 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete MeanFlow: One-Step Generation via Conditional Transition Kernels
May 12, 2026MeanFlow enables one-step generation in continuous spaces by learning an average velocity over a time interval rather than the instantaneous velocity field of flow matching. However, discrete state spaces do not have smooth trajectories or spatial derivatives, so the continuous formulation does not directly apply. We introduce Discrete MeanFlow, which replaces the motion of a point with the transport of probability mass over finite states. Our key object is the conditional transition kernel of a continuous-time Markov chain (CTMC), from which we define a mean discrete rate that measures the average change in transition probability over a time interval. We prove a Discrete MeanFlow identity that relates this finite-interval rate to the instantaneous CTMC generator at the endpoint, with the Kolmogorov forward equation replacing the spatial chain rule of continuous MeanFlow. Based on this identity, we parameterize the transition kernel directly using a boundary-by-construction design that guarantees valid probability outputs and exact boundary conditions without auxiliary losses. Since the learned kernel is itself a probability distribution, generation reduces to a single forward pass followed by one categorical draw meaning no iterative denoising, ODE integration, or multi-step refinement is required. We validate the framework on exact finite-state Markov chains, where the learned kernel recovers the analytical ground truth to high precision, and on factorized synthetic sequence generation tasks with varying alphabet sizes and sequence lengths.
Flow Matching for Offline Reinforcement Learning with Discrete Actions
Feb 05, 2026Generative policies based on diffusion models and flow matching have shown strong promise for offline reinforcement learning (RL), but their applicability remains largely confined to continuous action spaces. To address a broader range of offline RL settings, we extend flow matching to a general framework that supports discrete action spaces with multiple objectives. Specifically, we replace continuous flows with continuous-time Markov chains, trained using a Q-weighted flow matching objective. We then extend our design to multi-agent settings, mitigating the exponential growth of joint action spaces via a factorized conditional path. We theoretically show that, under idealized conditions, optimizing this objective recovers the optimal policy. Extensive experiments further demonstrate that our method performs robustly in practical scenarios, including high-dimensional control, multi-modal decision-making, and dynamically changing preferences over multiple objectives. Our discrete framework can also be applied to continuous-control problems through action quantization, providing a flexible trade-off between representational complexity and performance.
Augmenting Online RL with Offline Data is All You Need: A Unified Hybrid RL Algorithm Design and Analysis
May 19, 2025This paper investigates a hybrid learning framework for reinforcement learning (RL) in which the agent can leverage both an offline dataset and online interactions to learn the optimal policy. We present a unified algorithm and analysis and show that augmenting confidence-based online RL algorithms with the offline dataset outperforms any pure online or offline algorithm alone and achieves state-of-the-art results under two learning metrics, i.e., sub-optimality gap and online learning regret. Specifically, we show that our algorithm achieves a sub-optimality gap $\tilde{O}(\sqrt{1/(N_0/\mathtt{C}(\pi^*|\rho)+N_1}) )$, where $\mathtt{C}(\pi^*|\rho)$ is a new concentrability coefficient, $N_0$ and $N_1$ are the numbers of offline and online samples, respectively. For regret minimization, we show that it achieves a constant $\tilde{O}( \sqrt{N_1/(N_0/\mathtt{C}(\pi^{-}|\rho)+N_1)} )$ speed-up compared to pure online learning, where $\mathtt{C}(\pi^-|\rho)$ is the concentrability coefficient over all sub-optimal policies. Our results also reveal an interesting separation on the desired coverage properties of the offline dataset for sub-optimality gap minimization and regret minimization. We further validate our theoretical findings in several experiments in special RL models such as linear contextual bandits and Markov decision processes (MDPs).
How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias
May 02, 2025Language recognition tasks are fundamental in natural language processing (NLP) and have been widely used to benchmark the performance of large language models (LLMs). These tasks also play a crucial role in explaining the working mechanisms of transformers. In this work, we focus on two representative tasks in the category of regular language recognition, known as `even pairs' and `parity check', the aim of which is to determine whether the occurrences of certain subsequences in a given sequence are even. Our goal is to explore how a one-layer transformer, consisting of an attention layer followed by a linear layer, learns to solve these tasks by theoretically analyzing its training dynamics under gradient descent. While even pairs can be solved directly by a one-layer transformer, parity check need to be solved by integrating Chain-of-Thought (CoT), either into the inference stage of a transformer well-trained for the even pairs task, or into the training of a one-layer transformer. For both problems, our analysis shows that the joint training of attention and linear layers exhibits two distinct phases. In the first phase, the attention layer grows rapidly, mapping data sequences into separable vectors. In the second phase, the attention layer becomes stable, while the linear layer grows logarithmically and approaches in direction to a max-margin hyperplane that correctly separates the attention layer outputs into positive and negative samples, and the loss decreases at a rate of $O(1/t)$. Our experiments validate those theoretical results.
