 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the PromptCBLUE Shared Task in CHIP2023
Dec 29, 2023This paper presents an overview of the PromptCBLUE shared task (http://cips-chip.org.cn/2023/eval1) held in the CHIP-2023 Conference. This shared task reformualtes the CBLUE benchmark, and provide a good testbed for Chinese open-domain or medical-domain large language models (LLMs) in general medical natural language processing. Two different tracks are held: (a) prompt tuning track, investigating the multitask prompt tuning of LLMs, (b) probing the in-context learning capabilities of open-sourced LLMs. Many teams from both the industry and academia participated in the shared tasks, and the top teams achieved amazing test results. This paper describes the tasks, the datasets, evaluation metrics, and the top systems for both tasks. Finally, the paper summarizes the techniques and results of the evaluation of the various approaches explored by the participating teams.
PromptCBLUE: A Chinese Prompt Tuning Benchmark for the Medical Domain
Oct 22, 2023



Biomedical language understanding benchmarks are the driving forces for artificial intelligence applications with large language model (LLM) back-ends. However, most current benchmarks: (a) are limited to English which makes it challenging to replicate many of the successes in English for other languages, or (b) focus on knowledge probing of LLMs and neglect to evaluate how LLMs apply these knowledge to perform on a wide range of bio-medical tasks, or (c) have become a publicly available corpus and are leaked to LLMs during pre-training. To facilitate the research in medical LLMs, we re-build the Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark into a large scale prompt-tuning benchmark, PromptCBLUE. Our benchmark is a suitable test-bed and an online platform for evaluating Chinese LLMs' multi-task capabilities on a wide range bio-medical tasks including medical entity recognition, medical text classification, medical natural language inference, medical dialogue understanding and medical content/dialogue generation. To establish evaluation on these tasks, we have experimented and report the results with the current 9 Chinese LLMs fine-tuned with differtent fine-tuning techniques.
Construction and Applications of Open Business Knowledge Graph
Sep 30, 2022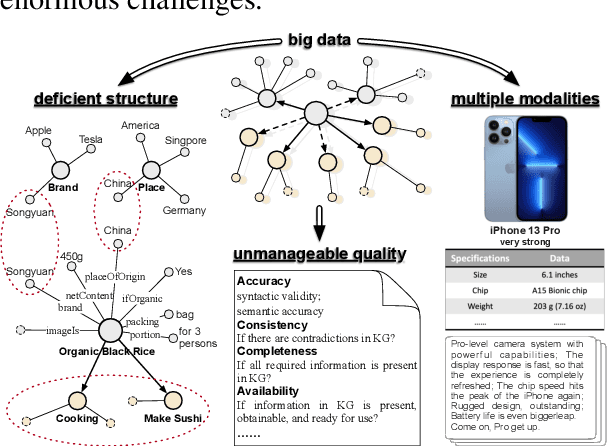

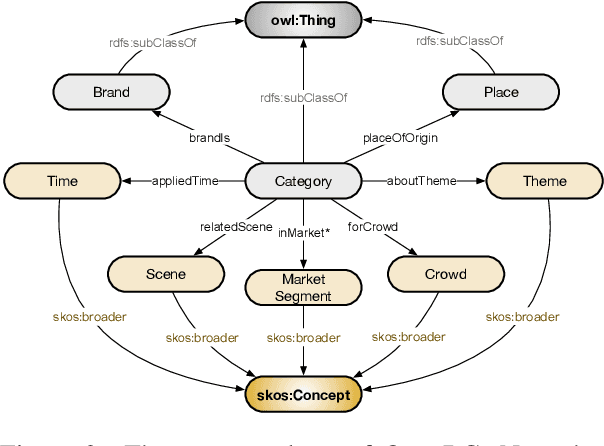
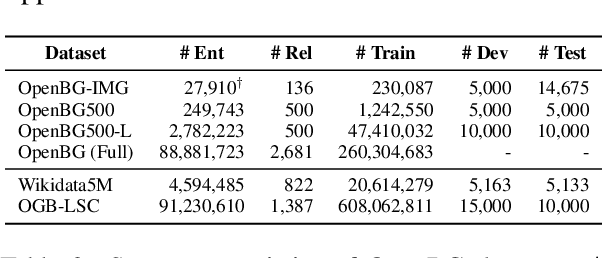
Business Knowledge Graph is important to many enterprises today, providing the factual knowledge and structured data that steer many products and make them more intelligent. Despite the welcome outcome, building business KG brings prohibitive issues of deficient structure, multiple modalities and unmanageable quality. In this paper, we advance the practical challenges related to building KG in non-trivial real-world systems. We introduce the process of building an open business knowledge graph (OpenBG) derived from a well-known enterprise. Specifically, we define a core ontology to cover various abstract products and consumption demands, with fine-grained taxonomy and multi-modal facts in deployed applications. OpenBG is ongoing, and the current version contains more than 2.6 billion triples with more than 88 million entities and 2,681 types of relations. We release all the open resources (OpenBG benchmark) derived from it for the community. We also report benchmark results with best learned lessons \url{https://github.com/OpenBGBenchmark/OpenBG}.
