 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Convergence or Imitation? Genre-Specific Homogeneity in LLM-Generated Chinese Literature
Mar 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in narrative generation. However, they often produce structurally homogenized stories, frequently following repetitive arrangements and combinations of plot events along with stereotypical resolutions. In this paper, we propose a novel theoretical framework for analysis by incorporating Proppian narratology and narrative functions. This framework is used to analyze the composition of narrative texts generated by LLMs to uncover their underlying narrative logic. Taking Chinese web literature as our research focus, we extend Propp's narrative theory, defining 34 narrative functions suited to modern web narrative structures. We further construct a human-annotated corpus to support the analysis of narrative structures within LLM-generated text. Experiments reveal that the primary reasons for the singular narrative logic and severe homogenization in generated texts are that current LLMs are unable to correctly comprehend the meanings of narrative functions and instead adhere to rigid narrative generation paradigms.
Efficiently Building a Domain-Specific Large Language Model from Scratch: A Case Study of a Classical Chinese Large Language Model
May 17, 2025General-purpose large language models demonstrate notable capabilities in language comprehension and generation, achieving results that are comparable to, or even surpass, human performance in many language information processing tasks. Nevertheless, when general models are applied to some specific domains, e.g., Classical Chinese texts, their effectiveness is often unsatisfactory, and fine-tuning open-source foundational models similarly struggles to adequately incorporate domain-specific knowledge. To address this challenge, this study developed a large language model, AI Taiyan, specifically designed for understanding and generating Classical Chinese. Experiments show that with a reasonable model design, data processing, foundational training, and fine-tuning, satisfactory results can be achieved with only 1.8 billion parameters. In key tasks related to Classical Chinese information processing such as punctuation, identification of allusions, explanation of word meanings, and translation between ancient and modern Chinese, this model exhibits a clear advantage over both general-purpose large models and domain-specific traditional models, achieving levels close to or surpassing human baselines. This research provides a reference for the efficient construction of specialized domain-specific large language models. Furthermore, the paper discusses the application of this model in fields such as the collation of ancient texts, dictionary editing, and language research, combined with case studies.
