 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Small and Fast BERT for Chinese Medical Punctuation Restoration
Aug 24, 2023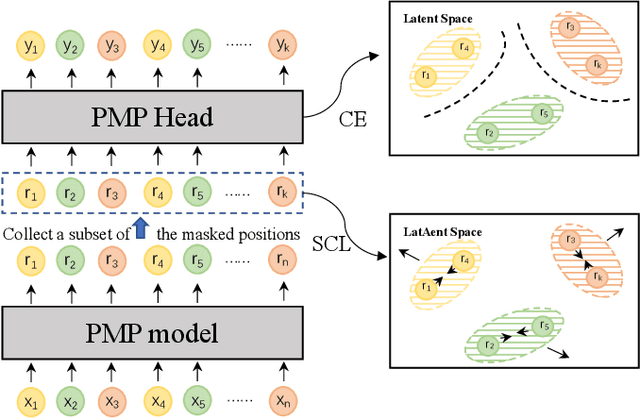
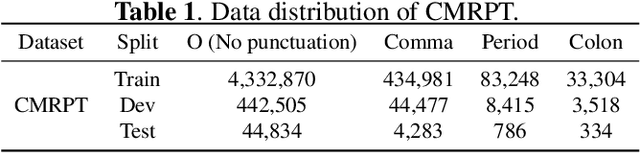
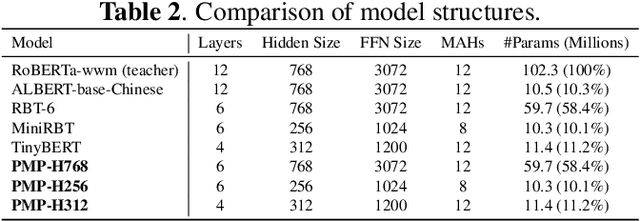
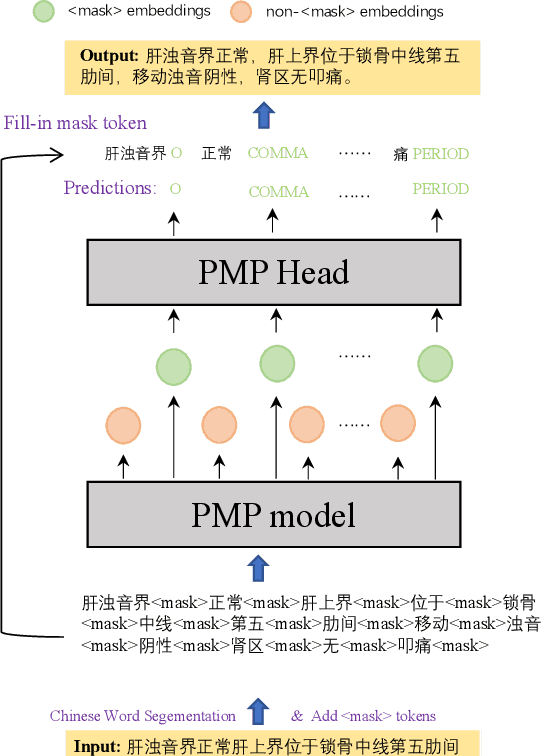
In clinical dictation, utterances after automatic speech recognition (ASR) without explicit punctuation marks may lead to the misunderstanding of dictated reports. To give a precise and understandable clinical report with ASR, automatic punctuation restoration is required. Considering a practical scenario, we propose a fast and light pre-trained model for Chinese medical punctuation restoration based on 'pretraining and fine-tuning' paradigm. In this work, we distill pre-trained models by incorporating supervised contrastive learning and a novel auxiliary pre-training task (Punctuation Mark Prediction) to make it well-suited for punctuation restoration. Our experiments on various distilled models reveal that our model can achieve 95% performance while 10% model size relative to state-of-the-art Chinese RoBERTa.
Sentence-level Event Detection without Triggers via Prompt Learning and Machine Reading Comprehension
Jun 25, 2023The traditional way of sentence-level event detection involves two important subtasks: trigger identification and trigger classifications, where the identified event trigger words are used to classify event types from sentences. However, trigger classification highly depends on abundant annotated trigger words and the accuracy of trigger identification. In a real scenario, annotating trigger words is time-consuming and laborious. For this reason, we propose a trigger-free event detection model, which transforms event detection into a two-tower model based on machine reading comprehension and prompt learning. Compared to existing trigger-based and trigger-free methods, experimental studies on two event detection benchmark datasets (ACE2005 and MAVEN) have shown that the proposed approach can achieve competitive performance.
