 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT, But Backwards: Exactly Inverting Language Model Outputs
Jul 02, 2025While existing auditing techniques attempt to identify potential unwanted behaviours in large language models (LLMs), we address the complementary forensic problem of reconstructing the exact input that led to an existing LLM output - enabling post-incident analysis and potentially the detection of fake output reports. We formalize exact input reconstruction as a discrete optimisation problem with a unique global minimum and introduce SODA, an efficient gradient-based algorithm that operates on a continuous relaxation of the input search space with periodic restarts and parameter decay. Through comprehensive experiments on LLMs ranging in size from 33M to 3B parameters, we demonstrate that SODA significantly outperforms existing approaches. We succeed in fully recovering 79.5% of shorter out-of-distribution inputs from next-token logits, without a single false positive, but struggle to extract private information from the outputs of longer (15+ token) input sequences. This suggests that standard deployment practices may currently provide adequate protection against malicious use of our method. Our code is available at https://doi.org/10.5281/zenodo.15539879.
Worst-Case Symbolic Constraints Analysis and Generalisation with Large Language Models
Jun 09, 2025Large language models (LLMs) have been successfully applied to a variety of coding tasks, including code generation, completion, and repair. However, more complex symbolic reasoning tasks remain largely unexplored by LLMs. This paper investigates the capacity of LLMs to reason about worst-case executions in programs through symbolic constraints analysis, aiming to connect LLMs and symbolic reasoning approaches. Specifically, we define and address the problem of worst-case symbolic constraints analysis as a measure to assess the comprehension of LLMs. We evaluate the performance of existing LLMs on this novel task and further improve their capabilities through symbolic reasoning-guided fine-tuning, grounded in SMT (Satisfiability Modulo Theories) constraint solving and supported by a specially designed dataset of symbolic constraints. Experimental results show that our solver-aligned model, WARP-1.0-3B, consistently surpasses size-matched and even much larger baselines, demonstrating that a 3B LLM can recover the very constraints that pin down an algorithm's worst-case behaviour through reinforcement learning methods. These findings suggest that LLMs are capable of engaging in deeper symbolic reasoning, supporting a closer integration between neural network-based learning and formal methods for rigorous program analysis.
SAFLITE: Fuzzing Autonomous Systems via Large Language Models
Dec 25, 2024



Fuzz testing effectively uncovers software vulnerabilities; however, it faces challenges with Autonomous Systems (AS) due to their vast search spaces and complex state spaces, which reflect the unpredictability and complexity of real-world environments. This paper presents a universal framework aimed at improving the efficiency of fuzz testing for AS. At its core is SaFliTe, a predictive component that evaluates whether a test case meets predefined safety criteria. By leveraging the large language model (LLM) with information about the test objective and the AS state, SaFliTe assesses the relevance of each test case. We evaluated SaFliTe by instantiating it with various LLMs, including GPT-3.5, Mistral-7B, and Llama2-7B, and integrating it into four fuzz testing tools: PGFuzz, DeepHyperion-UAV, CAMBA, and TUMB. These tools are designed specifically for testing autonomous drone control systems, such as ArduPilot, PX4, and PX4-Avoidance. The experimental results demonstrate that, compared to PGFuzz, SaFliTe increased the likelihood of selecting operations that triggered bug occurrences in each fuzzing iteration by an average of 93.1\%. Additionally, after integrating SaFliTe, the ability of DeepHyperion-UAV, CAMBA, and TUMB to generate test cases that caused system violations increased by 234.5\%, 33.3\%, and 17.8\%, respectively. The benchmark for this evaluation was sourced from a UAV Testing Competition.
Transformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024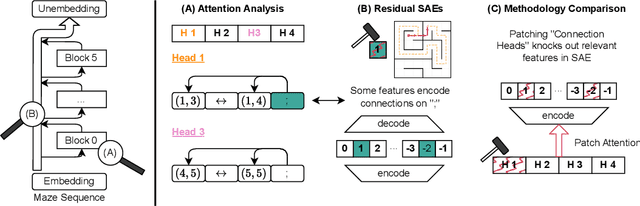



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.