Beyond Agreement: Diagnosing the Rationale Alignment of Automated Essay Scoring Methods based on Linguistically-informed Counterfactuals
May 29, 2024
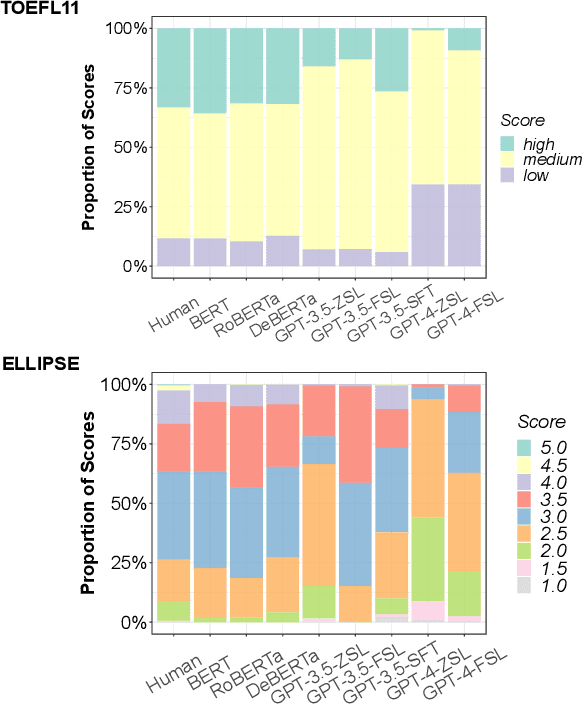
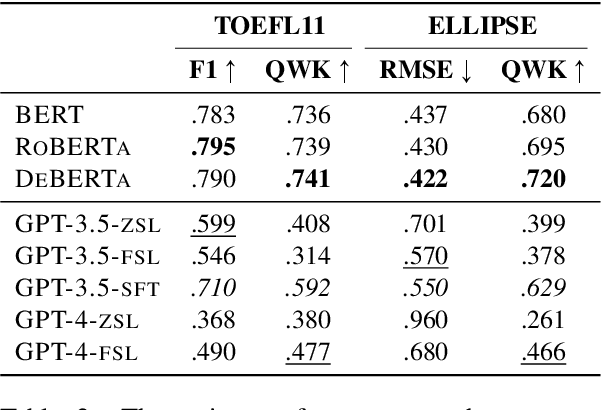
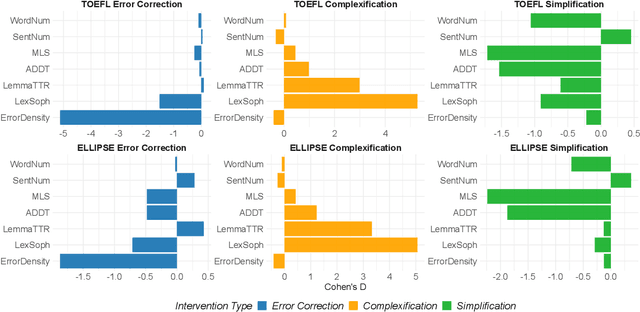
While current automated essay scoring (AES) methods show high agreement with human raters, their scoring mechanisms are not fully explored. Our proposed method, using counterfactual intervention assisted by Large Language Models (LLMs), reveals that when scoring essays, BERT-like models primarily focus on sentence-level features, while LLMs are attuned to conventions, language complexity, as well as organization, indicating a more comprehensive alignment with scoring rubrics. Moreover, LLMs can discern counterfactual interventions during feedback. Our approach improves understanding of neural AES methods and can also apply to other domains seeking transparency in model-driven decisions. The codes and data will be released at GitHub.
YACLC: A Chinese Learner Corpus with Multidimensional Annotation
Dec 30, 2021
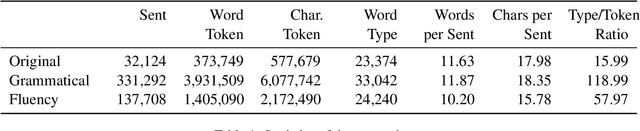
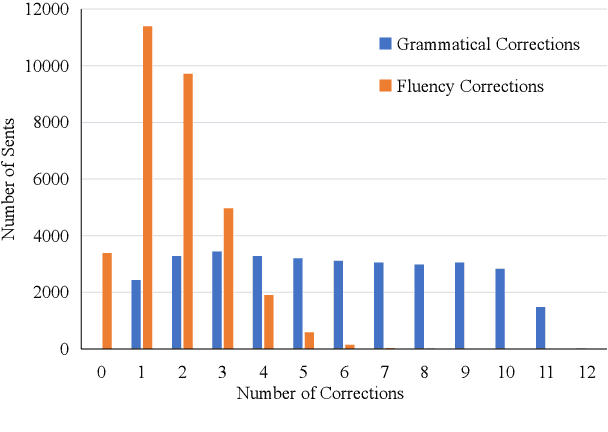
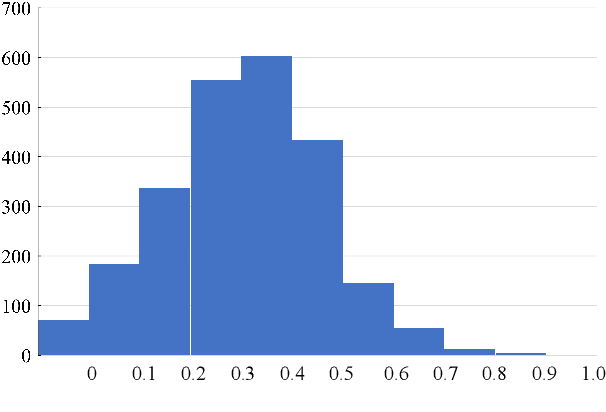
Learner corpus collects language data produced by L2 learners, that is second or foreign-language learners. This resource is of great relevance for second language acquisition research, foreign-language teaching, and automatic grammatical error correction. However, there is little focus on learner corpus for Chinese as Foreign Language (CFL) learners. Therefore, we propose to construct a large-scale, multidimensional annotated Chinese learner corpus. To construct the corpus, we first obtain a large number of topic-rich texts generated by CFL learners. Then we design an annotation scheme including a sentence acceptability score as well as grammatical error and fluency-based corrections. We build a crowdsourcing platform to perform the annotation effectively (https://yaclc.wenmind.net). We name the corpus YACLC (Yet Another Chinese Learner Corpus) and release it as part of the CUGE benchmark (http://cuge.baai.ac.cn). By analyzing the original sentences and annotations in the corpus, we found that YACLC has a considerable size and very high annotation quality. We hope this corpus can further enhance the studies on Chinese International Education and Chinese automatic grammatical error correction.
