 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISHIEN-MAAT: Scrollytelling visualization design for explaining Siamese Neural Network concept to non-technical users
Apr 04, 2023The past decade has witnessed rapid progress in AI research since the breakthrough in deep learning. AI technology has been applied in almost every field; therefore, technical and non-technical end-users must understand these technologies to exploit them. However existing materials are designed for experts, but non-technical users need appealing materials that deliver complex ideas in easy-to-follow steps. One notable tool that fits such a profile is scrollytelling, an approach to storytelling that provides readers with a natural and rich experience at the reader's pace, along with in-depth interactive explanations of complex concepts. Hence, this work proposes a novel visualization design for creating a scrollytelling that can effectively explain an AI concept to non-technical users. As a demonstration of our design, we created a scrollytelling to explain the Siamese Neural Network for the visual similarity matching problem. Our approach helps create a visualization valuable for a short-timeline situation like a sales pitch. The results show that the visualization based on our novel design helps improve non-technical users' perception and machine learning concept knowledge acquisition compared to traditional materials like online articles.
KD3A: Unsupervised Multi-Source Decentralized Domain Adaptation via Knowledge Distillation
Dec 08, 2020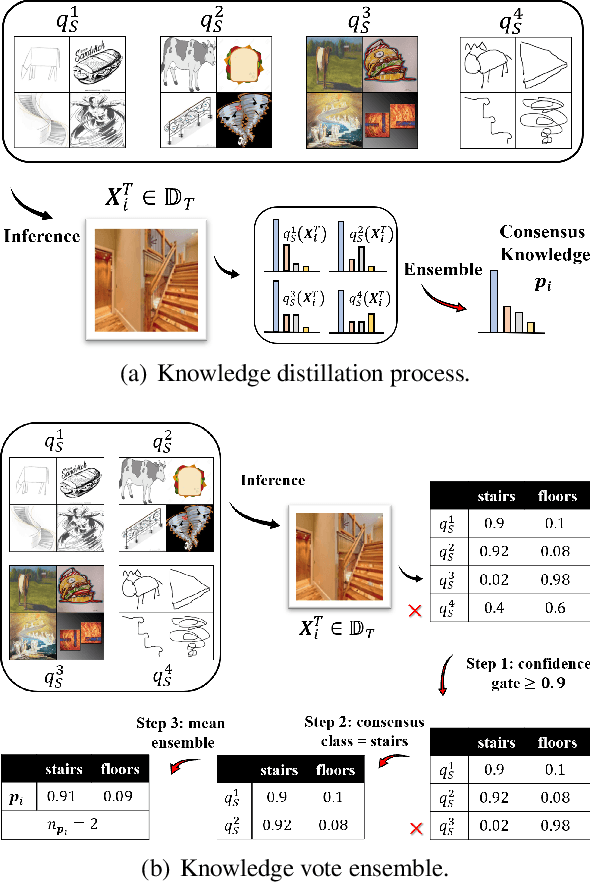
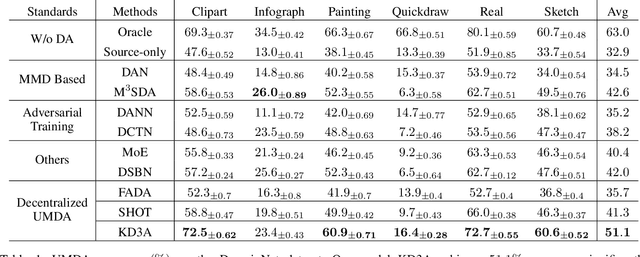

