 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Surgical Activation Steering via Generative Causal Mediation
Feb 17, 2026Where should we intervene in a language model (LM) to control behaviors that are diffused across many tokens of a long-form response? We introduce Generative Causal Mediation (GCM), a procedure for selecting model components, e.g., attention heads, to steer a binary concept (e.g., talk in verse vs. talk in prose) from contrastive long-form responses. In GCM, we first construct a dataset of contrasting inputs and responses. Then, we quantify how individual model components mediate the contrastive concept and select the strongest mediators for steering. We evaluate GCM on three tasks--refusal, sycophancy, and style transfer--across three language models. GCM successfully localizes concepts expressed in long-form responses and consistently outperforms correlational probe-based baselines when steering with a sparse set of attention heads. Together, these results demonstrate that GCM provides an effective approach for localizing and controlling the long-form responses of LMs.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Disjoint Processing Mechanisms of Hierarchical and Linear Grammars in Large Language Models
Jan 15, 2025



All natural languages are structured hierarchically. In humans, this structural restriction is neurologically coded: when two grammars are presented with identical vocabularies, brain areas responsible for language processing are only sensitive to hierarchical grammars. Using large language models (LLMs), we investigate whether such functionally distinct hierarchical processing regions can arise solely from exposure to large-scale language distributions. We generate inputs using English, Italian, Japanese, or nonce words, varying the underlying grammars to conform to either hierarchical or linear/positional rules. Using these grammars, we first observe that language models show distinct behaviors on hierarchical versus linearly structured inputs. Then, we find that the components responsible for processing hierarchical grammars are distinct from those that process linear grammars; we causally verify this in ablation experiments. Finally, we observe that hierarchy-selective components are also active on nonce grammars; this suggests that hierarchy sensitivity is not tied to meaning, nor in-distribution inputs.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
Human Detection of Political Deepfakes across Transcripts, Audio, and Video
Feb 25, 2022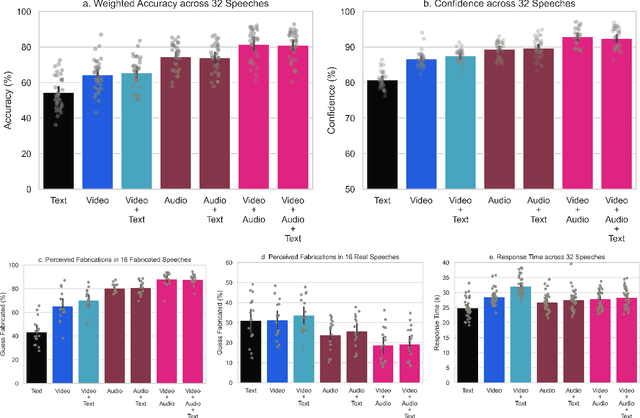

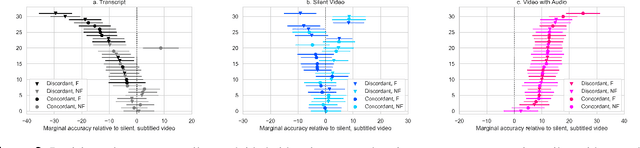
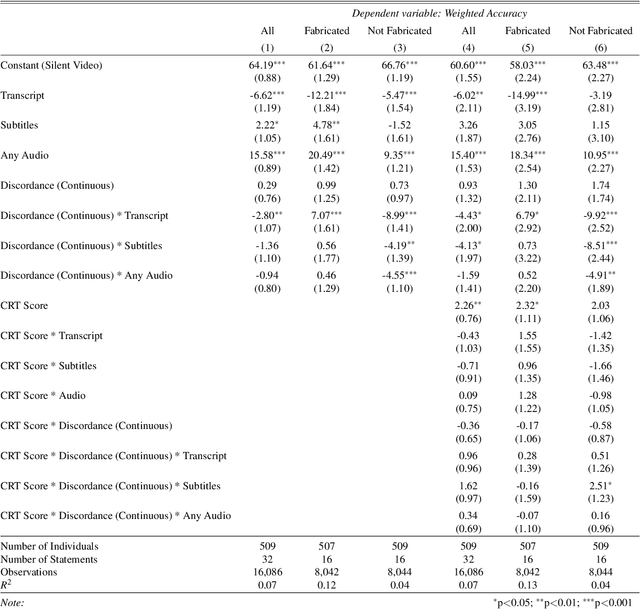
Recent advances in technology for hyper-realistic visual effects provoke the concern that deepfake videos of political speeches will soon be visually indistinguishable from authentic video recordings. Yet there exists little empirical research on how audio-visual information influences people's susceptibility to fall for political misinformation. The conventional wisdom in the field of communication research predicts that people will fall for fake news more often when the same version of a story is presented as a video as opposed to text. However, audio-visual manipulations often leave distortions that some but not all people may pick up on. Here, we evaluate how communication modalities influence people's ability to discern real political speeches from fabrications based on a randomized experiment with 5,727 participants who provide 61,792 truth discernment judgments. We show participants soundbites from political speeches that are randomly assigned to appear using permutations of text, audio, and video modalities. We find that communication modalities mediate discernment accuracy: participants are more accurate on video with audio than silent video, and more accurate on silent video than text transcripts. Likewise, we find participants rely more on how something is said (the audio-visual cues) rather than what is said (the speech content itself). However, political speeches that do not match public perceptions of politicians' beliefs reduce participants' reliance on visual cues. In particular, we find that reflective reasoning moderates the degree to which participants consider visual information: low performance on the Cognitive Reflection Test is associated with an underreliance on visual cues and an overreliance on what is said.
Invertable Frowns: Video-to-Video Facial Emotion Translation
Sep 16, 2021
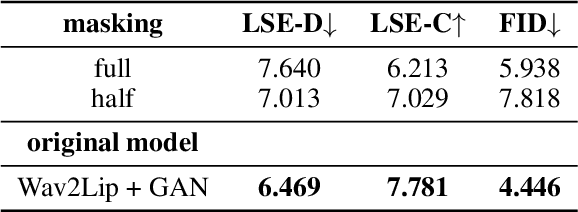