Intrinsic Knowledge Evaluation on Chinese Language Models
Nov 29, 2020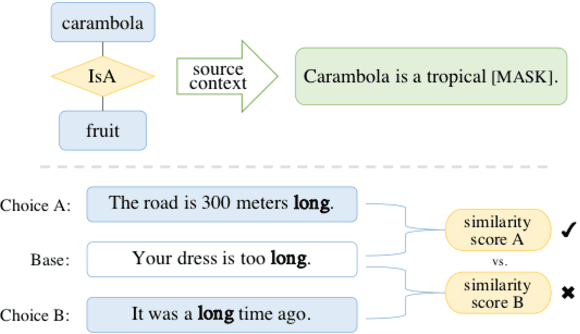

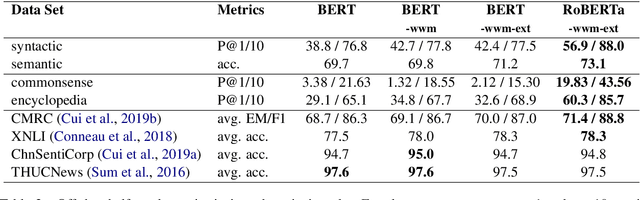
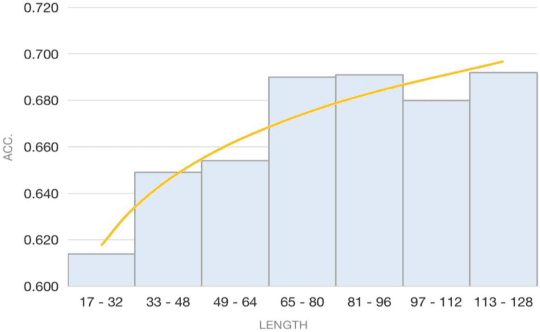
Recent NLP tasks have benefited a lot from pre-trained language models (LM) since they are able to encode knowledge of various aspects. However, current LM evaluations focus on downstream performance, hence lack to comprehensively inspect in which aspect and to what extent have they encoded knowledge. This paper addresses both queries by proposing four tasks on syntactic, semantic, commonsense, and factual knowledge, aggregating to a total of $39,308$ questions covering both linguistic and world knowledge in Chinese. Throughout experiments, our probes and knowledge data prove to be a reliable benchmark for evaluating pre-trained Chinese LMs. Our work is publicly available at https://github.com/ZhiruoWang/ChnEval.
