 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Knowledge Editing for Information Enrichment and Probability Promotion
Dec 22, 2024Knowledge stored in large language models requires timely updates to reflect the dynamic nature of real-world information. To update the knowledge, most knowledge editing methods focus on the low layers, since recent probes into the knowledge recall process reveal that the answer information is enriched in low layers. However, these probes only and could only reveal critical recall stages for the original answers, while the goal of editing is to rectify model's prediction for the target answers. This inconsistency indicates that both the probe approaches and the associated editing methods are deficient. To mitigate the inconsistency and identify critical editing regions, we propose a contrast-based probe approach, and locate two crucial stages where the model behavior diverges between the original and target answers: Information Enrichment in low layers and Probability Promotion in high layers. Building upon the insights, we develop the Joint knowledge Editing for information Enrichment and probability Promotion (JEEP) method, which jointly edits both the low and high layers to modify the two critical recall stages. Considering the mutual interference and growing forgetting due to dual modifications, JEEP is designed to ensure that updates to distinct regions share the same objectives and are complementary. We rigorously evaluate JEEP by editing up to thousands of facts on various models, i.e., GPT-J (6B) and LLaMA (7B), and addressing diverse editing objectives, i.e., adding factual and counterfactual knowledge. In all tested scenarios, JEEP achieves best performances, validating the effectiveness of the revealings of our probe approach and the designs of our editing method. Our code and data are available at https://github.com/Eric8932/JEEP.
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
Dec 10, 2024Answering natural language (NL) questions about tables, which is referred to as Tabular Question Answering (TQA), is important because it enables users to extract meaningful insights quickly and efficiently from structured data, bridging the gap between human language and machine-readable formats. Many of these tables originate from web sources or real-world scenarios, necessitating careful data preparation (or data prep for short) to ensure accurate answers. However, unlike traditional data prep, question-aware data prep introduces new requirements, which include tasks such as column augmentation and filtering for given questions, and question-aware value normalization or conversion. Because each of the above tasks is unique, a single model (or agent) may not perform effectively across all scenarios. In this paper, we propose AUTOPREP, a large language model (LLM)-based multi-agent framework that leverages the strengths of multiple agents, each specialized in a certain type of data prep, ensuring more accurate and contextually relevant responses. Given an NL question over a table, AUTOPREP performs data prep through three key components. Planner: Determines a logical plan, outlining a sequence of high-level operations. Programmer: Translates this logical plan into a physical plan by generating the corresponding low-level code. Executor: Iteratively executes and debugs the generated code to ensure correct outcomes. To support this multi-agent framework, we design a novel chain-of-thought reasoning mechanism for high-level operation suggestion, and a tool-augmented method for low-level code generation. Extensive experiments on real-world TQA datasets demonstrate that AUTOPREP can significantly improve the SOTA TQA solutions through question-aware data prep.