From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer
Feb 08, 2022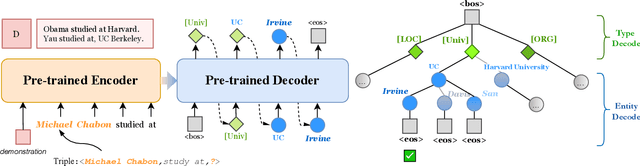

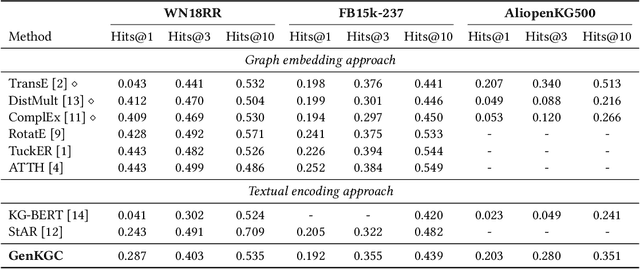
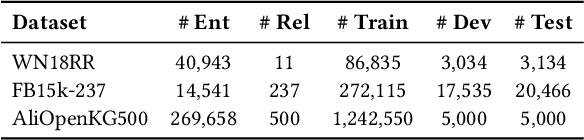
Knowledge graph completion aims to address the problem of extending a KG with missing triples. In this paper, we provide an approach GenKGC, which converts knowledge graph completion to sequence-to-sequence generation task with the pre-trained language model. We further introduce relation-guided demonstration and entity-aware hierarchical decoding for better representation learning and fast inference. Experimental results on three datasets show that our approach can obtain better or comparable performance than baselines and achieve faster inference speed compared with previous methods with pre-trained language models. We also release a new large-scale Chinese knowledge graph dataset AliopenKG500 for research purpose. Code and datasets are available in https://github.com/zjunlp/PromptKGC/tree/main/GenKGC.