Quantum Inspired Word Representation and Computation
Apr 08, 2020
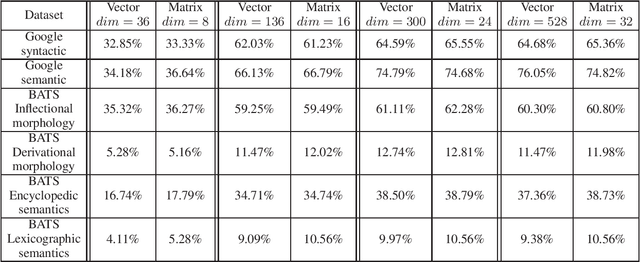
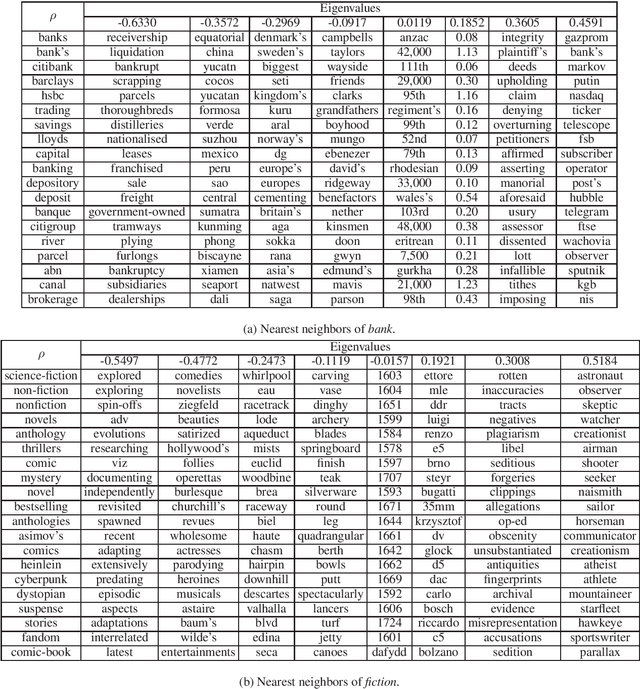
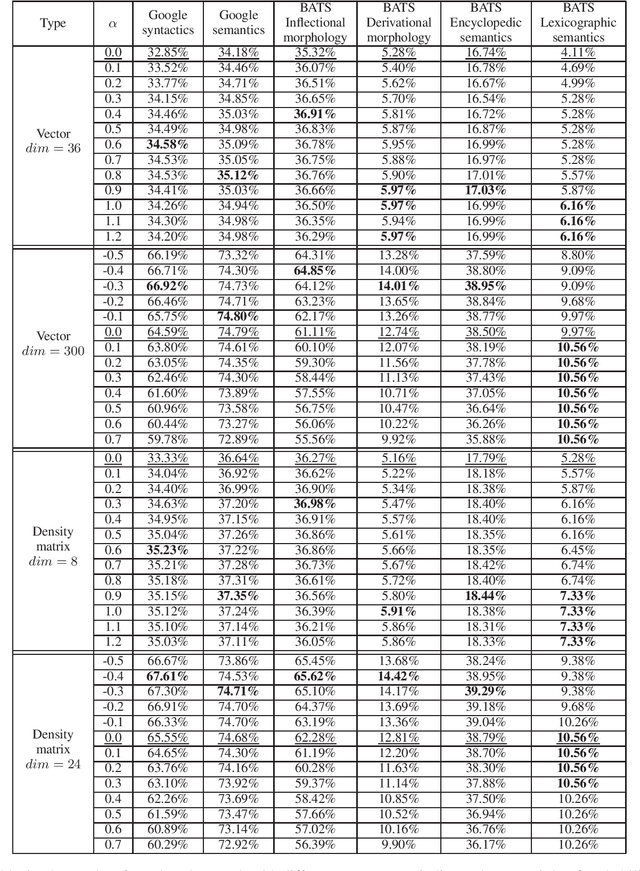
Word meaning has different aspects, while the existing word representation "compresses" these aspects into a single vector, and it needs further analysis to recover the information in different dimensions. Inspired by quantum probability, we represent words as density matrices, which are inherently capable of representing mixed states. The experiment shows that the density matrix representation can effectively capture different aspects of word meaning while maintaining comparable reliability with the vector representation. Furthermore, we propose a novel method to combine the coherent summation and incoherent summation in the computation of both vectors and density matrices. It achieves consistent improvement on word analogy task.