Evolutionary Verbalizer Search for Prompt-based Few Shot Text Classification
Jun 18, 2023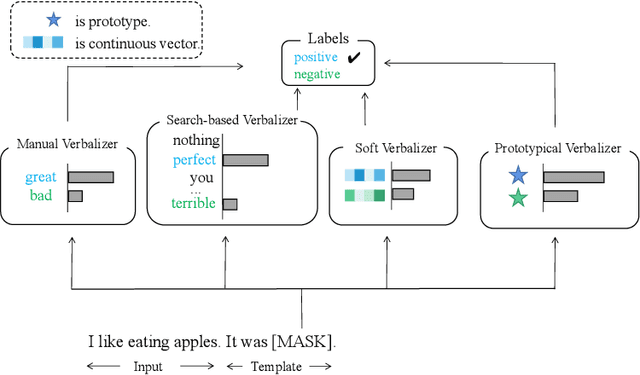
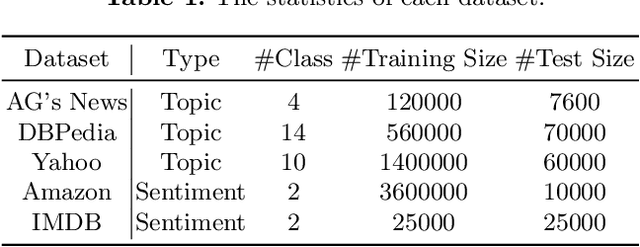
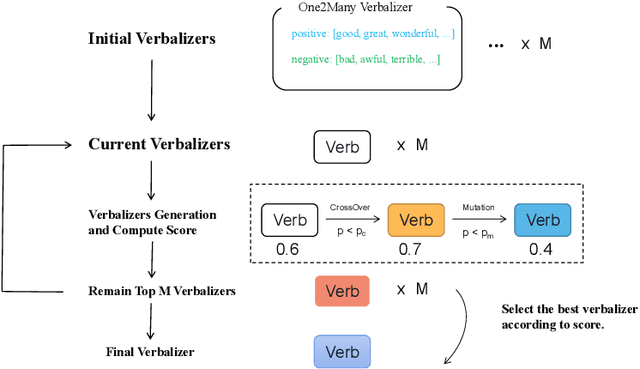
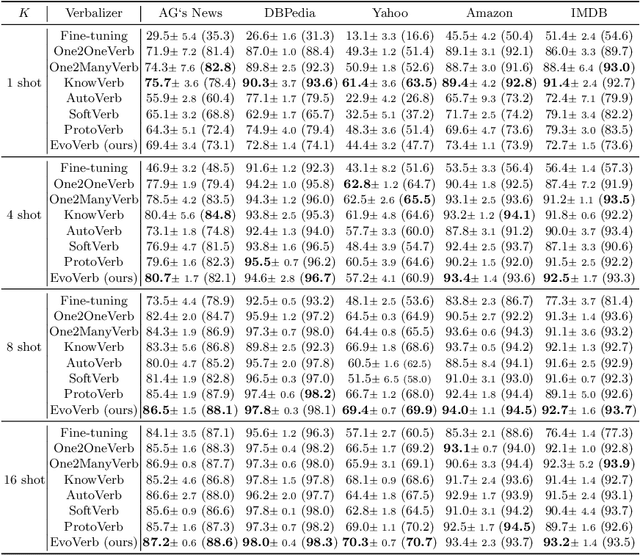
Recent advances for few-shot text classification aim to wrap textual inputs with task-specific prompts to cloze questions. By processing them with a masked language model to predict the masked tokens and using a verbalizer that constructs the mapping between predicted words and target labels. This approach of using pre-trained language models is called prompt-based tuning, which could remarkably outperform conventional fine-tuning approach in the low-data scenario. As the core of prompt-based tuning, the verbalizer is usually handcrafted with human efforts or suboptimally searched by gradient descent. In this paper, we focus on automatically constructing the optimal verbalizer and propose a novel evolutionary verbalizer search (EVS) algorithm, to improve prompt-based tuning with the high-performance verbalizer. Specifically, inspired by evolutionary algorithm (EA), we utilize it to automatically evolve various verbalizers during the evolutionary procedure and select the best one after several iterations. Extensive few-shot experiments on five text classification datasets show the effectiveness of our method.