 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonyCell: Automating Single-Cell Perturbation Modeling under Semantic and Distribution Shifts
Mar 02, 2026Single-cell perturbation studies face dual heterogeneity bottlenecks: (i) semantic heterogeneity--identical biological concepts encoded under incompatible metadata schemas across datasets; and (ii) statistical heterogeneity--distribution shifts from biological variation demanding dataset-specific inductive biases. We propose HarmonyCell, an end-to-end agent framework resolving each challenge through a dedicated mechanism: an LLM-driven Semantic Unifier autonomously maps disparate metadata into a canonical interface without manual intervention; and an adaptive Monte Carlo Tree Search engine operates over a hierarchical action space to synthesize architectures with optimal statistical inductive biases for distribution shifts. Evaluated across diverse perturbation tasks under both semantic and distribution shifts, HarmonyCell achieves a 95% valid execution rate on heterogeneous input datasets (versus 0% for general agents) while matching or even exceeding expert-designed baselines in rigorous out-of-distribution evaluations. This dual-track orchestration enables scalable automatic virtual cell modeling without dataset-specific engineering.
Is Centralized Training with Decentralized Execution Framework Centralized Enough for MARL?
May 27, 2023


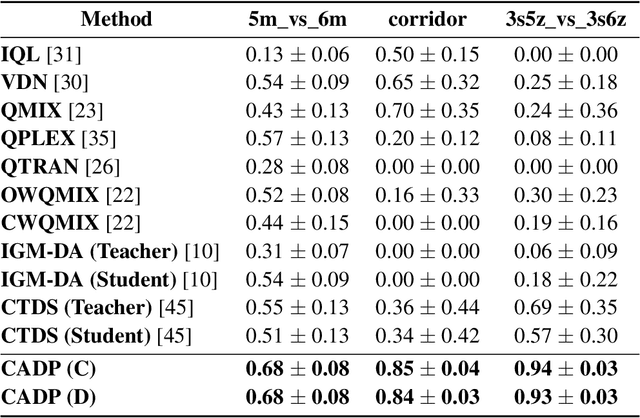
Centralized Training with Decentralized Execution (CTDE) has recently emerged as a popular framework for cooperative Multi-Agent Reinforcement Learning (MARL), where agents can use additional global state information to guide training in a centralized way and make their own decisions only based on decentralized local policies. Despite the encouraging results achieved, CTDE makes an independence assumption on agent policies, which limits agents to adopt global cooperative information from each other during centralized training. Therefore, we argue that existing CTDE methods cannot fully utilize global information for training, leading to an inefficient joint-policy exploration and even suboptimal results. In this paper, we introduce a novel Centralized Advising and Decentralized Pruning (CADP) framework for multi-agent reinforcement learning, that not only enables an efficacious message exchange among agents during training but also guarantees the independent policies for execution. Firstly, CADP endows agents the explicit communication channel to seek and take advices from different agents for more centralized training. To further ensure the decentralized execution, we propose a smooth model pruning mechanism to progressively constraint the agent communication into a closed one without degradation in agent cooperation capability. Empirical evaluations on StarCraft II micromanagement and Google Research Football benchmarks demonstrate that the proposed framework achieves superior performance compared with the state-of-the-art counterparts. Our code will be made publicly available.
An Interactive Insight Identification and Annotation Framework for Power Grid Pixel Maps using DenseU-Hierarchical VAE
May 22, 2019
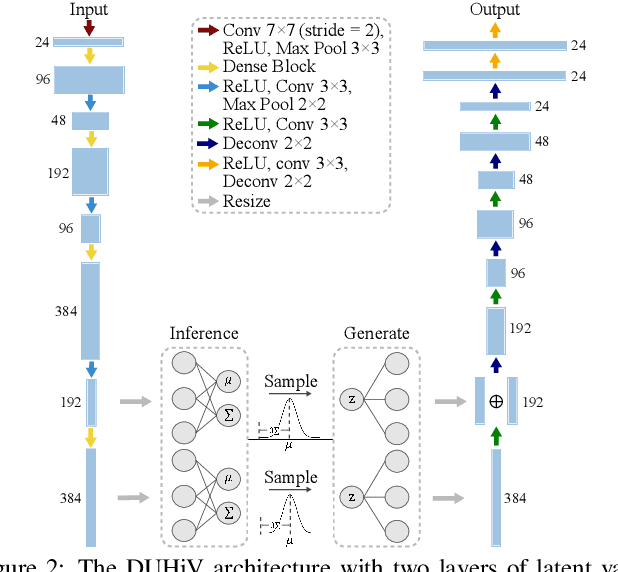


Insights in power grid pixel maps (PGPMs) refer to important facility operating states and unexpected changes in the power grid. Identifying insights helps analysts understand the collaboration of various parts of the grid so that preventive and correct operations can be taken to avoid potential accidents. Existing solutions for identifying insights in PGPMs are performed manually, which may be laborious and expertise-dependent. In this paper, we propose an interactive insight identification and annotation framework by leveraging an enhanced variational autoencoder (VAE). In particular, a new architecture, DenseU-Hierarchical VAE (DUHiV), is designed to learn representations from large-sized PGPMs, which achieves a significantly tighter evidence lower bound (ELBO) than existing Hierarchical VAEs with a Multilayer Perceptron architecture. Our approach supports modulating the derived representations in an interactive visual interface, discover potential insights and create multi-label annotations. Evaluations using real-world PGPMs datasets show that our framework outperforms the baseline models in identifying and annotating insights.
Deep-learning Based Modeling of Fault Detachment Stability for Power Grid
May 17, 2018The project intends to model the stability of power system with a deep learning algorithm to the problem, aiming to delay the removal of the fault. The so-called "fail-delay cut-off" refers to the occurrence of N-1 backup protection action on the backbone network of the system, resulting in longer time for the removal of the fault. In practice, through the analysis and calculation of a large number of online data, we have found that the N-1 failure system of the main protection action will not be unstable, which is also a guarantee of the operation mode arrangement. In the case of the N-1 backup protection action, there is an approximately 2.5% probability that the system will be destabilized. Therefore, research is needed to improve the operating arrangement.