Self-Balanced Dropout
Aug 06, 2019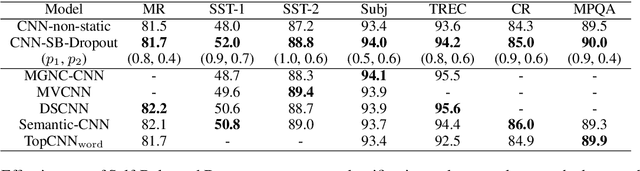
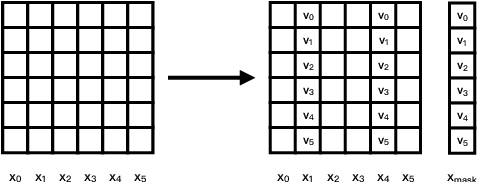
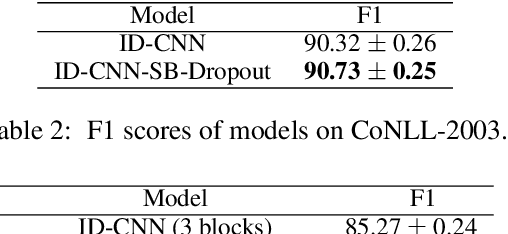
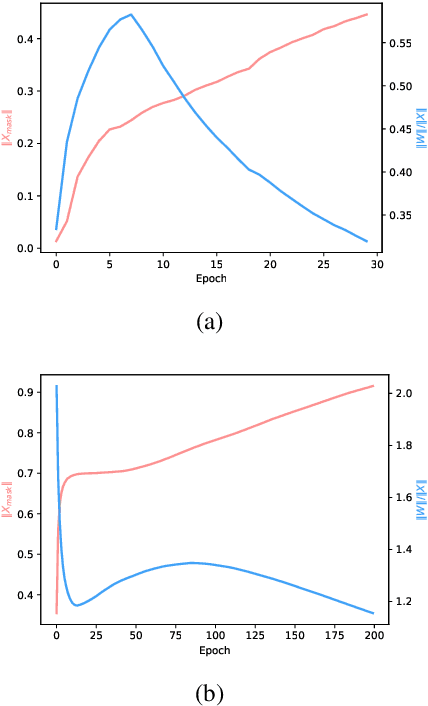
Dropout is known as an effective way to reduce overfitting via preventing co-adaptations of units. In this paper, we theoretically prove that the co-adaptation problem still exists after using dropout due to the correlations among the inputs. Based on the proof, we further propose Self-Balanced Dropout, a novel dropout method which uses a trainable variable to balance the influence of the input correlation on parameter update. We evaluate Self-Balanced Dropout on a range of tasks with both simple and complex models. The experimental results show that the mechanism can effectively solve the co-adaption problem to some extent and significantly improve the performance on all tasks.
From Random to Supervised: A Novel Dropout Mechanism Integrated with Global Information
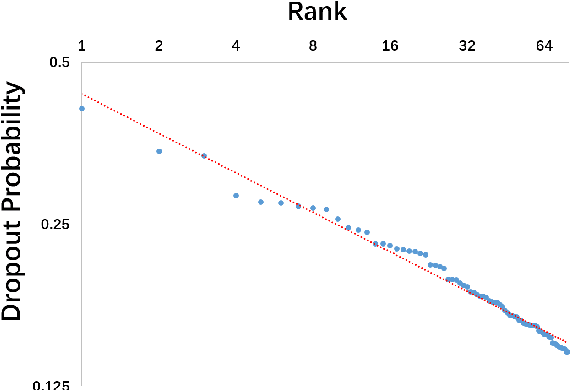
Oct 10, 2018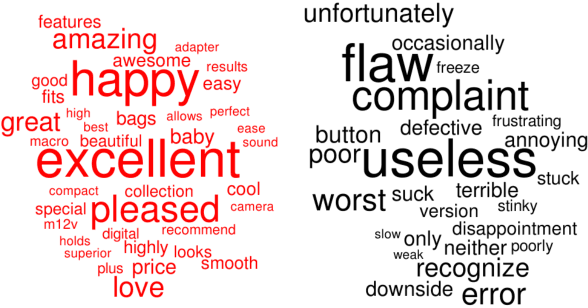
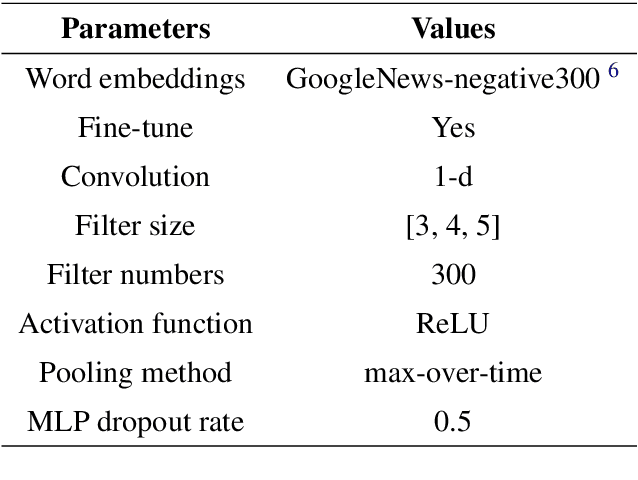
Dropout is used to avoid overfitting by randomly dropping units from the neural networks during training. Inspired by dropout, this paper presents GI-Dropout, a novel dropout method integrating with global information to