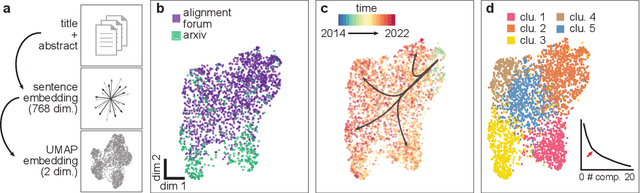

AI alignment research is the field of study dedicated to ensuring that artificial intelligence (AI) benefits humans. As machine intelligence gets more advanced, this research is becoming increasingly important. Researchers in the field share ideas across different media to speed up the exchange of information. However, this focus on speed means that the research landscape is opaque, making it difficult for young researchers to enter the field. In this project, we collected and analyzed existing AI alignment research. We found that the field is growing quickly, with several subfields emerging in parallel. We looked at the subfields and identified the prominent researchers, recurring topics, and different modes of communication in each. Furthermore, we found that a classifier trained on AI alignment research articles can detect relevant articles that we did not originally include in the dataset. We are sharing the dataset with the research community and hope to develop tools in the future that will help both established researchers and young researchers get more involved in the field.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022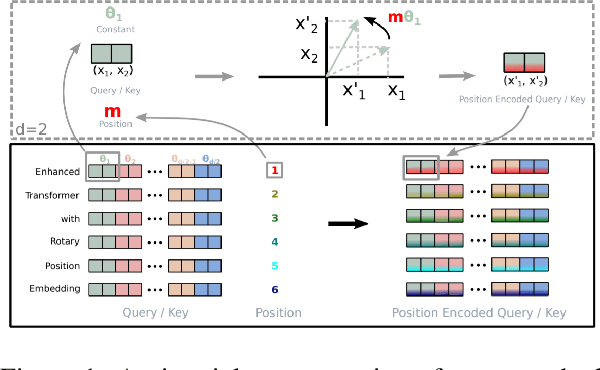
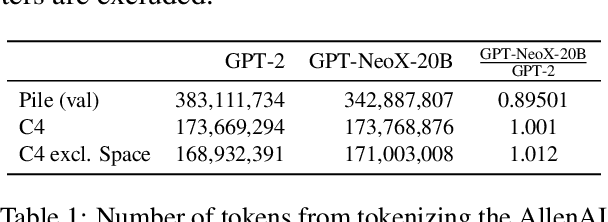
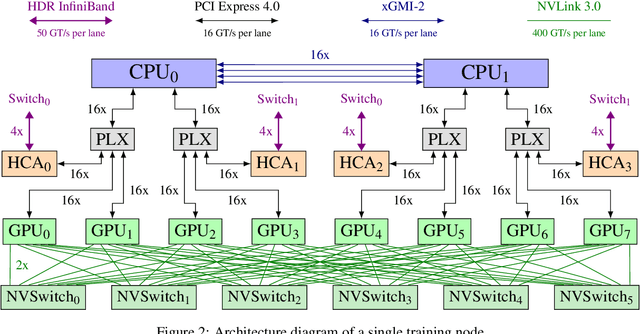

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
Feb 15, 2021
Prevailing methods for mapping large generative language models to supervised tasks may fail to sufficiently probe models' novel capabilities. Using GPT-3 as a case study, we show that 0-shot prompts can significantly outperform few-shot prompts. We suggest that the function of few-shot examples in these cases is better described as locating an already learned task rather than meta-learning. This analysis motivates rethinking the role of prompts in controlling and evaluating powerful language models. In this work, we discuss methods of prompt programming, emphasizing the usefulness of considering prompts through the lens of natural language. We explore techniques for exploiting the capacity of narratives and cultural anchors to encode nuanced intentions and techniques for encouraging deconstruction of a problem into components before producing a verdict. Informed by this more encompassing theory of prompt programming, we also introduce the idea of a metaprompt that seeds the model to generate its own natural language prompts for a range of tasks. Finally, we discuss how these more general methods of interacting with language models can be incorporated into existing and future benchmarks and practical applications.
Multiversal views on language models
Feb 15, 2021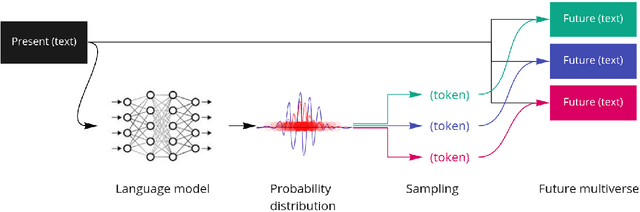

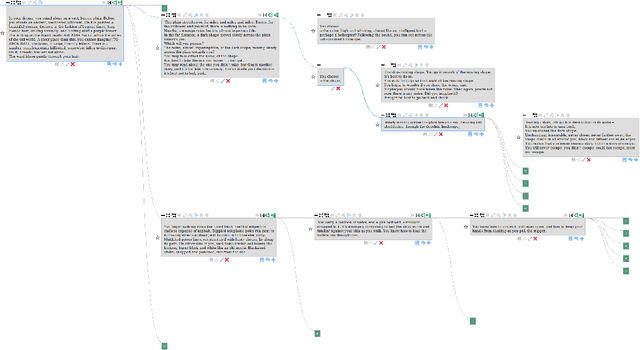

The virtuosity of language models like GPT-3 opens a new world of possibility for human-AI collaboration in writing. In this paper, we present a framework in which generative language models are conceptualized as multiverse generators. This framework also applies to human imagination and is core to how we read and write fiction. We call for exploration into this commonality through new forms of interfaces which allow humans to couple their imagination to AI to write, explore, and understand non-linear fiction. We discuss the early insights we have gained from actively pursuing this approach by developing and testing a novel multiversal GPT-3-assisted writing interface.