 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Perspective Evidence Synthesis and Reasoning for Unsupervised Multimodal Entity Linking
Apr 22, 2026Multimodal Entity Linking (MEL) is a fundamental task in data management that maps ambiguous mentions with diverse modalities to the multimodal entities in a knowledge base. However, most existing MEL approaches primarily focus on optimizing instance-centric features and evidence, leaving broader forms of evidence and their intricate interdependencies insufficiently explored. Motivated by the observation that human expert decision-making process relies on multi-perspective judgment, in this work, we propose MSR-MEL, a Multi-perspective Evidence Synthesis and Reasoning framework with Large Language Models (LLMs) for unsupervised MEL. Specifically, we adopt a two-stage framework: (1) Offline Multi-Perspective Evidence Synthesis constructs a comprehensive set of evidence. This includes instance-centric evidence capturing the instance-centric multimodal information of mentions and entities, group-level evidence that aggregates neighborhood information, lexical evidence based on string overlap ratio, and statistical evidence based on simple summary statistics. A core contribution of our framework is the synthesis of group-level evidence, which effectively aggregates vital neighborhood information by graph. We first construct LLM-enhanced contextualized graphs. Subsequently, different modalities are jointly aligned through an asymmetric teacher-student graph neural network. (2) Online Multi-Perspective Evidence Reasoning leverages the power of LLM as a reasoning module to analyze the correlation and semantics of the multi-perspective evidence to induce an effective ranking strategy for accurate entity linking without supervision. Extensive experiments on widely used MEL benchmarks demonstrate that MSR-MEL consistently outperforms state-of-the-art unsupervised methods. The source code of this paper was available at: https://anonymous.4open.science/r/MSR-MEL-C21E/.
Advancing Multimodal Agent Reasoning with Long-Term Neuro-Symbolic Memory
Mar 16, 2026Recent advances in large language models have driven the emergence of intelligent agents operating in open-world, multimodal environments. To support long-term reasoning, such agents are typically equipped with external memory systems. However, most existing multimodal agent memories rely primarily on neural representations and vector-based retrieval, which are well-suited for inductive, intuitive reasoning but fundamentally limited in supporting analytical, deductive reasoning critical for real-world decision making. To address this limitation, we propose NS-Mem, a long-term neuro-symbolic memory framework designed to advance multimodal agent reasoning by integrating neural memory with explicit symbolic structures and rules. Specifically, NS-Mem is operated around three core components of a memory system: (1) a three-layer memory architecture that consists episodic layer, semantic layer and logic rule layer, (2) a memory construction and maintenance mechanism implemented by SK-Gen that automatically consolidates structured knowledge from accumulated multimodal experiences and incrementally updates both neural representations and symbolic rules, and (3) a hybrid memory retrieval mechanism that combines similarity-based search with deterministic symbolic query functions to support structured reasoning. Experiments on real-world multimodal reasoning benchmarks demonstrate that Neural-Symbolic Memory achieves an average 4.35% improvement in overall reasoning accuracy over pure neural memory systems, with gains of up to 12.5% on constrained reasoning queries, validating the effectiveness of NS-Mem.
HyperJoin: LLM-augmented Hypergraph Link Prediction for Joinable Table Discovery
Jan 03, 2026As a pivotal task in data lake management, joinable table discovery has attracted widespread interest. While existing language model-based methods achieve remarkable performance by combining offline column representation learning with online ranking, their design insufficiently accounts for the underlying structural interactions: (1) offline, they directly model tables into isolated or pairwise columns, thereby struggling to capture the rich inter-table and intra-table structural information; and (2) online, they rank candidate columns based solely on query-candidate similarity, ignoring the mutual interactions among the candidates, leading to incoherent result sets. To address these limitations, we propose HyperJoin, a large language model (LLM)-augmented Hypergraph framework for Joinable table discovery. Specifically, we first construct a hypergraph to model tables using both the intra-table hyperedges and the LLM-augmented inter-table hyperedges. Consequently, the task of joinable table discovery is formulated as link prediction on this constructed hypergraph. We then design HIN, a Hierarchical Interaction Network that learns expressive column representations through bidirectional message passing over columns and hyperedges. To strengthen coherence and internal consistency in the result columns, we cast online ranking as a coherence-aware top-k column selection problem. We then introduce a reranking module that leverages a maximum spanning tree algorithm to prune noisy connections and maximize coherence. Experiments demonstrate the superiority of HyperJoin, achieving average improvements of 21.4% (Precision@15) and 17.2% (Recall@15) over the best baseline.