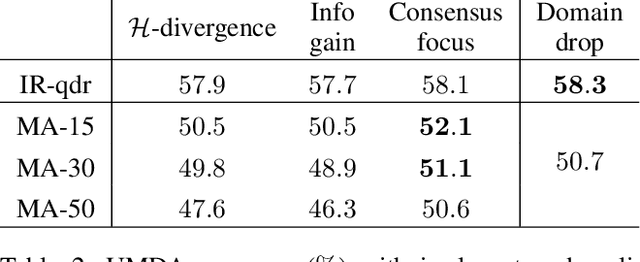
Conventional unsupervised multi-source domain adaptation (UMDA) methods assume all source domains can be accessed directly. This neglects the privacy-preserving policy, that is, all the data and computations must be kept decentralized. There exists three problems in this scenario: (1) Minimizing the domain distance requires the pairwise calculation of the data from source and target domains, which is not accessible. (2) The communication cost and privacy security limit the application of UMDA methods (e.g., the domain adversarial training). (3) Since users have no authority to check the data quality, the irrelevant or malicious source domains are more likely to appear, which causes negative transfer. In this study, we propose a privacy-preserving UMDA paradigm named Knowledge Distillation based Decentralized Domain Adaptation (KD3A), which performs domain adaptation through the knowledge distillation on models from different source domains. KD3A solves the above problems with three components: (1) A multi-source knowledge distillation method named Knowledge Vote to learn high-quality domain consensus knowledge. (2) A dynamic weighting strategy named Consensus Focus to identify both the malicious and irrelevant domains. (3) A decentralized optimization strategy for domain distance named BatchNorm MMD. The extensive experiments on DomainNet demonstrate that KD3A is robust to the negative transfer and brings a 100x reduction of communication cost compared with other decentralized UMDA methods. Moreover, our KD3A significantly outperforms state-of-the-art UMDA approaches.
SHOT-VAE: Semi-supervised Deep Generative Models With Label-aware ELBO Approximations
Dec 08, 2020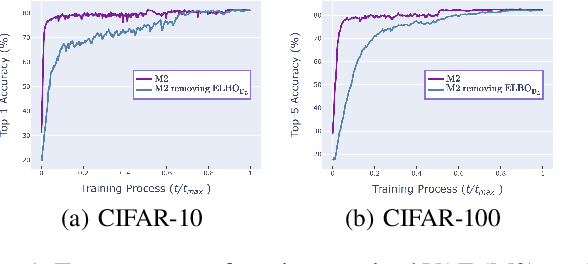
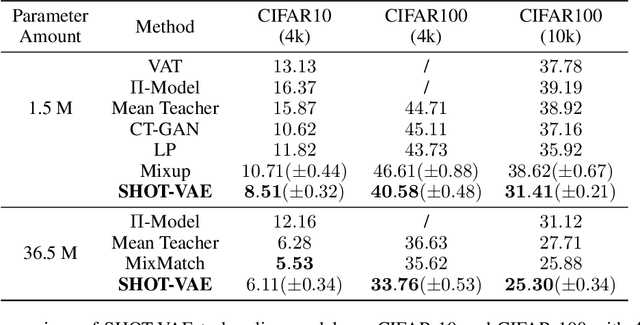
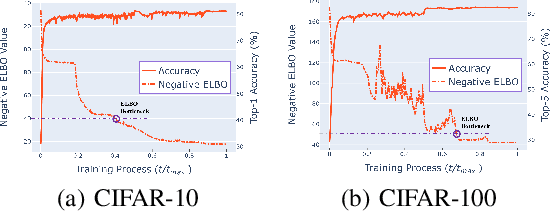

Semi-supervised variational autoencoders (VAEs) have obtained strong results, but have also encountered the challenge that good ELBO values do not always imply accurate inference results. In this paper, we investigate and propose two causes of this problem: (1) The ELBO objective cannot utilize the label information directly. (2) A bottleneck value exists and continuing to optimize ELBO after this value will not improve inference accuracy. On the basis of the experiment results, we propose SHOT-VAE to address these problems without introducing additional prior knowledge. The SHOT-VAE offers two contributions: (1) A new ELBO approximation named smooth-ELBO that integrates the label predictive loss into ELBO. (2) An approximation based on optimal interpolation that breaks the ELBO value bottleneck by reducing the margin between ELBO and the data likelihood. The SHOT-VAE achieves good performance with a 25.30% error rate on CIFAR-100 with 10k labels and reduces the error rate to 6.11% on CIFAR-10 with 4k labels.
An Interactive Insight Identification and Annotation Framework for Power Grid Pixel Maps using DenseU-Hierarchical VAE
May 22, 2019
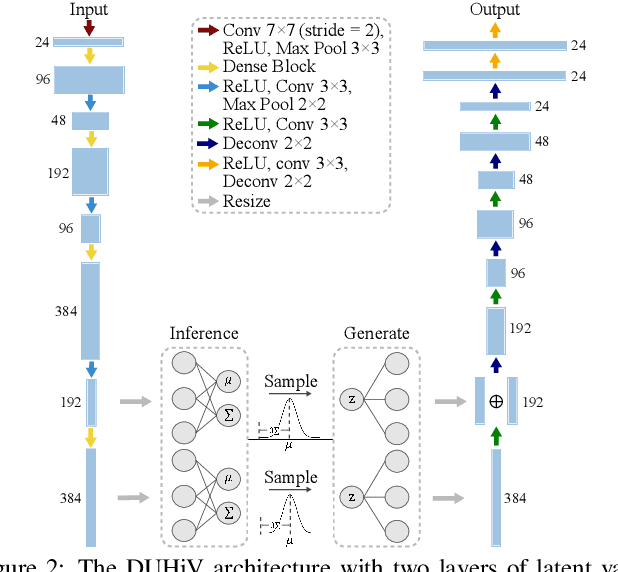


Insights in power grid pixel maps (PGPMs) refer to important facility operating states and unexpected changes in the power grid. Identifying insights helps analysts understand the collaboration of various parts of the grid so that preventive and correct operations can be taken to avoid potential accidents. Existing solutions for identifying insights in PGPMs are performed manually, which may be laborious and expertise-dependent. In this paper, we propose an interactive insight identification and annotation framework by leveraging an enhanced variational autoencoder (VAE). In particular, a new architecture, DenseU-Hierarchical VAE (DUHiV), is designed to learn representations from large-sized PGPMs, which achieves a significantly tighter evidence lower bound (ELBO) than existing Hierarchical VAEs with a Multilayer Perceptron architecture. Our approach supports modulating the derived representations in an interactive visual interface, discover potential insights and create multi-label annotations. Evaluations using real-world PGPMs datasets show that our framework outperforms the baseline models in identifying and annotating insights.