LOGEN: Few-shot Logical Knowledge-Conditioned Text Generation with Self-training
Dec 02, 2021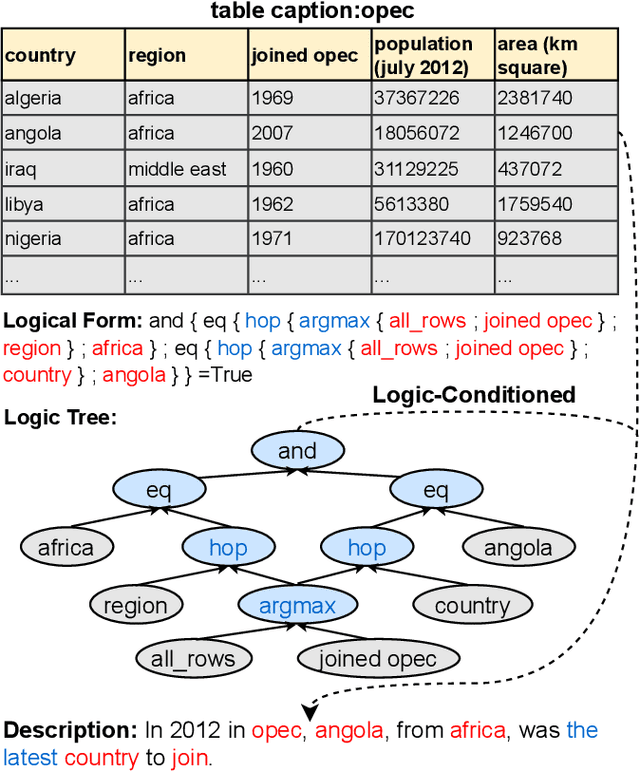
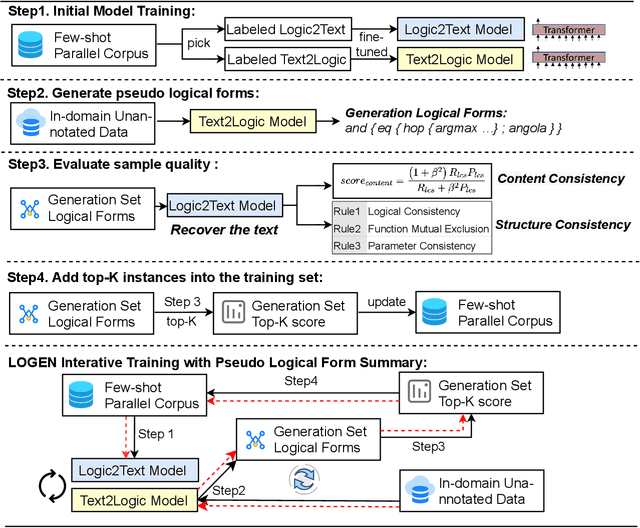
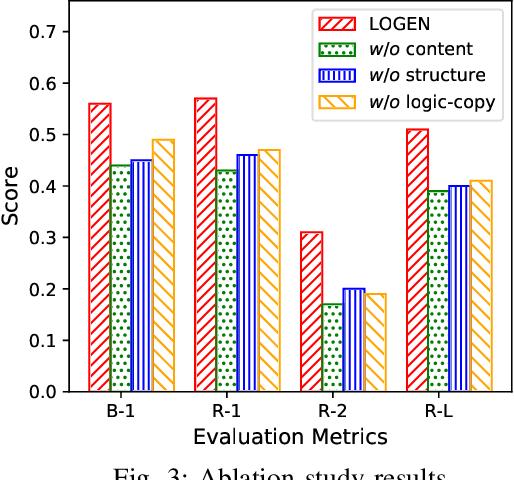

Natural language generation from structured data mainly focuses on surface-level descriptions, suffering from uncontrollable content selection and low fidelity. Previous works leverage logical forms to facilitate logical knowledge-conditioned text generation. Though achieving remarkable progress, they are data-hungry, which makes the adoption for real-world applications challenging with limited data. To this end, this paper proposes a unified framework for logical knowledge-conditioned text generation in the few-shot setting. With only a few seeds logical forms (e.g., 20/100 shot), our approach leverages self-training and samples pseudo logical forms based on content and structure consistency. Experimental results demonstrate that our approach can obtain better few-shot performance than baselines.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021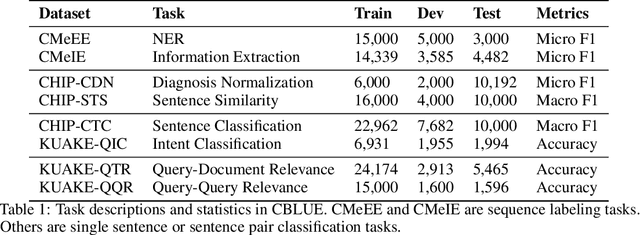
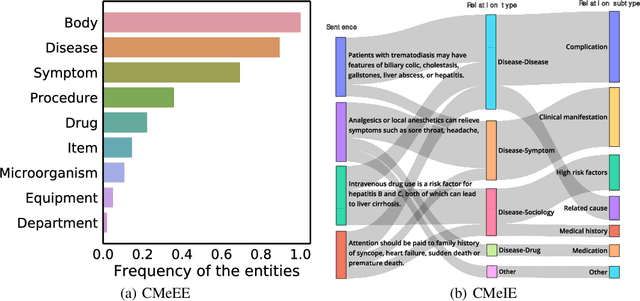
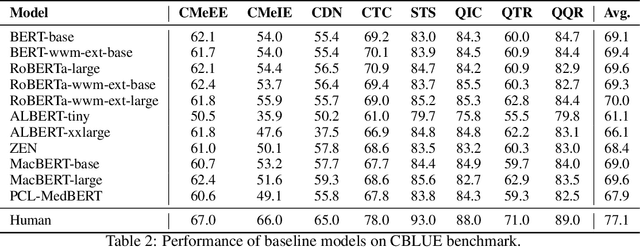
