 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
Paper and Code

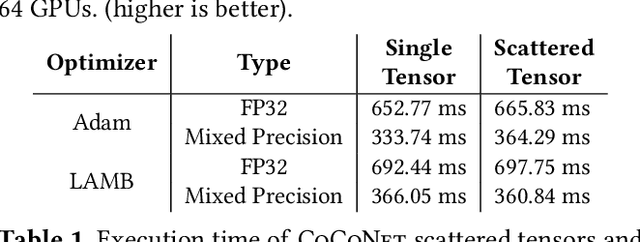

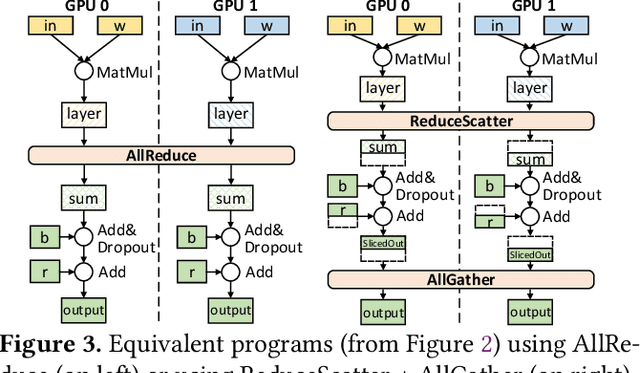
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.