Robust Offline Reinforcement Learning for Non-Markovian Decision Processes
Nov 12, 2024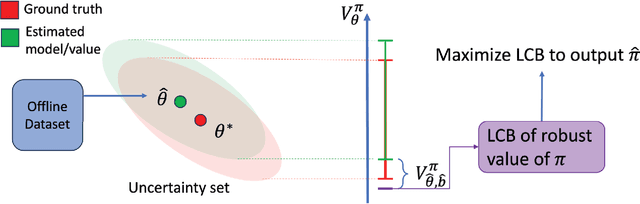

Distributionally robust offline reinforcement learning (RL) aims to find a policy that performs the best under the worst environment within an uncertainty set using an offline dataset collected from a nominal model. While recent advances in robust RL focus on Markov decision processes (MDPs), robust non-Markovian RL is limited to planning problem where the transitions in the uncertainty set are known. In this paper, we study the learning problem of robust offline non-Markovian RL. Specifically, when the nominal model admits a low-rank structure, we propose a new algorithm, featuring a novel dataset distillation and a lower confidence bound (LCB) design for robust values under different types of the uncertainty set. We also derive new dual forms for these robust values in non-Markovian RL, making our algorithm more amenable to practical implementation. By further introducing a novel type-I concentrability coefficient tailored for offline low-rank non-Markovian decision processes, we prove that our algorithm can find an $\epsilon$-optimal robust policy using $O(1/\epsilon^2)$ offline samples. Moreover, we extend our algorithm to the case when the nominal model does not have specific structure. With a new type-II concentrability coefficient, the extended algorithm also enjoys polynomial sample efficiency under all different types of the uncertainty set.
Federated Online Prediction from Experts with Differential Privacy: Separations and Regret Speed-ups
Sep 27, 2024We study the problems of differentially private federated online prediction from experts against both stochastic adversaries and oblivious adversaries. We aim to minimize the average regret on $m$ clients working in parallel over time horizon $T$ with explicit differential privacy (DP) guarantees. With stochastic adversaries, we propose a Fed-DP-OPE-Stoch algorithm that achieves $\sqrt{m}$-fold speed-up of the per-client regret compared to the single-player counterparts under both pure DP and approximate DP constraints, while maintaining logarithmic communication costs. With oblivious adversaries, we establish non-trivial lower bounds indicating that collaboration among clients does not lead to regret speed-up with general oblivious adversaries. We then consider a special case of the oblivious adversaries setting, where there exists a low-loss expert. We design a new algorithm Fed-SVT and show that it achieves an $m$-fold regret speed-up under both pure DP and approximate DP constraints over the single-player counterparts. Our lower bound indicates that Fed-SVT is nearly optimal up to logarithmic factors. Experiments demonstrate the effectiveness of our proposed algorithms. To the best of our knowledge, this is the first work examining the differentially private online prediction from experts in the federated setting.
Non-asymptotic Convergence of Training Transformers for Next-token Prediction
Sep 25, 2024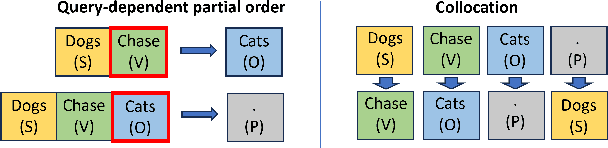
Transformers have achieved extraordinary success in modern machine learning due to their excellent ability to handle sequential data, especially in next-token prediction (NTP) tasks. However, the theoretical understanding of their performance in NTP is limited, with existing studies focusing mainly on asymptotic performance. This paper provides a fine-grained non-asymptotic analysis of the training dynamics of a one-layer transformer consisting of a self-attention module followed by a feed-forward layer. We first characterize the essential structural properties of training datasets for NTP using a mathematical framework based on partial orders. Then, we design a two-stage training algorithm, where the pre-processing stage for training the feed-forward layer and the main stage for training the attention layer exhibit fast convergence performance. Specifically, both layers converge sub-linearly to the direction of their corresponding max-margin solutions. We also show that the cross-entropy loss enjoys a linear convergence rate. Furthermore, we show that the trained transformer presents non-trivial prediction ability with dataset shift, which sheds light on the remarkable generalization performance of transformers. Our analysis technique involves the development of novel properties on the attention gradient and further in-depth analysis of how these properties contribute to the convergence of the training process. Our experiments further validate our theoretical findings.