DINO-BOLDNet: A DINOv3-Guided Multi-Slice Attention Network for T1-to-BOLD Generation
Dec 09, 2025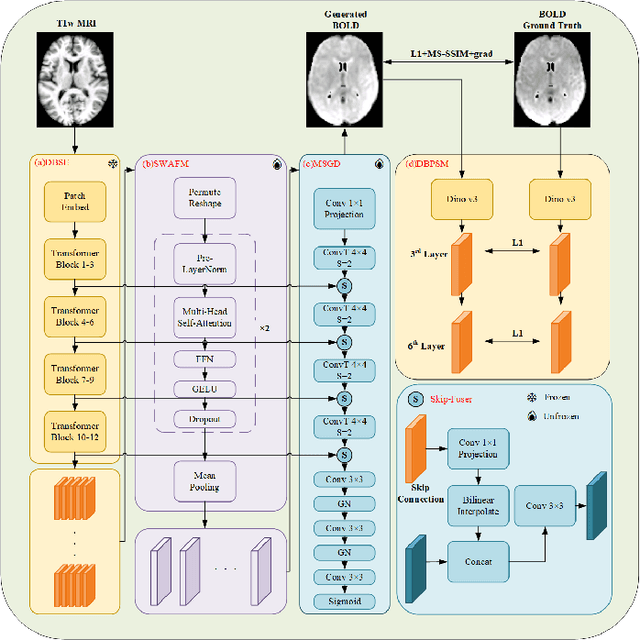
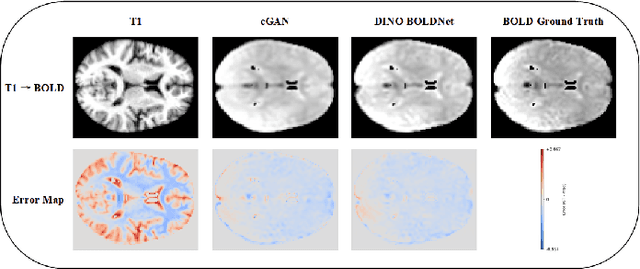
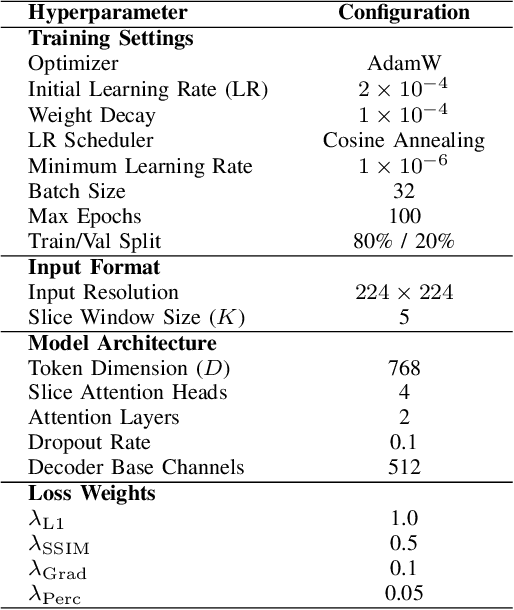
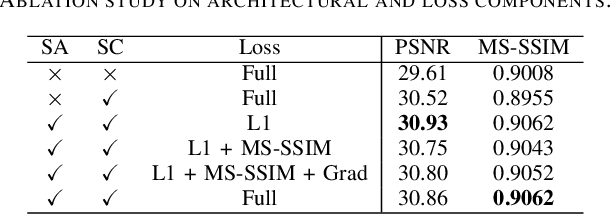
Generating BOLD images from T1w images offers a promising solution for recovering missing BOLD information and enabling downstream tasks when BOLD images are corrupted or unavailable. Motivated by this, we propose DINO-BOLDNet, a DINOv3-guided multi-slice attention framework that integrates a frozen self-supervised DINOv3 encoder with a lightweight trainable decoder. The model uses DINOv3 to extract within-slice structural representations, and a separate slice-attention module to fuse contextual information across neighboring slices. A multi-scale generation decoder then restores fine-grained functional contrast, while a DINO-based perceptual loss encourages structural and textural consistency between predictions and ground-truth BOLD in the transformer feature space. Experiments on a clinical dataset of 248 subjects show that DINO-BOLDNet surpasses a conditional GAN baseline in both PSNR and MS-SSIM. To our knowledge, this is the first framework capable of generating mean BOLD images directly from T1w images, highlighting the potential of self-supervised transformer guidance for structural-to-functional mapping.
