 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Powerful Prior Knowledge of Diffusion Model in Deep Unfolding Networks for Image Compressive Sensing
Mar 11, 2025Recently, Deep Unfolding Networks (DUNs) have achieved impressive reconstruction quality in the field of image Compressive Sensing (CS) by unfolding iterative optimization algorithms into neural networks. The reconstruction quality of DUNs depends on the learned prior knowledge, so introducing stronger prior knowledge can further improve reconstruction quality. On the other hand, pre-trained diffusion models contain powerful prior knowledge and have a solid theoretical foundation and strong scalability, but it requires a large number of iterative steps to achieve reconstruction. In this paper, we propose to use the powerful prior knowledge of pre-trained diffusion model in DUNs to achieve high-quality reconstruction with less steps for image CS. Specifically, we first design an iterative optimization algorithm named Diffusion Message Passing (DMP), which embeds a pre-trained diffusion model into each iteration process of DMP. Then, we deeply unfold the DMP algorithm into a neural network named DMP-DUN. The proposed DMP-DUN can use lightweight neural networks to achieve mapping from measurement data to the intermediate steps of the reverse diffusion process and directly approximate the divergence of the diffusion model, thereby further improving reconstruction efficiency. Extensive experiments show that our proposed DMP-DUN achieves state-of-the-art performance and requires at least only 2 steps to reconstruct the image. Codes are available at https://github.com/FengodChen/DMP-DUN-CVPR2025.
A Small and Fast BERT for Chinese Medical Punctuation Restoration
Aug 24, 2023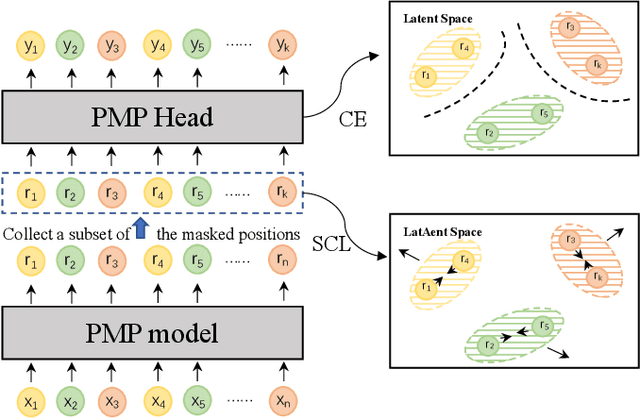
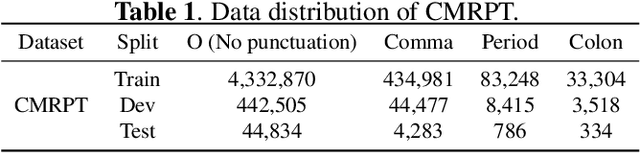
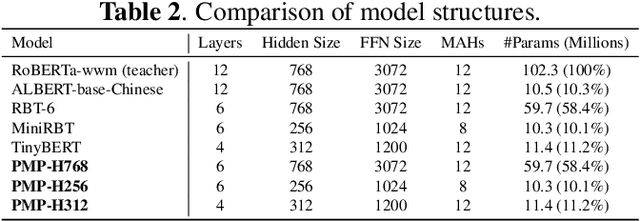
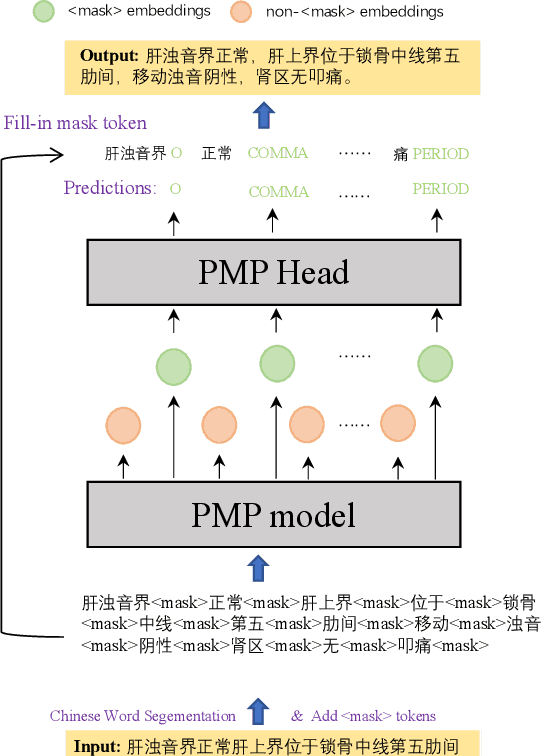
In clinical dictation, utterances after automatic speech recognition (ASR) without explicit punctuation marks may lead to the misunderstanding of dictated reports. To give a precise and understandable clinical report with ASR, automatic punctuation restoration is required. Considering a practical scenario, we propose a fast and light pre-trained model for Chinese medical punctuation restoration based on 'pretraining and fine-tuning' paradigm. In this work, we distill pre-trained models by incorporating supervised contrastive learning and a novel auxiliary pre-training task (Punctuation Mark Prediction) to make it well-suited for punctuation restoration. Our experiments on various distilled models reveal that our model can achieve 95% performance while 10% model size relative to state-of-the-art Chinese RoBERTa.