 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Graph Transformer Networks with Graph-based Techniques
Jun 16, 2021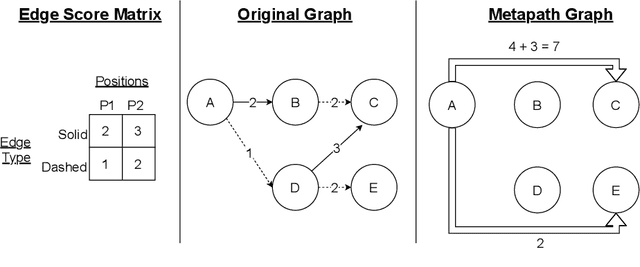
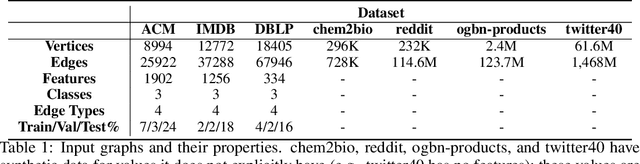
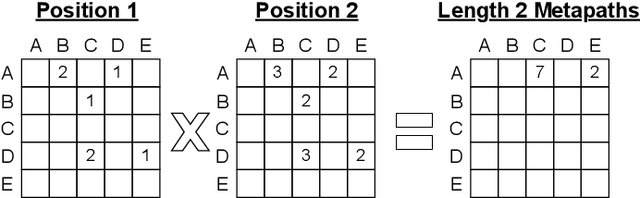
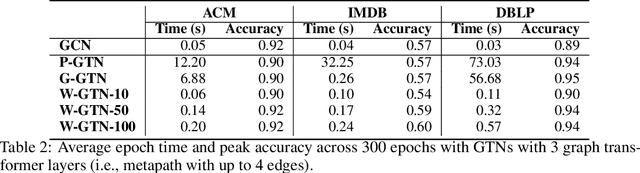
Graph transformer networks (GTN) are a variant of graph convolutional networks (GCN) that are targeted to heterogeneous graphs in which nodes and edges have associated type information that can be exploited to improve inference accuracy. GTNs learn important metapaths in the graph, create weighted edges for these metapaths, and use the resulting graph in a GCN. Currently, the only available implementation of GTNs uses dense matrix multiplication to find metapaths. Unfortunately, the space overhead of this approach can be large, so in practice it is used only for small graphs. In addition, the matrix-based implementation is not fine-grained enough to use random-walk based methods to optimize metapath finding. In this paper, we present a graph-based formulation and implementation of the GTN metapath finding problem. This graph-based formulation has two advantages over the matrix-based approach. First, it is more space efficient than the original GTN implementation and more compute-efficient for metapath sizes of practical interest. Second, it permits us to implement a sampling method that reduces the number of metapaths that must be enumerated, allowing the implementation to be used for larger graphs and larger metapath sizes. Experimental results show that our implementation is $6.5\times$ faster than the original GTN implementation on average for a metapath length of 4, and our sampling implementation is $155\times$ faster on average than this implementation without compromising on the accuracy of the GTN.
Distributed Word2Vec using Graph Analytics Frameworks
Sep 08, 2019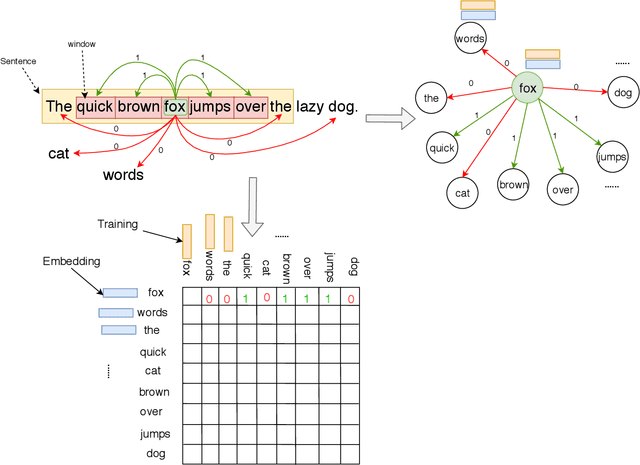
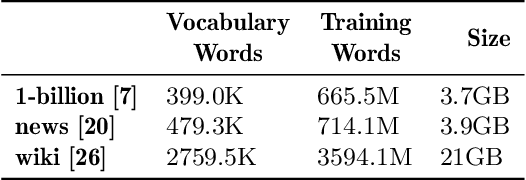
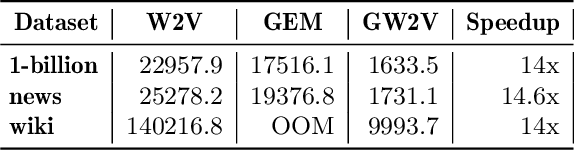
Word embeddings capture semantic and syntactic similarities of words, represented as vectors. Word2Vec is a popular implementation of word embeddings; it takes as input a large corpus of text and learns a model that maps unique words in that corpus to other contextually relevant words. After training, Word2Vec's internal vector representation of words in the corpus map unique words to a vector space, which are then used in many downstream tasks. Training these models requires significant computational resources (training time often measured in days) and is difficult to parallelize. Most word embedding training uses stochastic gradient descent (SGD), an "inherently" sequential algorithm where at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing SGD do not honor these dependencies and thus potentially suffer poor convergence. This paper introduces GraphWord2Vec, a distributedWord2Vec algorithm which formulates the Word2Vec training process as a distributed graph problem and thus leverage state-of-the-art distributed graph analytics frameworks such as D-Galois and Gemini that scale to large distributed clusters. GraphWord2Vec also demonstrates how to use model combiners to honor data dependencies in SGD and thus scale without giving up convergence. We will show that GraphWord2Vec has linear scalability up to 32 machines converging as fast as a sequential run in terms of epochs, thus reducing training time by 14x.