 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-adaptive Differentially Private Prompt Synthesis for In-Context Learning
Oct 15, 2024Large Language Models (LLMs) rely on the contextual information embedded in examples/demonstrations to perform in-context learning (ICL). To mitigate the risk of LLMs potentially leaking private information contained in examples in the prompt, we introduce a novel data-adaptive differentially private algorithm called AdaDPSyn to generate synthetic examples from the private dataset and then use these synthetic examples to perform ICL. The objective of AdaDPSyn is to adaptively adjust the noise level in the data synthesis mechanism according to the inherent statistical properties of the data, thereby preserving high ICL accuracy while maintaining formal differential privacy guarantees. A key innovation in AdaDPSyn is the Precision-Focused Iterative Radius Reduction technique, which dynamically refines the aggregation radius - the scope of data grouping for noise addition - based on patterns observed in data clustering, thereby minimizing the amount of additive noise. We conduct extensive experiments on standard benchmarks and compare AdaDPSyn with DP few-shot generation algorithm (Tang et al., 2023). The experiments demonstrate that AdaDPSyn not only outperforms DP few-shot generation, but also maintains high accuracy levels close to those of non-private baselines, providing an effective solution for ICL with privacy protection.
Federated Online Prediction from Experts with Differential Privacy: Separations and Regret Speed-ups
Sep 27, 2024We study the problems of differentially private federated online prediction from experts against both stochastic adversaries and oblivious adversaries. We aim to minimize the average regret on $m$ clients working in parallel over time horizon $T$ with explicit differential privacy (DP) guarantees. With stochastic adversaries, we propose a Fed-DP-OPE-Stoch algorithm that achieves $\sqrt{m}$-fold speed-up of the per-client regret compared to the single-player counterparts under both pure DP and approximate DP constraints, while maintaining logarithmic communication costs. With oblivious adversaries, we establish non-trivial lower bounds indicating that collaboration among clients does not lead to regret speed-up with general oblivious adversaries. We then consider a special case of the oblivious adversaries setting, where there exists a low-loss expert. We design a new algorithm Fed-SVT and show that it achieves an $m$-fold regret speed-up under both pure DP and approximate DP constraints over the single-player counterparts. Our lower bound indicates that Fed-SVT is nearly optimal up to logarithmic factors. Experiments demonstrate the effectiveness of our proposed algorithms. To the best of our knowledge, this is the first work examining the differentially private online prediction from experts in the federated setting.
Federated Q-Learning: Linear Regret Speedup with Low Communication Cost
Dec 22, 2023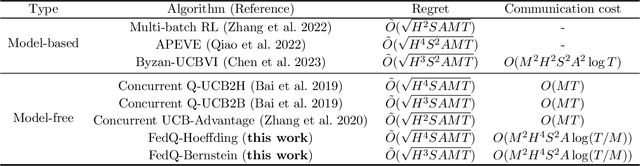
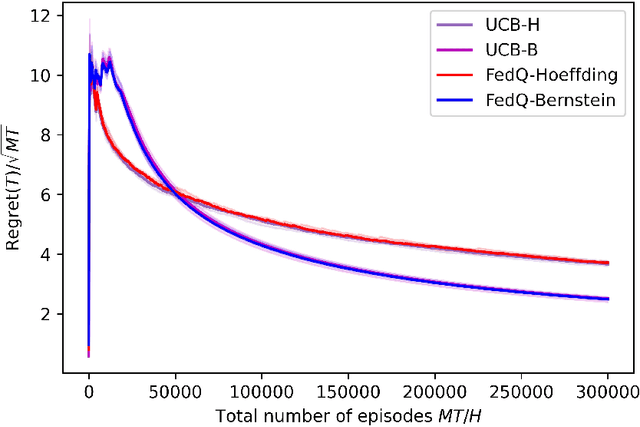
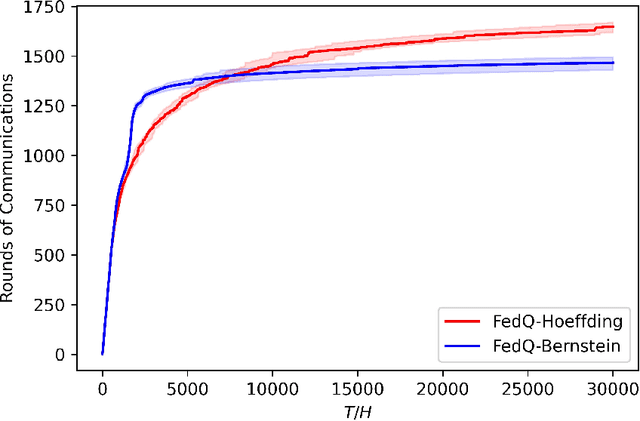
In this paper, we consider federated reinforcement learning for tabular episodic Markov Decision Processes (MDP) where, under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. While linear speedup in the number of agents has been achieved for some metrics, such as convergence rate and sample complexity, in similar settings, it is unclear whether it is possible to design a model-free algorithm to achieve linear regret speedup with low communication cost. We propose two federated Q-Learning algorithms termed as FedQ-Hoeffding and FedQ-Bernstein, respectively, and show that the corresponding total regrets achieve a linear speedup compared with their single-agent counterparts when the time horizon is sufficiently large, while the communication cost scales logarithmically in the total number of time steps $T$. Those results rely on an event-triggered synchronization mechanism between the agents and the server, a novel step size selection when the server aggregates the local estimates of the state-action values to form the global estimates, and a set of new concentration inequalities to bound the sum of non-martingale differences. This is the first work showing that linear regret speedup and logarithmic communication cost can be achieved by model-free algorithms in federated reinforcement learning.