 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthSAEBench: Evaluating Sparse Autoencoders on Scalable Realistic Synthetic Data
Feb 16, 2026Improving Sparse Autoencoders (SAEs) requires benchmarks that can precisely validate architectural innovations. However, current SAE benchmarks on LLMs are often too noisy to differentiate architectural improvements, and current synthetic data experiments are too small-scale and unrealistic to provide meaningful comparisons. We introduce SynthSAEBench, a toolkit for generating large-scale synthetic data with realistic feature characteristics including correlation, hierarchy, and superposition, and a standardized benchmark model, SynthSAEBench-16k, enabling direct comparison of SAE architectures. Our benchmark reproduces several previously observed LLM SAE phenomena, including the disconnect between reconstruction and latent quality metrics, poor SAE probing results, and a precision-recall trade-off mediated by L0. We further use our benchmark to identify a new failure mode: Matching Pursuit SAEs exploit superposition noise to improve reconstruction without learning ground-truth features, suggesting that more expressive encoders can easily overfit. SynthSAEBench complements LLM benchmarks by providing ground-truth features and controlled ablations, enabling researchers to precisely diagnose SAE failure modes and validate architectural improvements before scaling to LLMs.
Biases in the Blind Spot: Detecting What LLMs Fail to Mention
Feb 11, 2026Large Language Models (LLMs) often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We call these *unverbalized biases*. Monitoring models via their stated reasoning is therefore unreliable, and existing bias evaluations typically require predefined categories and hand-crafted datasets. In this work, we introduce a fully automated, black-box pipeline for detecting task-specific unverbalized biases. Given a task dataset, the pipeline uses LLM autoraters to generate candidate bias concepts. It then tests each concept on progressively larger input samples by generating positive and negative variations, and applies statistical techniques for multiple testing and early stopping. A concept is flagged as an unverbalized bias if it yields statistically significant performance differences while not being cited as justification in the model's CoTs. We evaluate our pipeline across six LLMs on three decision tasks (hiring, loan approval, and university admissions). Our technique automatically discovers previously unknown biases in these models (e.g., Spanish fluency, English proficiency, writing formality). In the same run, the pipeline also validates biases that were manually identified by prior work (gender, race, religion, ethnicity). More broadly, our proposed approach provides a practical, scalable path to automatic task-specific bias discovery.
Feature Hedging: Correlated Features Break Narrow Sparse Autoencoders
May 16, 2025



It is assumed that sparse autoencoders (SAEs) decompose polysemantic activations into interpretable linear directions, as long as the activations are composed of sparse linear combinations of underlying features. However, we find that if an SAE is more narrow than the number of underlying "true features" on which it is trained, and there is correlation between features, the SAE will merge components of correlated features together, thus destroying monosemanticity. In LLM SAEs, these two conditions are almost certainly true. This phenomenon, which we call feature hedging, is caused by SAE reconstruction loss, and is more severe the narrower the SAE. In this work, we introduce the problem of feature hedging and study it both theoretically in toy models and empirically in SAEs trained on LLMs. We suspect that feature hedging may be one of the core reasons that SAEs consistently underperform supervised baselines. Finally, we use our understanding of feature hedging to propose an improved variant of matryoshka SAEs. Our work shows there remain fundamental issues with SAEs, but we are hopeful that that highlighting feature hedging will catalyze future advances that allow SAEs to achieve their full potential of interpreting LLMs at scale.
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders
Sep 25, 2024



