 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based HSE Compliance Assessment: Benchmark, Performance, and Advancements
May 29, 2025Health, Safety, and Environment (HSE) compliance assessment demands dynamic real-time decision-making under complicated regulations and complex human-machine-environment interactions. While large language models (LLMs) hold significant potential for decision intelligence and contextual dialogue, their capacity for domain-specific knowledge in HSE and structured legal reasoning remains underexplored. We introduce HSE-Bench, the first benchmark dataset designed to evaluate the HSE compliance assessment capabilities of LLM. HSE-Bench comprises over 1,000 manually curated questions drawn from regulations, court cases, safety exams, and fieldwork videos, and integrates a reasoning flow based on Issue spotting, rule Recall, rule Application, and rule Conclusion (IRAC) to assess the holistic reasoning pipeline. We conduct extensive evaluations on different prompting strategies and more than 10 LLMs, including foundation models, reasoning models and multimodal vision models. The results show that, although current LLMs achieve good performance, their capabilities largely rely on semantic matching rather than principled reasoning grounded in the underlying HSE compliance context. Moreover, their native reasoning trace lacks the systematic legal reasoning required for rigorous HSE compliance assessment. To alleviate these, we propose a new prompting technique, Reasoning of Expert (RoE), which guides LLMs to simulate the reasoning process of different experts for compliance assessment and reach a more accurate unified decision. We hope our study highlights reasoning gaps in LLMs for HSE compliance and inspires further research on related tasks.
Device Tuning for Multi-Task Large Model
Feb 21, 2023

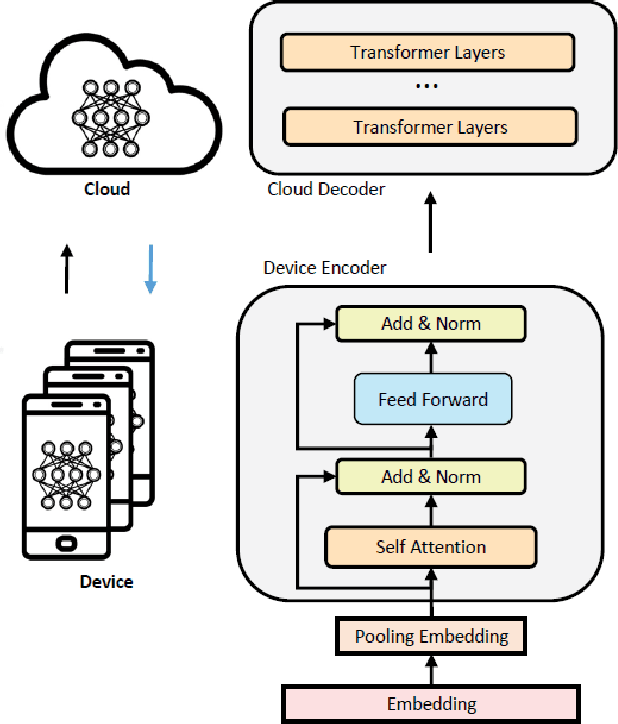
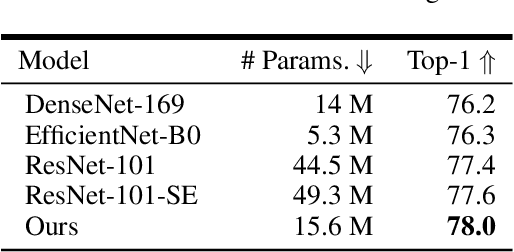
Unsupervised pre-training approaches have achieved great success in many fields such as Computer Vision (CV), Natural Language Processing (NLP) and so on. However, compared to typical deep learning models, pre-training or even fine-tuning the state-of-the-art self-attention models is extremely expensive, as they require much more computational and memory resources. It severely limits their applications and success in a variety of domains, especially for multi-task learning. To improve the efficiency, we propose Device Tuning for the efficient multi-task model, which is a massively multitask framework across the cloud and device and is designed to encourage learning of representations that generalize better to many different tasks. Specifically, we design Device Tuning architecture of a multi-task model that benefits both cloud modelling and device modelling, which reduces the communication between device and cloud by representation compression. Experimental results demonstrate the effectiveness of our proposed method.