 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Centralized Training with Decentralized Execution Framework Centralized Enough for MARL?
Paper and Code



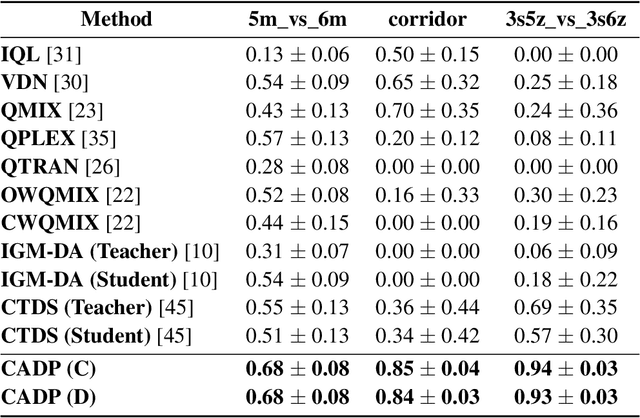
Centralized Training with Decentralized Execution (CTDE) has recently emerged as a popular framework for cooperative Multi-Agent Reinforcement Learning (MARL), where agents can use additional global state information to guide training in a centralized way and make their own decisions only based on decentralized local policies. Despite the encouraging results achieved, CTDE makes an independence assumption on agent policies, which limits agents to adopt global cooperative information from each other during centralized training. Therefore, we argue that existing CTDE methods cannot fully utilize global information for training, leading to an inefficient joint-policy exploration and even suboptimal results. In this paper, we introduce a novel Centralized Advising and Decentralized Pruning (CADP) framework for multi-agent reinforcement learning, that not only enables an efficacious message exchange among agents during training but also guarantees the independent policies for execution. Firstly, CADP endows agents the explicit communication channel to seek and take advices from different agents for more centralized training. To further ensure the decentralized execution, we propose a smooth model pruning mechanism to progressively constraint the agent communication into a closed one without degradation in agent cooperation capability. Empirical evaluations on StarCraft II micromanagement and Google Research Football benchmarks demonstrate that the proposed framework achieves superior performance compared with the state-of-the-art counterparts. Our code will be made publicly available.