A Two-Phase Recall-and-Select Framework for Fast Model Selection
Mar 28, 2024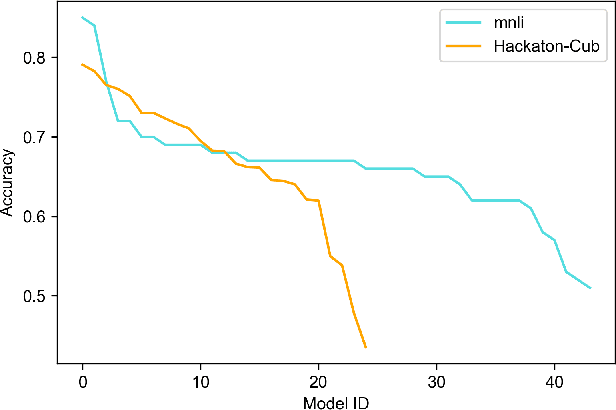
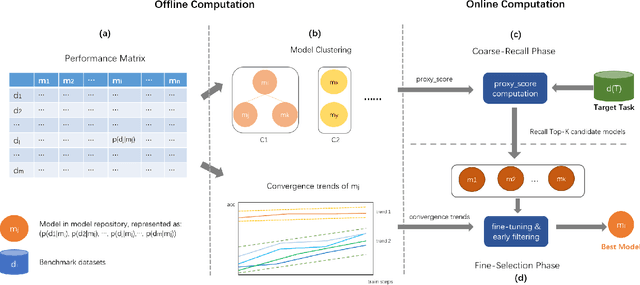
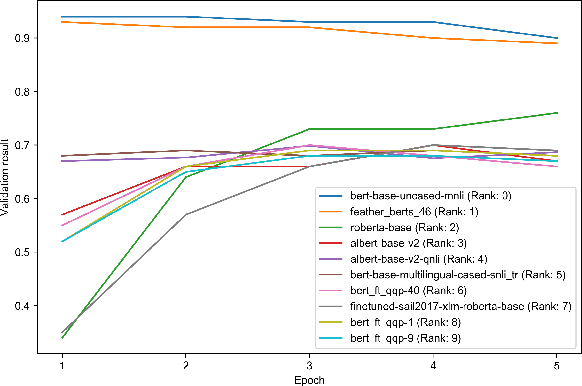

As the ubiquity of deep learning in various machine learning applications has amplified, a proliferation of neural network models has been trained and shared on public model repositories. In the context of a targeted machine learning assignment, utilizing an apt source model as a starting point typically outperforms the strategy of training from scratch, particularly with limited training data. Despite the investigation and development of numerous model selection strategies in prior work, the process remains time-consuming, especially given the ever-increasing scale of model repositories. In this paper, we propose a two-phase (coarse-recall and fine-selection) model selection framework, aiming to enhance the efficiency of selecting a robust model by leveraging the models' training performances on benchmark datasets. Specifically, the coarse-recall phase clusters models showcasing similar training performances on benchmark datasets in an offline manner. A light-weight proxy score is subsequently computed between this model cluster and the target dataset, which serves to recall a significantly smaller subset of potential candidate models in a swift manner. In the following fine-selection phase, the final model is chosen by fine-tuning the recalled models on the target dataset with successive halving. To accelerate the process, the final fine-tuning performance of each potential model is predicted by mining the model's convergence trend on the benchmark datasets, which aids in filtering lower performance models more earlier during fine-tuning. Through extensive experimentation on tasks covering natural language processing and computer vision, it has been demonstrated that the proposed methodology facilitates the selection of a high-performing model at a rate about 3x times faster than conventional baseline methods. Our code is available at https://github.com/plasware/two-phase-selection.
Cost-Effective In-Context Learning for Entity Resolution: A Design Space Exploration
Dec 07, 2023Entity resolution (ER) is an important data integration task with a wide spectrum of applications. The state-of-the-art solutions on ER rely on pre-trained language models (PLMs), which require fine-tuning on a lot of labeled matching/non-matching entity pairs. Recently, large languages models (LLMs), such as GPT-4, have shown the ability to perform many tasks without tuning model parameters, which is known as in-context learning (ICL) that facilitates effective learning from a few labeled input context demonstrations. However, existing ICL approaches to ER typically necessitate providing a task description and a set of demonstrations for each entity pair and thus have limitations on the monetary cost of interfacing LLMs. To address the problem, in this paper, we provide a comprehensive study to investigate how to develop a cost-effective batch prompting approach to ER. We introduce a framework BATCHER consisting of demonstration selection and question batching and explore different design choices that support batch prompting for ER. We also devise a covering-based demonstration selection strategy that achieves an effective balance between matching accuracy and monetary cost. We conduct a thorough evaluation to explore the design space and evaluate our proposed strategies. Through extensive experiments, we find that batch prompting is very cost-effective for ER, compared with not only PLM-based methods fine-tuned with extensive labeled data but also LLM-based methods with manually designed prompting. We also provide guidance for selecting appropriate design choices for batch prompting.
