 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Small and Fast BERT for Chinese Medical Punctuation Restoration
Aug 24, 2023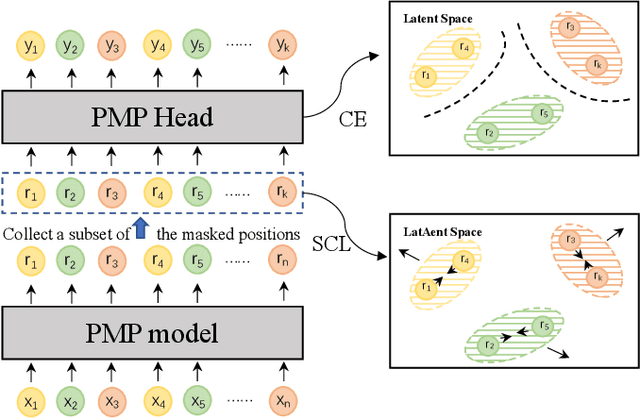
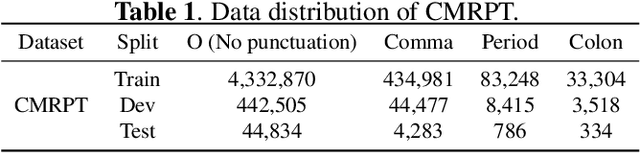
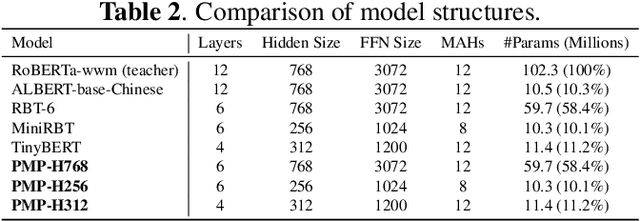
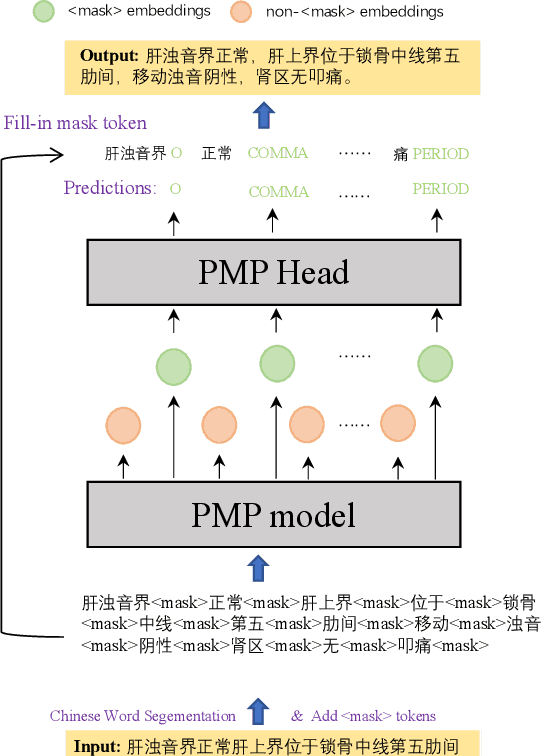
In clinical dictation, utterances after automatic speech recognition (ASR) without explicit punctuation marks may lead to the misunderstanding of dictated reports. To give a precise and understandable clinical report with ASR, automatic punctuation restoration is required. Considering a practical scenario, we propose a fast and light pre-trained model for Chinese medical punctuation restoration based on 'pretraining and fine-tuning' paradigm. In this work, we distill pre-trained models by incorporating supervised contrastive learning and a novel auxiliary pre-training task (Punctuation Mark Prediction) to make it well-suited for punctuation restoration. Our experiments on various distilled models reveal that our model can achieve 95% performance while 10% model size relative to state-of-the-art Chinese RoBERTa.
Stylized Dialogue Response Generation Using Stylized Unpaired Texts
Sep 27, 2020
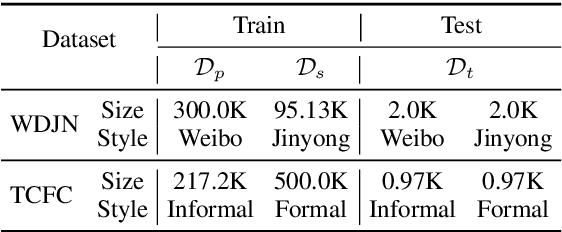
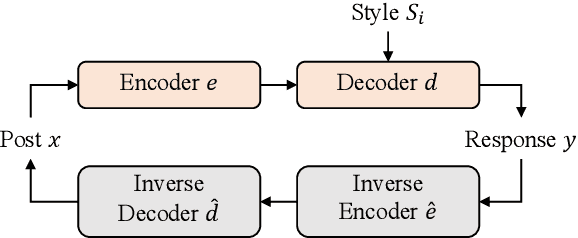
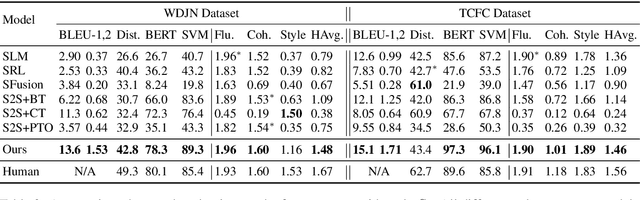
Generating stylized responses is essential to build intelligent and engaging dialogue systems. However, this task is far from well-explored due to the difficulties of rendering a particular style in coherent responses, especially when the target style is embedded only in unpaired texts that cannot be directly used to train the dialogue model. This paper proposes a stylized dialogue generation method that can capture stylistic features embedded in unpaired texts. Specifically, our method can produce dialogue responses that are both coherent to the given context and conform to the target style. In this study, an inverse dialogue model is first introduced to predict possible posts for the input responses, and then this inverse model is used to generate stylized pseudo dialogue pairs based on these stylized unpaired texts. Further, these pseudo pairs are employed to train the stylized dialogue model with a joint training process, and a style routing approach is proposed to intensify stylistic features in the decoder. Automatic and manual evaluations on two datasets demonstrate that our method outperforms competitive baselines in producing coherent and style-intensive dialogue responses.