Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Agreement: Diagnosing the Rationale Alignment of Automated Essay Scoring Methods based on Linguistically-informed Counterfactuals
Paper and Code
May 29, 2024
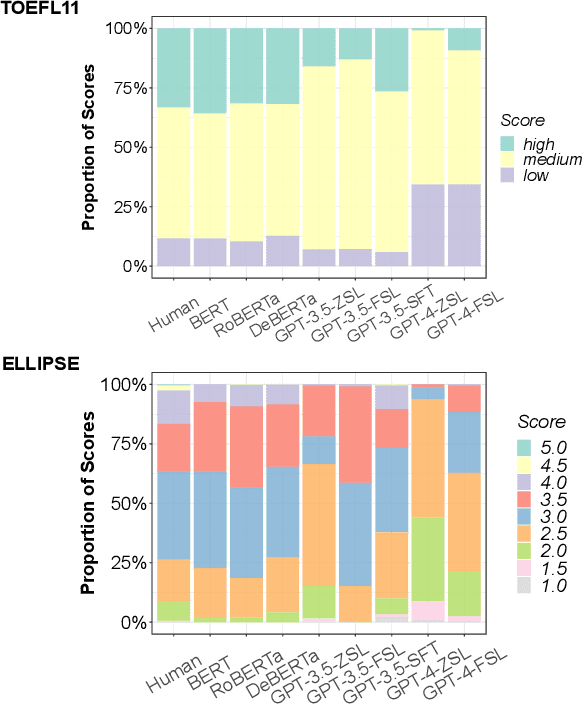
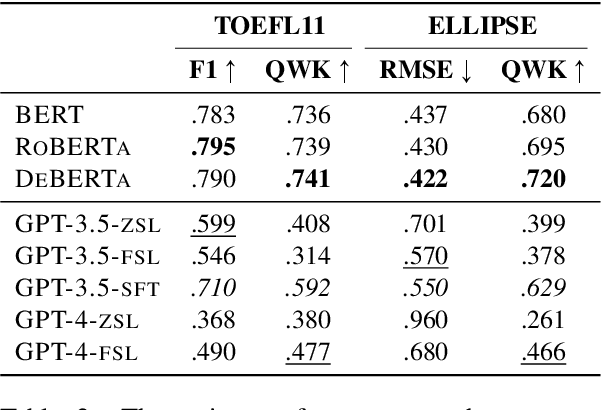
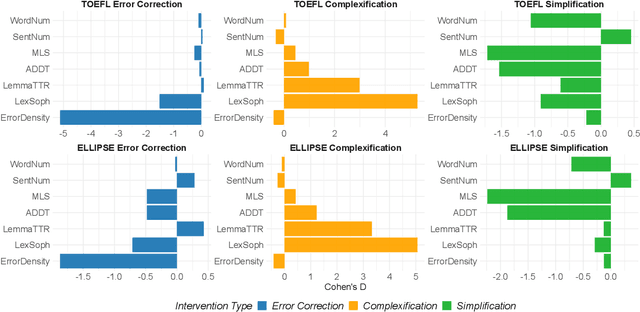
While current automated essay scoring (AES) methods show high agreement with human raters, their scoring mechanisms are not fully explored. Our proposed method, using counterfactual intervention assisted by Large Language Models (LLMs), reveals that when scoring essays, BERT-like models primarily focus on sentence-level features, while LLMs are attuned to conventions, language complexity, as well as organization, indicating a more comprehensive alignment with scoring rubrics. Moreover, LLMs can discern counterfactual interventions during feedback. Our approach improves understanding of neural AES methods and can also apply to other domains seeking transparency in model-driven decisions. The codes and data will be released at GitHub.
View paper on