Create and Find Flatness: Building Flat Training Spaces in Advance for Continual Learning
Sep 20, 2023Catastrophic forgetting remains a critical challenge in the field of continual learning, where neural networks struggle to retain prior knowledge while assimilating new information. Most existing studies emphasize mitigating this issue only when encountering new tasks, overlooking the significance of the pre-task phase. Therefore, we shift the attention to the current task learning stage, presenting a novel framework, C&F (Create and Find Flatness), which builds a flat training space for each task in advance. Specifically, during the learning of the current task, our framework adaptively creates a flat region around the minimum in the loss landscape. Subsequently, it finds the parameters' importance to the current task based on their flatness degrees. When adapting the model to a new task, constraints are applied according to the flatness and a flat space is simultaneously prepared for the impending task. We theoretically demonstrate the consistency between the created and found flatness. In this manner, our framework not only accommodates ample parameter space for learning new tasks but also preserves the preceding knowledge of earlier tasks. Experimental results exhibit C&F's state-of-the-art performance as a standalone continual learning approach and its efficacy as a framework incorporating other methods. Our work is available at https://github.com/Eric8932/Create-and-Find-Flatness.
WavMark: Watermarking for Audio Generation
Aug 24, 2023



Recent breakthroughs in zero-shot voice synthesis have enabled imitating a speaker's voice using just a few seconds of recording while maintaining a high level of realism. Alongside its potential benefits, this powerful technology introduces notable risks, including voice fraud and speaker impersonation. Unlike the conventional approach of solely relying on passive methods for detecting synthetic data, watermarking presents a proactive and robust defence mechanism against these looming risks. This paper introduces an innovative audio watermarking framework that encodes up to 32 bits of watermark within a mere 1-second audio snippet. The watermark is imperceptible to human senses and exhibits strong resilience against various attacks. It can serve as an effective identifier for synthesized voices and holds potential for broader applications in audio copyright protection. Moreover, this framework boasts high flexibility, allowing for the combination of multiple watermark segments to achieve heightened robustness and expanded capacity. Utilizing 10 to 20-second audio as the host, our approach demonstrates an average Bit Error Rate (BER) of 0.48\% across ten common attacks, a remarkable reduction of over 2800\% in BER compared to the state-of-the-art watermarking tool. See https://aka.ms/wavmark for demos of our work.
REAL: A Representative Error-Driven Approach for Active Learning
Jul 06, 2023



Given a limited labeling budget, active learning (AL) aims to sample the most informative instances from an unlabeled pool to acquire labels for subsequent model training. To achieve this, AL typically measures the informativeness of unlabeled instances based on uncertainty and diversity. However, it does not consider erroneous instances with their neighborhood error density, which have great potential to improve the model performance. To address this limitation, we propose $REAL$, a novel approach to select data instances with $\underline{R}$epresentative $\underline{E}$rrors for $\underline{A}$ctive $\underline{L}$earning. It identifies minority predictions as \emph{pseudo errors} within a cluster and allocates an adaptive sampling budget for the cluster based on estimated error density. Extensive experiments on five text classification datasets demonstrate that $REAL$ consistently outperforms all best-performing baselines regarding accuracy and F1-macro scores across a wide range of hyperparameter settings. Our analysis also shows that $REAL$ selects the most representative pseudo errors that match the distribution of ground-truth errors along the decision boundary. Our code is publicly available at https://github.com/withchencheng/ECML_PKDD_23_Real.
Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation
Jun 15, 2023Zero-shot NL2SQL is crucial in achieving natural language to SQL that is adaptive to new environments (e.g., new databases, new linguistic phenomena or SQL structures) with zero annotated NL2SQL samples from such environments. Existing approaches either fine-tune pre-trained language models (PLMs) based on annotated data or use prompts to guide fixed large language models (LLMs) such as ChatGPT. PLMs can perform well in schema alignment but struggle to achieve complex reasoning, while LLMs is superior in complex reasoning tasks but cannot achieve precise schema alignment. In this paper, we propose a ZeroNL2SQL framework that combines the complementary advantages of PLMs and LLMs for supporting zero-shot NL2SQL. ZeroNL2SQL first uses PLMs to generate an SQL sketch via schema alignment, then uses LLMs to fill the missing information via complex reasoning. Moreover, in order to better align the generated SQL queries with values in the given database instances, we design a predicate calibration method to guide the LLM in completing the SQL sketches based on the database instances and select the optimal SQL query via an execution-based strategy. Comprehensive experiments show that ZeroNL2SQL can achieve the best zero-shot NL2SQL performance on real-world benchmarks. Specifically, ZeroNL2SQL outperforms the state-of-the-art PLM-based methods by 3.2% to 13% and exceeds LLM-based methods by 10% to 20% on execution accuracy.
ChatPipe: Orchestrating Data Preparation Program by Optimizing Human-ChatGPT Interactions
Apr 07, 2023Orchestrating a high-quality data preparation program is essential for successful machine learning (ML), but it is known to be time and effort consuming. Despite the impressive capabilities of large language models like ChatGPT in generating programs by interacting with users through natural language prompts, there are still limitations. Specifically, a user must provide specific prompts to iteratively guide ChatGPT in improving data preparation programs, which requires a certain level of expertise in programming, the dataset used and the ML task. Moreover, once a program has been generated, it is non-trivial to revisit a previous version or make changes to the program without starting the process over again. In this paper, we present ChatPipe, a novel system designed to facilitate seamless interaction between users and ChatGPT. ChatPipe provides users with effective recommendation on next data preparation operations, and guides ChatGPT to generate program for the operations. Also, ChatPipe enables users to easily roll back to previous versions of the program, which facilitates more efficient experimentation and testing. We have developed a web application for ChatPipe and prepared several real-world ML tasks from Kaggle. These tasks can showcase the capabilities of ChatPipe and enable VLDB attendees to easily experiment with our novel features to rapidly orchestrate a high-quality data preparation program.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022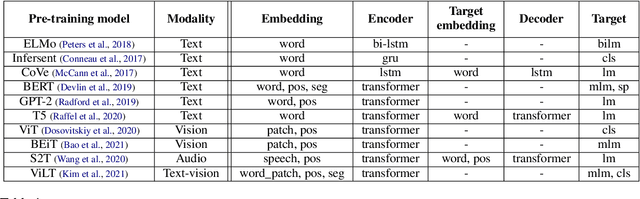
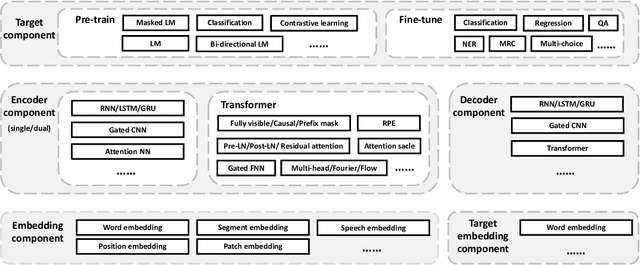
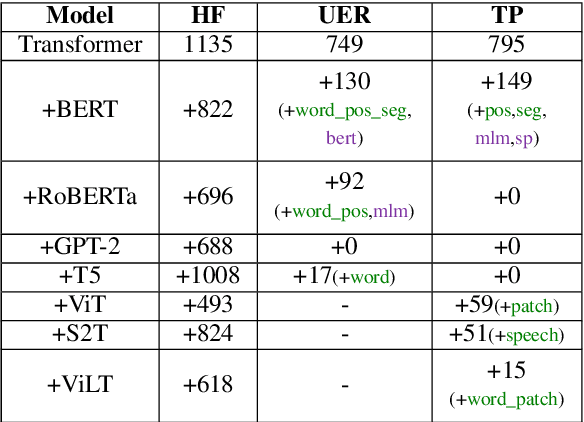
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.