improve neural networks for text classification. Unlike the traditional dropout method in which the units are dropped randomly according to the same probability, we aim to use explicit instructions based on global information of the dataset to guide the training process. With GI-Dropout, the model is supposed to pay more attention to inapparent features or patterns. Experiments demonstrate the effectiveness of the dropout with global information on seven text classification tasks, including sentiment analysis and topic classification.
Analogical Reasoning on Chinese Morphological and Semantic Relations
May 12, 2018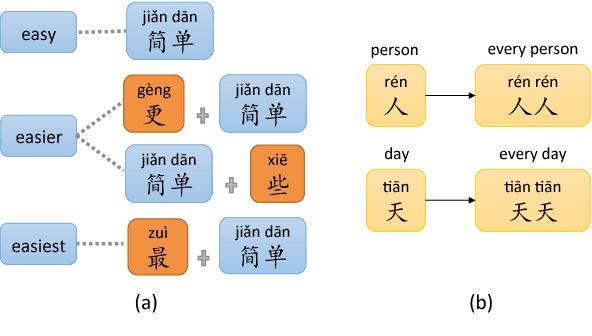
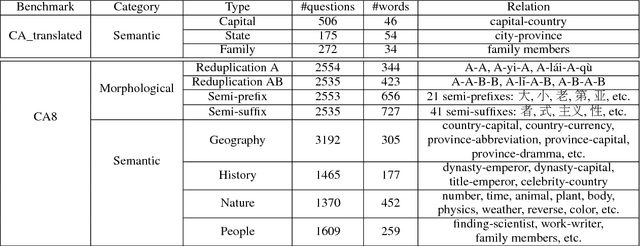
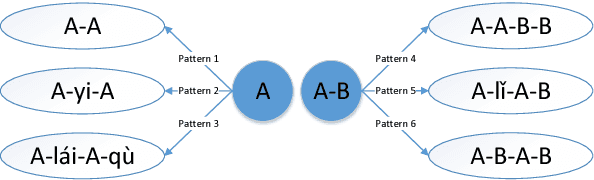

Analogical reasoning is effective in capturing linguistic regularities. This paper proposes an analogical reasoning task on Chinese. After delving into Chinese lexical knowledge, we sketch 68 implicit morphological relations and 28 explicit semantic relations. A big and balanced dataset CA8 is then built for this task, including 17813 questions. Furthermore, we systematically explore the influences of vector representations, context features, and corpora on analogical reasoning. With the experiments, CA8 is proved to be a reliable benchmark for evaluating Chinese word embeddings.