 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Linear Relational Concepts in Large Language Models
Paper and Code
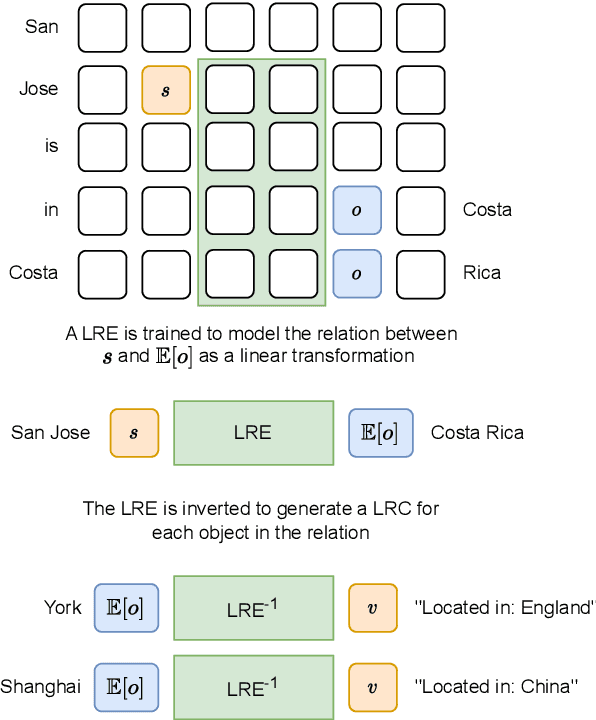


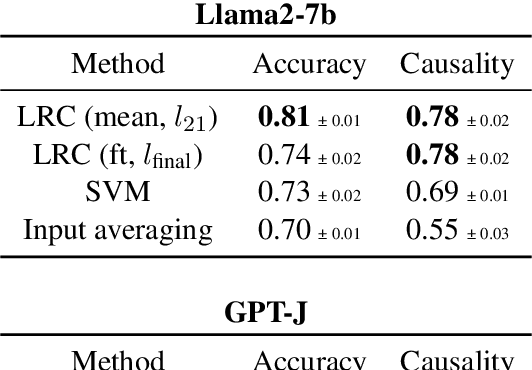
Transformer language models (LMs) have been shown to represent concepts as directions in the latent space of hidden activations. However, for any given human-interpretable concept, how can we find its direction in the latent space? We present a technique called linear relational concepts (LRC) for finding concept directions corresponding to human-interpretable concepts at a given hidden layer in a transformer LM by first modeling the relation between subject and object as a linear relational embedding (LRE). While the LRE work was mainly presented as an exercise in understanding model representations, we find that inverting the LRE while using earlier object layers results in a powerful technique to find concept directions that both work well as a classifier and causally influence model outputs.