Ensembling LLM-Induced Decision Trees for Explainable and Robust Error Detection
Dec 08, 2025Error detection (ED), which aims to identify incorrect or inconsistent cell values in tabular data, is important for ensuring data quality. Recent state-of-the-art ED methods leverage the pre-trained knowledge and semantic capability embedded in large language models (LLMs) to directly label whether a cell is erroneous. However, this LLM-as-a-labeler pipeline (1) relies on the black box, implicit decision process, thus failing to provide explainability for the detection results, and (2) is highly sensitive to prompts, yielding inconsistent outputs due to inherent model stochasticity, therefore lacking robustness. To address these limitations, we propose an LLM-as-an-inducer framework that adopts LLM to induce the decision tree for ED (termed TreeED) and further ensembles multiple such trees for consensus detection (termed ForestED), thereby improving explainability and robustness. Specifically, based on prompts derived from data context, decision tree specifications and output requirements, TreeED queries the LLM to induce the decision tree skeleton, whose root-to-leaf decision paths specify the stepwise procedure for evaluating a given sample. Each tree contains three types of nodes: (1) rule nodes that perform simple validation checks (e.g., format or range), (2) Graph Neural Network (GNN) nodes that capture complex patterns (e.g., functional dependencies), and (3) leaf nodes that output the final decision types (error or clean). Furthermore, ForestED employs uncertainty-based sampling to obtain multiple row subsets, constructing a decision tree for each subset using TreeED. It then leverages an Expectation-Maximization-based algorithm that jointly estimates tree reliability and optimizes the consensus ED prediction. Extensive xperiments demonstrate that our methods are accurate, explainable and robust, achieving an average F1-score improvement of 16.1% over the best baseline.
LLM-based HSE Compliance Assessment: Benchmark, Performance, and Advancements
May 29, 2025Health, Safety, and Environment (HSE) compliance assessment demands dynamic real-time decision-making under complicated regulations and complex human-machine-environment interactions. While large language models (LLMs) hold significant potential for decision intelligence and contextual dialogue, their capacity for domain-specific knowledge in HSE and structured legal reasoning remains underexplored. We introduce HSE-Bench, the first benchmark dataset designed to evaluate the HSE compliance assessment capabilities of LLM. HSE-Bench comprises over 1,000 manually curated questions drawn from regulations, court cases, safety exams, and fieldwork videos, and integrates a reasoning flow based on Issue spotting, rule Recall, rule Application, and rule Conclusion (IRAC) to assess the holistic reasoning pipeline. We conduct extensive evaluations on different prompting strategies and more than 10 LLMs, including foundation models, reasoning models and multimodal vision models. The results show that, although current LLMs achieve good performance, their capabilities largely rely on semantic matching rather than principled reasoning grounded in the underlying HSE compliance context. Moreover, their native reasoning trace lacks the systematic legal reasoning required for rigorous HSE compliance assessment. To alleviate these, we propose a new prompting technique, Reasoning of Expert (RoE), which guides LLMs to simulate the reasoning process of different experts for compliance assessment and reach a more accurate unified decision. We hope our study highlights reasoning gaps in LLMs for HSE compliance and inspires further research on related tasks.
