 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
UniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025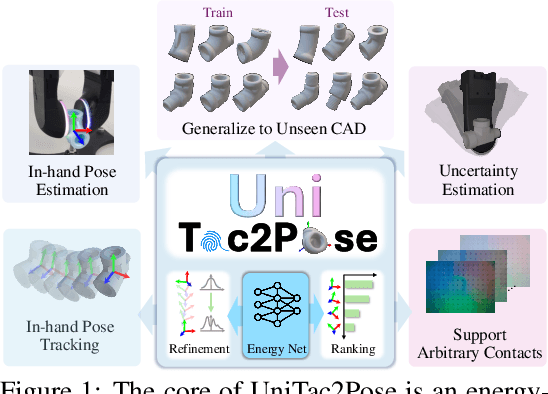
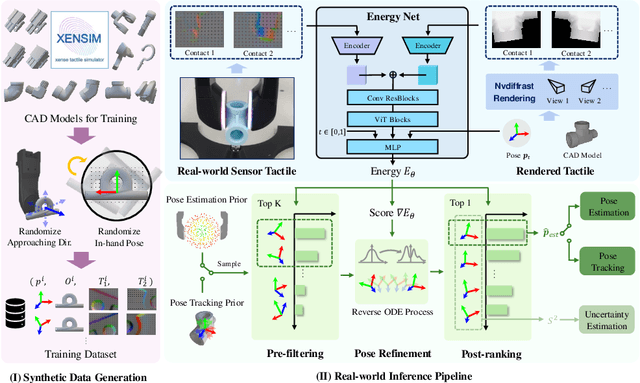

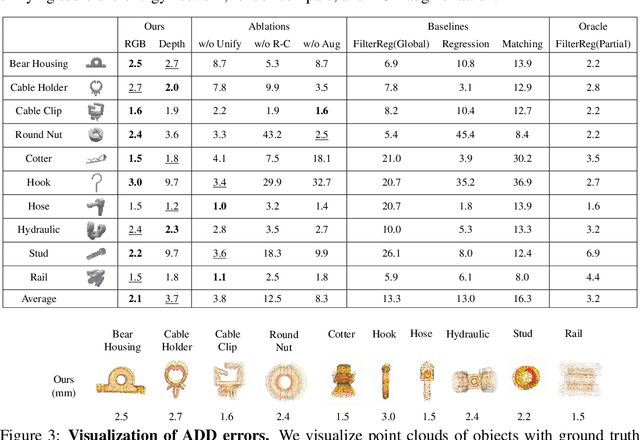
Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Eraser: Jailbreaking Defense in Large Language Models via Unlearning Harmful Knowledge
Apr 08, 2024



Jailbreaking attacks can enable Large Language Models (LLMs) to bypass the safeguard and generate harmful content. Existing jailbreaking defense methods have failed to address the fundamental issue that harmful knowledge resides within the model, leading to potential jailbreak risks for LLMs. In this paper, we propose a novel defense method called Eraser, which mainly includes three goals: unlearning harmful knowledge, retaining general knowledge, and maintaining safety alignment. The intuition is that if an LLM forgets the specific knowledge required to answer a harmful question, it will no longer have the ability to answer harmful questions. The training of Erase does not actually require the model's own harmful knowledge, and it can benefit from unlearning general answers related to harmful queries, which means it does not need assistance from the red team. The experimental results show that Eraser can significantly reduce the jailbreaking success rate for various attacks without compromising the general capabilities of the model.
Letter-level Online Writer Identification
Dec 06, 2021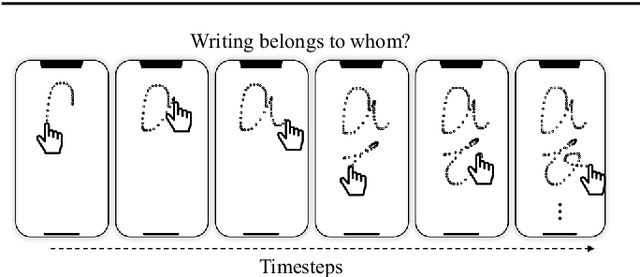
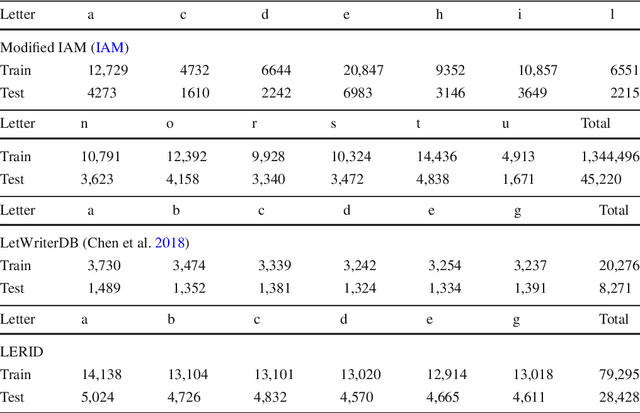
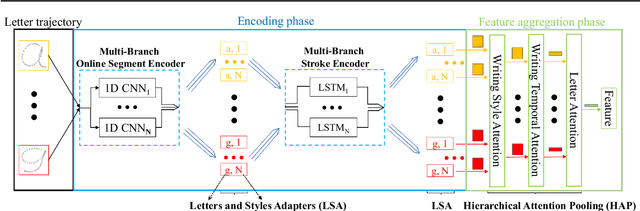

Writer identification (writer-id), an important field in biometrics, aims to identify a writer by their handwriting. Identification in existing writer-id studies requires a complete document or text, limiting the scalability and flexibility of writer-id in realistic applications. To make the application of writer-id more practical (e.g., on mobile devices), we focus on a novel problem, letter-level online writer-id, which requires only a few trajectories of written letters as identification cues. Unlike text-\ document-based writer-id which has rich context for identification, there are much fewer clues to recognize an author from only a few single letters. A main challenge is that a person often writes a letter in different styles from time to time. We refer to this problem as the variance of online writing styles (Var-O-Styles). We address the Var-O-Styles in a capture-normalize-aggregate fashion: Firstly, we extract different features of a letter trajectory by a carefully designed multi-branch encoder, in an attempt to capture different online writing styles. Then we convert all these style features to a reference style feature domain by a novel normalization layer. Finally, we aggregate the normalized features by a hierarchical attention pooling (HAP), which fuses all the input letters with multiple writing styles into a compact feature vector. In addition, we also contribute a large-scale LEtter-level online wRiter IDentification dataset (LERID) for evaluation. Extensive comparative experiments demonstrate the effectiveness of the proposed framework.