 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYACLC: A Chinese Learner Corpus with Multidimensional Annotation
Dec 30, 2021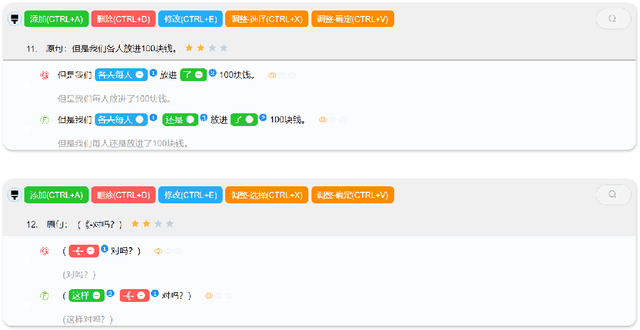
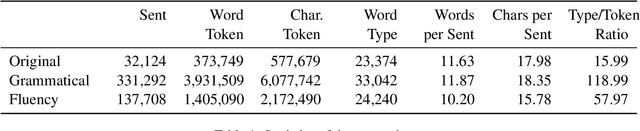
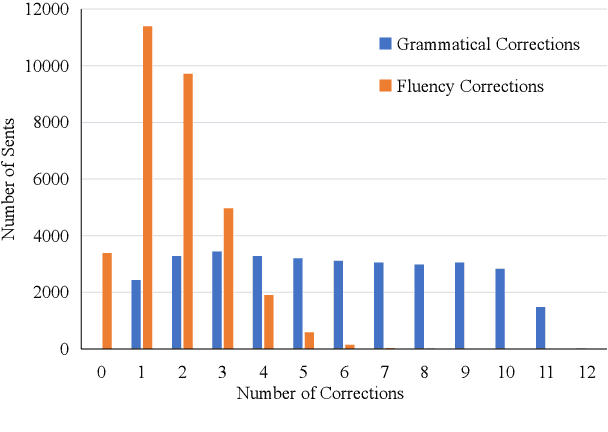
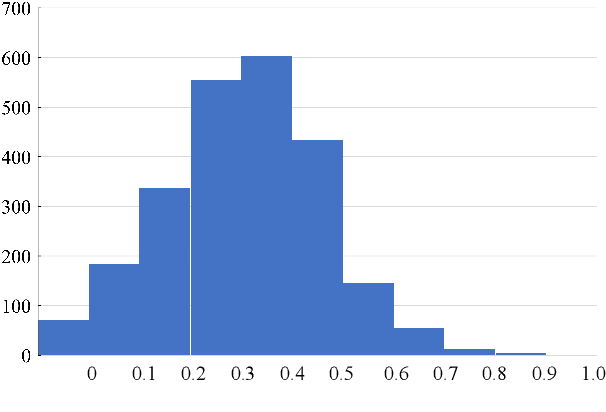
Learner corpus collects language data produced by L2 learners, that is second or foreign-language learners. This resource is of great relevance for second language acquisition research, foreign-language teaching, and automatic grammatical error correction. However, there is little focus on learner corpus for Chinese as Foreign Language (CFL) learners. Therefore, we propose to construct a large-scale, multidimensional annotated Chinese learner corpus. To construct the corpus, we first obtain a large number of topic-rich texts generated by CFL learners. Then we design an annotation scheme including a sentence acceptability score as well as grammatical error and fluency-based corrections. We build a crowdsourcing platform to perform the annotation effectively (https://yaclc.wenmind.net). We name the corpus YACLC (Yet Another Chinese Learner Corpus) and release it as part of the CUGE benchmark (http://cuge.baai.ac.cn). By analyzing the original sentences and annotations in the corpus, we found that YACLC has a considerable size and very high annotation quality. We hope this corpus can further enhance the studies on Chinese International Education and Chinese automatic grammatical error correction.