 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISHIEN-MAAT: Scrollytelling visualization design for explaining Siamese Neural Network concept to non-technical users
Apr 04, 2023The past decade has witnessed rapid progress in AI research since the breakthrough in deep learning. AI technology has been applied in almost every field; therefore, technical and non-technical end-users must understand these technologies to exploit them. However existing materials are designed for experts, but non-technical users need appealing materials that deliver complex ideas in easy-to-follow steps. One notable tool that fits such a profile is scrollytelling, an approach to storytelling that provides readers with a natural and rich experience at the reader's pace, along with in-depth interactive explanations of complex concepts. Hence, this work proposes a novel visualization design for creating a scrollytelling that can effectively explain an AI concept to non-technical users. As a demonstration of our design, we created a scrollytelling to explain the Siamese Neural Network for the visual similarity matching problem. Our approach helps create a visualization valuable for a short-timeline situation like a sales pitch. The results show that the visualization based on our novel design helps improve non-technical users' perception and machine learning concept knowledge acquisition compared to traditional materials like online articles.
Data Generation for Satellite Image Classification Using Self-Supervised Representation Learning
May 28, 2022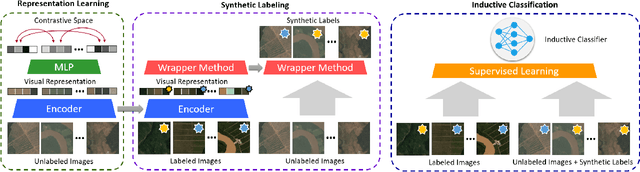
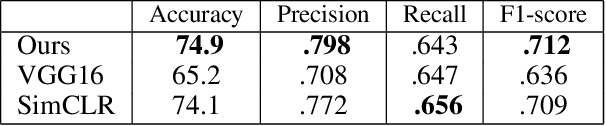


Supervised deep neural networks are the-state-of-the-art for many tasks in the remote sensing domain, against the fact that such techniques require the dataset consisting of pairs of input and label, which are rare and expensive to collect in term of both manpower and resources. On the other hand, there are abundance of raw satellite images available both for commercial and academic purposes. Hence, in this work, we tackle the insufficient labeled data problem in satellite image classification task by introducing the process based on the self-supervised learning technique to create the synthetic labels for satellite image patches. These synthetic labels can be used as the training dataset for the existing supervised learning techniques. In our experiments, we show that the models trained on the synthetic labels give similar performance to the models trained on the real labels. And in the process of creating the synthetic labels, we also obtain the visual representation vectors that are versatile and knowledge transferable.