 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024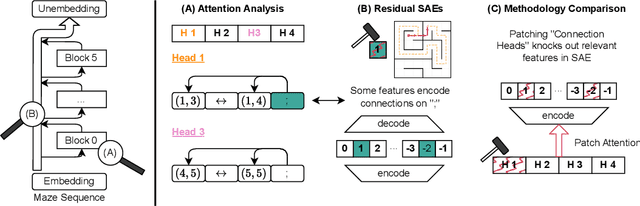



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.
Structured World Representations in Maze-Solving Transformers
Dec 05, 2023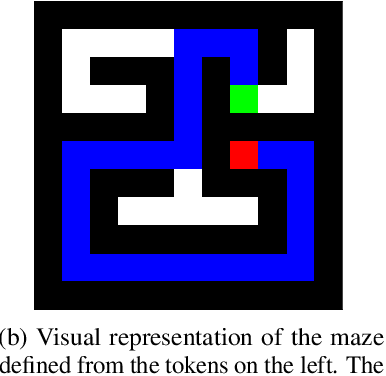
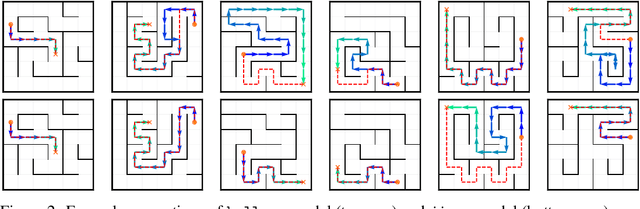

Transformer models underpin many recent advances in practical machine learning applications, yet understanding their internal behavior continues to elude researchers. Given the size and complexity of these models, forming a comprehensive picture of their inner workings remains a significant challenge. To this end, we set out to understand small transformer models in a more tractable setting: that of solving mazes. In this work, we focus on the abstractions formed by these models and find evidence for the consistent emergence of structured internal representations of maze topology and valid paths. We demonstrate this by showing that the residual stream of only a single token can be linearly decoded to faithfully reconstruct the entire maze. We also find that the learned embeddings of individual tokens have spatial structure. Furthermore, we take steps towards deciphering the circuity of path-following by identifying attention heads (dubbed $\textit{adjacency heads}$), which are implicated in finding valid subsequent tokens.
A Configurable Library for Generating and Manipulating Maze Datasets
Sep 19, 2023



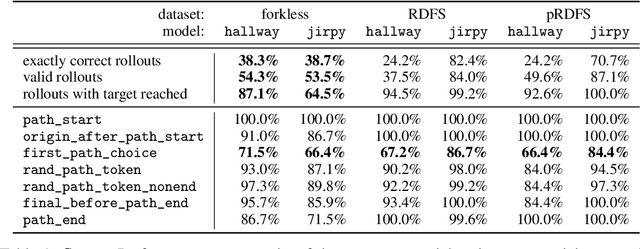
Understanding how machine learning models respond to distributional shifts is a key research challenge. Mazes serve as an excellent testbed due to varied generation algorithms offering a nuanced platform to simulate both subtle and pronounced distributional shifts. To enable systematic investigations of model behavior on out-of-distribution data, we present $\texttt{maze-dataset}$, a comprehensive library for generating, processing, and visualizing datasets consisting of maze-solving tasks. With this library, researchers can easily create datasets, having extensive control over the generation algorithm used, the parameters fed to the algorithm of choice, and the filters that generated mazes must satisfy. Furthermore, it supports multiple output formats, including rasterized and text-based, catering to convolutional neural networks and autoregressive transformer models. These formats, along with tools for visualizing and converting between them, ensure versatility and adaptability in research applications.
Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
Jul 28, 2022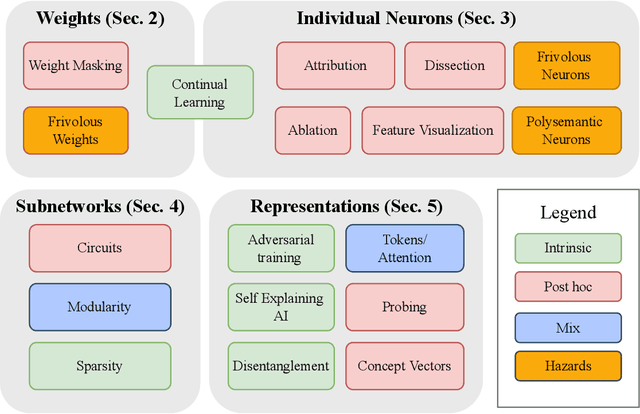
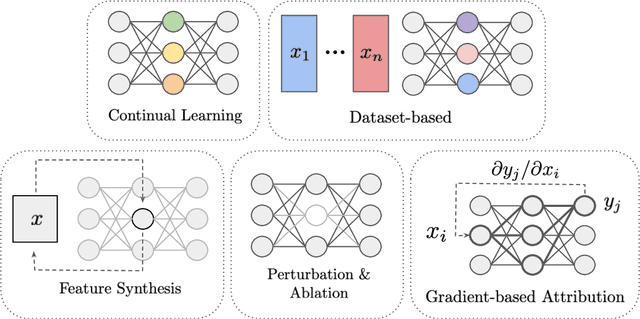
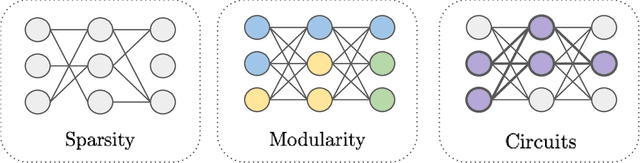

The last decade of machine learning has seen drastic increases in scale and capabilities, and deep neural networks (DNNs) are increasingly being deployed across a wide range of domains. However, the inner workings of DNNs are generally difficult to understand, raising concerns about the safety of using these systems without a rigorous understanding of how they function. In this survey, we review literature on techniques for interpreting the inner components of DNNs, which we call "inner" interpretability methods. Specifically, we review methods for interpreting weights, neurons, subnetworks, and latent representations with a focus on how these techniques relate to the goal of designing safer, more trustworthy AI systems. We also highlight connections between interpretability and work in modularity, adversarial robustness, continual learning, network compression, and studying the human visual system. Finally, we discuss key challenges and argue for future work in interpretability for AI safety that focuses on diagnostics, benchmarking, and robustness.