ProbDiffFlow: An Efficient Learning-Free Framework for Probabilistic Single-Image Optical Flow Estimation
Mar 16, 2025This paper studies optical flow estimation, a critical task in motion analysis with applications in autonomous navigation, action recognition, and film production. Traditional optical flow methods require consecutive frames, which are often unavailable due to limitations in data acquisition or real-world scene disruptions. Thus, single-frame optical flow estimation is emerging in the literature. However, existing single-frame approaches suffer from two major limitations: (1) they rely on labeled training data, making them task-specific, and (2) they produce deterministic predictions, failing to capture motion uncertainty. To overcome these challenges, we propose ProbDiffFlow, a training-free framework that estimates optical flow distributions from a single image. Instead of directly predicting motion, ProbDiffFlow follows an estimation-by-synthesis paradigm: it first generates diverse plausible future frames using a diffusion-based model, then estimates motion from these synthesized samples using a pre-trained optical flow model, and finally aggregates the results into a probabilistic flow distribution. This design eliminates the need for task-specific training while capturing multiple plausible motions. Experiments on both synthetic and real-world datasets demonstrate that ProbDiffFlow achieves superior accuracy, diversity, and efficiency, outperforming existing single-image and two-frame baselines.
RewardDS: Privacy-Preserving Fine-Tuning for Large Language Models via Reward Driven Data Synthesis
Feb 23, 2025



The success of large language models (LLMs) has attracted many individuals to fine-tune them for domain-specific tasks by uploading their data. However, in sensitive areas like healthcare and finance, privacy concerns often arise. One promising solution is to sample synthetic data with Differential Privacy (DP) guarantees to replace private data. However, these synthetic data contain significant flawed data, which are considered as noise. Existing solutions typically rely on naive filtering by comparing ROUGE-L scores or embedding similarities, which are ineffective in addressing the noise. To address this issue, we propose RewardDS, a novel privacy-preserving framework that fine-tunes a reward proxy model and uses reward signals to guide the synthetic data generation. Our RewardDS introduces two key modules, Reward Guided Filtering and Self-Optimizing Refinement, to both filter and refine the synthetic data, effectively mitigating the noise. Extensive experiments across medical, financial, and code generation domains demonstrate the effectiveness of our method.
On LLM-Enhanced Mixed-Type Data Imputation with High-Order Message Passing
Jan 04, 2025



Missing data imputation, which aims to impute the missing values in the raw datasets to achieve the completeness of datasets, is crucial for modern data-driven models like large language models (LLMs) and has attracted increasing interest over the past decades. Despite its importance, existing solutions for missing data imputation either 1) only support numerical and categorical data or 2) show an unsatisfactory performance due to their design prioritizing text data and the lack of key properties for tabular data imputation. In this paper, we propose UnIMP, a Unified IMPutation framework that leverages LLM and high-order message passing to enhance the imputation of mixed-type data including numerical, categorical, and text data. Specifically, we first introduce a cell-oriented hypergraph to model the table. We then propose BiHMP, an efficient Bidirectional High-order Message-Passing network to aggregate global-local information and high-order relationships on the constructed hypergraph while capturing the inter-column heterogeneity and intra-column homogeneity. To effectively and efficiently align the capacity of the LLM with the information aggregated by BiHMP, we introduce Xfusion, which, together with BiHMP, acts as adapters for the LLM. We follow a pre-training and fine-tuning pipeline to train UnIMP, integrating two optimizations: chunking technique, which divides tables into smaller chunks to enhance efficiency; and progressive masking technique, which gradually adapts the model to learn more complex data patterns. Both theoretical proofs and empirical experiments on 10 real world datasets highlight the superiority of UnIMP over existing techniques.
PrivacyRestore: Privacy-Preserving Inference in Large Language Models via Privacy Removal and Restoration
Jun 03, 2024



The widespread usage of online Large Language Models (LLMs) inference services has raised significant privacy concerns about the potential exposure of private information in user inputs to eavesdroppers or untrustworthy service providers. Existing privacy protection methods for LLMs suffer from insufficient privacy protection, performance degradation, or severe inference time overhead. In this paper, we propose PrivacyRestore to protect the privacy of user inputs during LLM inference. PrivacyRestore directly removes privacy spans in user inputs and restores privacy information via activation steering during inference. The privacy spans are encoded as restoration vectors. We propose Attention-aware Weighted Aggregation (AWA) which aggregates restoration vectors of all privacy spans in the input into a meta restoration vector. AWA not only ensures proper representation of all privacy spans but also prevents attackers from inferring the privacy spans from the meta restoration vector alone. This meta restoration vector, along with the query with privacy spans removed, is then sent to the server. The experimental results show that PrivacyRestore can protect private information while maintaining acceptable levels of performance and inference efficiency.