Sparse Autoencoders (SAEs) have emerged as a promising approach to decompose the activations of Large Language Models (LLMs) into human-interpretable latents. In this paper, we pose two questions. First, to what extent do SAEs extract monosemantic and interpretable latents? Second, to what extent does varying the sparsity or the size of the SAE affect monosemanticity / interpretability? By investigating these questions in the context of a simple first-letter identification task where we have complete access to ground truth labels for all tokens in the vocabulary, we are able to provide more detail than prior investigations. Critically, we identify a problematic form of feature-splitting we call feature absorption where seemingly monosemantic latents fail to fire in cases where they clearly should. Our investigation suggests that varying SAE size or sparsity is insufficient to solve this issue, and that there are deeper conceptual issues in need of resolution.
Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024
Jul 17, 2024Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
Identifying Linear Relational Concepts in Large Language Models
Nov 15, 2023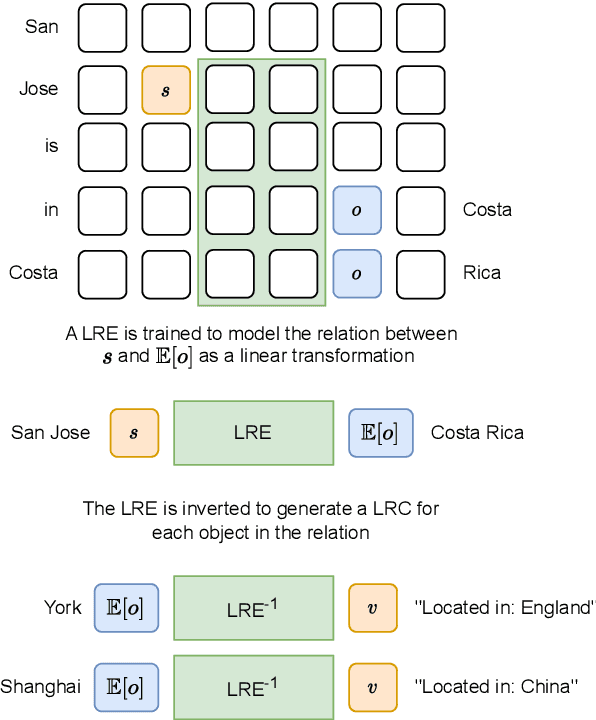


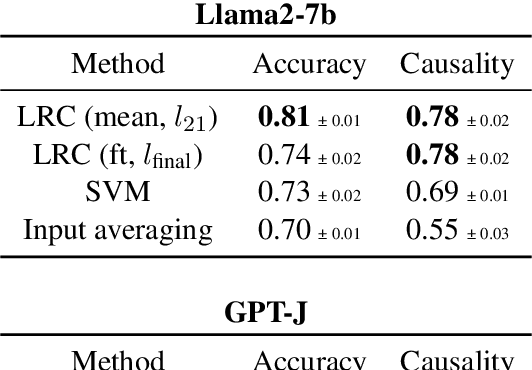
Transformer language models (LMs) have been shown to represent concepts as directions in the latent space of hidden activations. However, for any given human-interpretable concept, how can we find its direction in the latent space? We present a technique called linear relational concepts (LRC) for finding concept directions corresponding to human-interpretable concepts at a given hidden layer in a transformer LM by first modeling the relation between subject and object as a linear relational embedding (LRE). While the LRE work was mainly presented as an exercise in understanding model representations, we find that inverting the LRE while using earlier object layers results in a powerful technique to find concept directions that both work well as a classifier and causally influence model outputs.
Open-source Frame Semantic Parsing
Mar 22, 2023While the state-of-the-art for frame semantic parsing has progressed dramatically in recent years, it is still difficult for end-users to apply state-of-the-art models in practice. To address this, we present Frame Semantic Transformer, an open-source Python library which achieves near state-of-the-art performance on FrameNet 1.7, while focusing on ease-of-use. We use a T5 model fine-tuned on Propbank and FrameNet exemplars as a base, and improve performance by using FrameNet lexical units to provide hints to T5 at inference time. We enhance robustness to real-world data by using textual data augmentations during training.
Neuro-symbolic Commonsense Social Reasoning
Mar 14, 2023



Social norms underlie all human social interactions, yet formalizing and reasoning with them remains a major challenge for AI systems. We present a novel system for taking social rules of thumb (ROTs) in natural language from the Social Chemistry 101 dataset and converting them to first-order logic where reasoning is performed using a neuro-symbolic theorem prover. We accomplish this in several steps. First, ROTs are converted into Abstract Meaning Representation (AMR), which is a graphical representation of the concepts in a sentence, and align the AMR with RoBERTa embeddings. We then generate alternate simplified versions of the AMR via a novel algorithm, recombining and merging embeddings for added robustness against different wordings of text, and incorrect AMR parses. The AMR is then converted into first-order logic, and is queried with a neuro-symbolic theorem prover. The goal of this paper is to develop and evaluate a neuro-symbolic method which performs explicit reasoning about social situations in a logical form.