 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrash to Treasure: Using text-to-image models to inform the design of physical artefacts
Feb 01, 2023Text-to-image generative models have recently exploded in popularity and accessibility. Yet so far, use of these models in creative tasks that bridge the 2D digital world and the creation of physical artefacts has been understudied. We conduct a pilot study to investigate if and how text-to-image models can be used to assist in upstream tasks within the creative process, such as ideation and visualization, prior to a sculpture-making activity. Thirty participants selected sculpture-making materials and generated three images using the Stable Diffusion text-to-image generator, each with text prompts of their choice, with the aim of informing and then creating a physical sculpture. The majority of participants (23/30) reported that the generated images informed their sculptures, and 28/30 reported interest in using text-to-image models to help them in a creative task in the future. We identify several prompt engineering strategies and find that a participant's prompting strategy relates to their stage in the creative process. We discuss how our findings can inform support for users at different stages of the design process and for using text-to-image models for physical artefact design.
Invertable Frowns: Video-to-Video Facial Emotion Translation
Sep 16, 2021
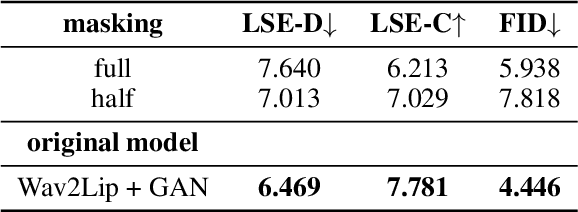

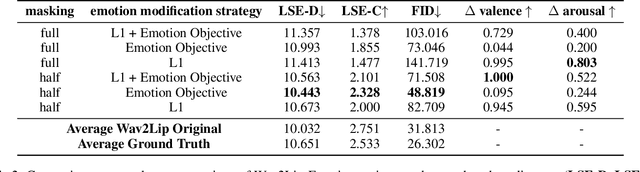
We present Wav2Lip-Emotion, a video-to-video translation architecture that modifies facial expressions of emotion in videos of speakers. Previous work modifies emotion in images, uses a single image to produce a video with animated emotion, or puppets facial expressions in videos with landmarks from a reference video. However, many use cases such as modifying an actor's performance in post-production, coaching individuals to be more animated speakers, or touching up emotion in a teleconference require a video-to-video translation approach. We explore a method to maintain speakers' lip movements, identity, and pose while translating their expressed emotion. Our approach extends an existing multi-modal lip synchronization architecture to modify the speaker's emotion using L1 reconstruction and pre-trained emotion objectives. We also propose a novel automated emotion evaluation approach and corroborate it with a user study. These find that we succeed in modifying emotion while maintaining lip synchronization. Visual quality is somewhat diminished, with a trade off between greater emotion modification and visual quality between model variants. Nevertheless, we demonstrate (1) that facial expressions of emotion can be modified with nothing other than L1 reconstruction and pre-trained emotion objectives and (2) that our automated emotion evaluation approach aligns with human judgements.