Provable Benefits of Multi-task RL under Non-Markovian Decision Making Processes
Oct 20, 2023
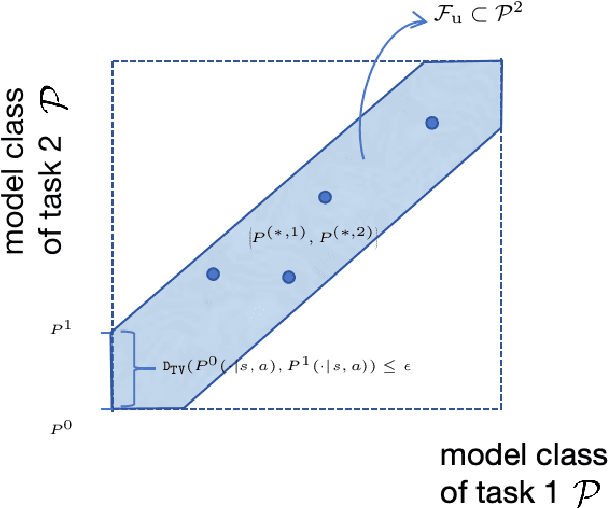
In multi-task reinforcement learning (RL) under Markov decision processes (MDPs), the presence of shared latent structures among multiple MDPs has been shown to yield significant benefits to the sample efficiency compared to single-task RL. In this paper, we investigate whether such a benefit can extend to more general sequential decision making problems, such as partially observable MDPs (POMDPs) and more general predictive state representations (PSRs). The main challenge here is that the large and complex model space makes it hard to identify what types of common latent structure of multi-task PSRs can reduce the model complexity and improve sample efficiency. To this end, we posit a joint model class for tasks and use the notion of $\eta$-bracketing number to quantify its complexity; this number also serves as a general metric to capture the similarity of tasks and thus determines the benefit of multi-task over single-task RL. We first study upstream multi-task learning over PSRs, in which all tasks share the same observation and action spaces. We propose a provably efficient algorithm UMT-PSR for finding near-optimal policies for all PSRs, and demonstrate that the advantage of multi-task learning manifests if the joint model class of PSRs has a smaller $\eta$-bracketing number compared to that of individual single-task learning. We also provide several example multi-task PSRs with small $\eta$-bracketing numbers, which reap the benefits of multi-task learning. We further investigate downstream learning, in which the agent needs to learn a new target task that shares some commonalities with the upstream tasks via a similarity constraint. By exploiting the learned PSRs from the upstream, we develop a sample-efficient algorithm that provably finds a near-optimal policy.
Temporal-Distributed Backdoor Attack Against Video Based Action Recognition
Sep 01, 2023



Deep neural networks (DNNs) have achieved tremendous success in various applications including video action recognition, yet remain vulnerable to backdoor attacks (Trojans). The backdoor-compromised model will mis-classify to the target class chosen by the attacker when a test instance (from a non-target class) is embedded with a specific trigger, while maintaining high accuracy on attack-free instances. Although there are extensive studies on backdoor attacks against image data, the susceptibility of video-based systems under backdoor attacks remains largely unexplored. Current studies are direct extensions of approaches proposed for image data, e.g., the triggers are independently embedded within the frames, which tend to be detectable by existing defenses. In this paper, we introduce a simple yet effective backdoor attack against video data. Our proposed attack, adding perturbations in a transformed domain, plants an imperceptible, temporally distributed trigger across the video frames, and is shown to be resilient to existing defensive strategies. The effectiveness of the proposed attack is demonstrated by extensive experiments with various well-known models on two video recognition benchmarks, UCF101 and HMDB51, and a sign language recognition benchmark, Greek Sign Language (GSL) dataset. We delve into the impact of several influential factors on our proposed attack and identify an intriguing effect termed "collateral damage" through extensive studies.
Provably Efficient UCB-type Algorithms For Learning Predictive State Representations
Jul 01, 2023The general sequential decision-making problem, which includes Markov decision processes (MDPs) and partially observable MDPs (POMDPs) as special cases, aims at maximizing a cumulative reward by making a sequence of decisions based on a history of observations and actions over time. Recent studies have shown that the sequential decision-making problem is statistically learnable if it admits a low-rank structure modeled by predictive state representations (PSRs). Despite these advancements, existing approaches typically involve oracles or steps that are not computationally efficient. On the other hand, the upper confidence bound (UCB) based approaches, which have served successfully as computationally efficient methods in bandits and MDPs, have not been investigated for more general PSRs, due to the difficulty of optimistic bonus design in these more challenging settings. This paper proposes the first known UCB-type approach for PSRs, featuring a novel bonus term that upper bounds the total variation distance between the estimated and true models. We further characterize the sample complexity bounds for our designed UCB-type algorithms for both online and offline PSRs. In contrast to existing approaches for PSRs, our UCB-type algorithms enjoy computational efficiency, last-iterate guaranteed near-optimal policy, and guaranteed model accuracy.