 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Open-World Specification Mining via Unsupervised Learning
Apr 27, 2019


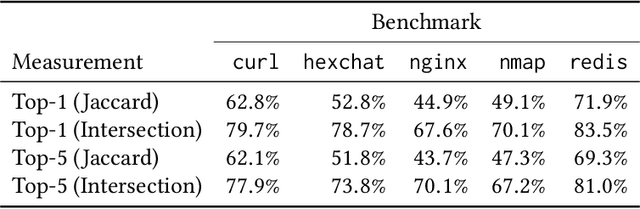
Many programming tasks require using both domain-specific code and well-established patterns (such as routines concerned with file IO). Together, several small patterns combine to create complex interactions. This compounding effect, mixed with domain-specific idiosyncrasies, creates a challenging environment for fully automatic specification inference. Mining specifications in this environment, without the aid of rule templates, user-directed feedback, or predefined API surfaces, is a major challenge. We call this challenge Open-World Specification Mining. In this paper, we present a framework for mining specifications and usage patterns in an Open-World setting. We design this framework to be miner-agnostic and instead focus on disentangling complex and noisy API interactions. To evaluate our framework, we introduce a benchmark of 71 clusters extracted from five open-source projects. Using this dataset, we show that interesting clusters can be recovered, in a fully automatic way, by leveraging unsupervised learning in the form of word embeddings. Once clusters have been recovered, the challenge of Open-World Specification Mining is simplified and any trace-based mining technique can be applied. In addition, we provide a comprehensive evaluation of three word-vector learners to showcase the value of sub-word information for embeddings learned in the software-engineering domain.