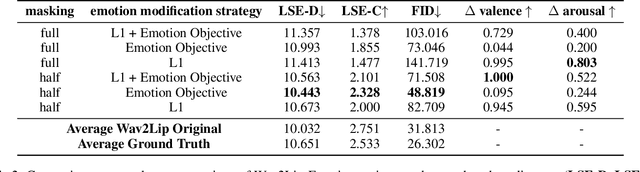
We present Wav2Lip-Emotion, a video-to-video translation architecture that modifies facial expressions of emotion in videos of speakers. Previous work modifies emotion in images, uses a single image to produce a video with animated emotion, or puppets facial expressions in videos with landmarks from a reference video. However, many use cases such as modifying an actor's performance in post-production, coaching individuals to be more animated speakers, or touching up emotion in a teleconference require a video-to-video translation approach. We explore a method to maintain speakers' lip movements, identity, and pose while translating their expressed emotion. Our approach extends an existing multi-modal lip synchronization architecture to modify the speaker's emotion using L1 reconstruction and pre-trained emotion objectives. We also propose a novel automated emotion evaluation approach and corroborate it with a user study. These find that we succeed in modifying emotion while maintaining lip synchronization. Visual quality is somewhat diminished, with a trade off between greater emotion modification and visual quality between model variants. Nevertheless, we demonstrate (1) that facial expressions of emotion can be modified with nothing other than L1 reconstruction and pre-trained emotion objectives and (2) that our automated emotion evaluation approach aligns with human judgements.
Physically-Consistent Generative Adversarial Networks for Coastal Flood Visualization
May 05, 2021
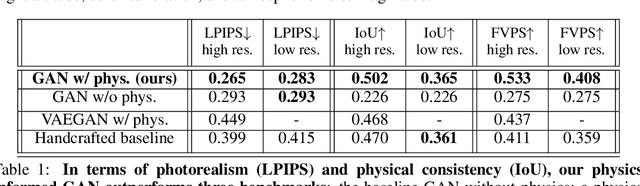
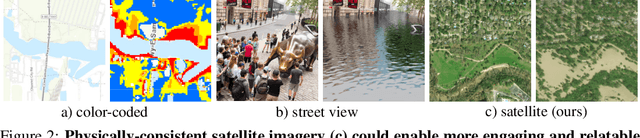
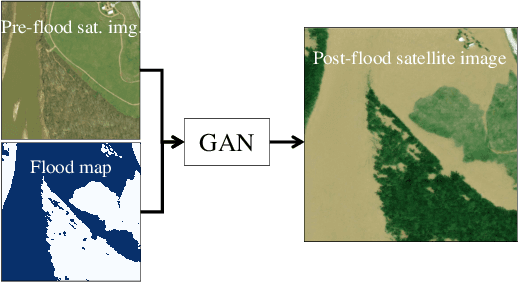
As climate change increases the intensity of natural disasters, society needs better tools for adaptation. Floods, for example, are the most frequent natural disaster, and better tools for flood risk communication could increase the support for flood-resilient infrastructure development. Our work aims to enable more visual communication of large-scale climate impacts via visualizing the output of coastal flood models as satellite imagery. We propose the first deep learning pipeline to ensure physical-consistency in synthetic visual satellite imagery. We advanced a state-of-the-art GAN called pix2pixHD, such that it produces imagery that is physically-consistent with the output of an expert-validated storm surge model (NOAA SLOSH). By evaluating the imagery relative to physics-based flood maps, we find that our proposed framework outperforms baseline models in both physical-consistency and photorealism. We envision our work to be the first step towards a global visualization of how climate change shapes our landscape. Continuing on this path, we show that the proposed pipeline generalizes to visualize arctic sea ice melt. We also publish a dataset of over 25k labelled image-pairs to study image-to-image translation in Earth observation.