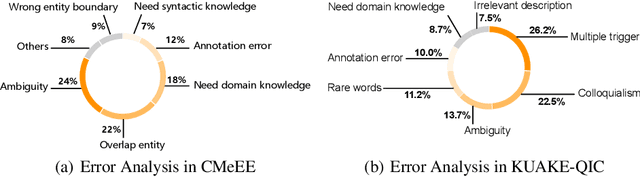
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.
Document-level Relation Extraction as Semantic Segmentation
Jun 07, 2021
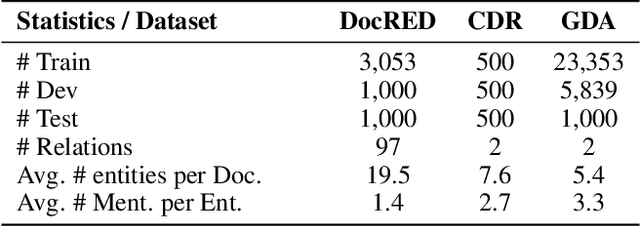
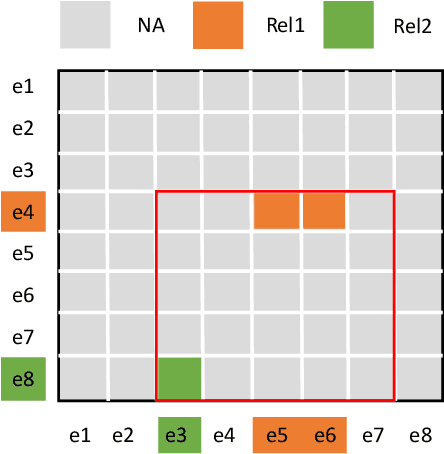
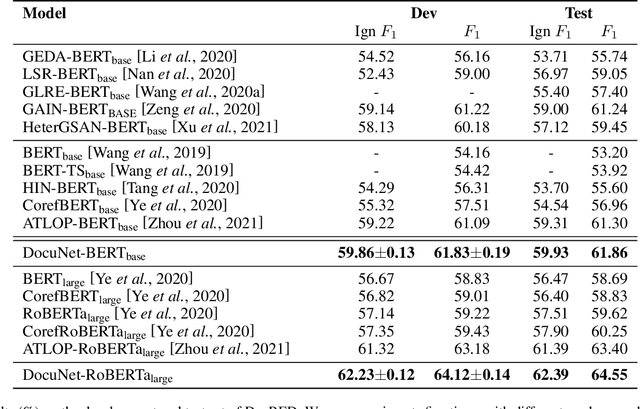
Document-level relation extraction aims to extract relations among multiple entity pairs from a document. Previously proposed graph-based or transformer-based models utilize the entities independently, regardless of global information among relational triples. This paper approaches the problem by predicting an entity-level relation matrix to capture local and global information, parallel to the semantic segmentation task in computer vision. Herein, we propose a Document U-shaped Network for document-level relation extraction. Specifically, we leverage an encoder module to capture the context information of entities and a U-shaped segmentation module over the image-style feature map to capture global interdependency among triples. Experimental results show that our approach can obtain state-of-the-art performance on three benchmark datasets DocRED, CDR, and GDA.
DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
May 31, 2021
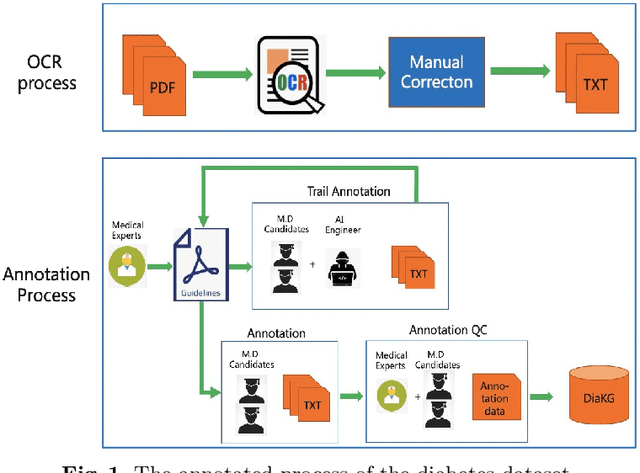

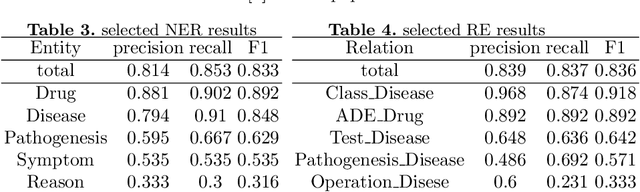
Knowledge Graph has been proven effective in modeling structured information and conceptual knowledge, especially in the medical domain. However, the lack of high-quality annotated corpora remains a crucial problem for advancing the research and applications on this task. In order to accelerate the research for domain-specific knowledge graphs in the medical domain, we introduce DiaKG, a high-quality Chinese dataset for Diabetes knowledge graph, which contains 22,050 entities and 6,890 relations in total. We implement recent typical methods for Named Entity Recognition and Relation Extraction as a benchmark to evaluate the proposed dataset thoroughly. Empirical results show that the DiaKG is challenging for most existing methods and further analysis is conducted to discuss future research direction for improvements. We hope the release of this dataset can assist the construction of diabetes knowledge graphs and facilitate AI-based applications.
OntoED: Low-resource Event Detection with Ontology Embedding
May 27, 2021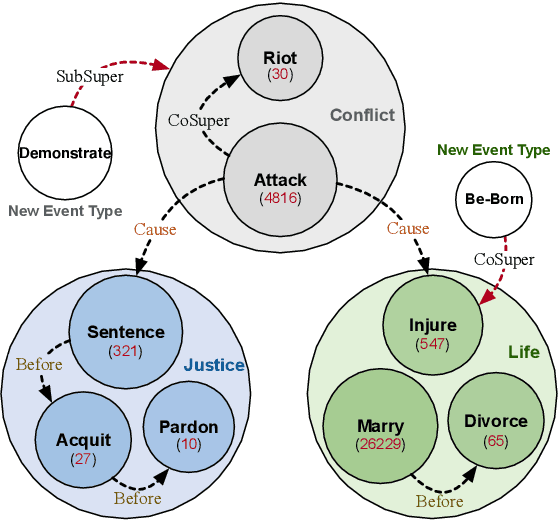

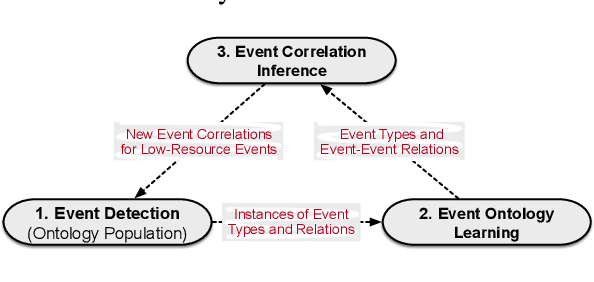

Event Detection (ED) aims to identify event trigger words from a given text and classify it into an event type. Most of current methods to ED rely heavily on training instances, and almost ignore the correlation of event types. Hence, they tend to suffer from data scarcity and fail to handle new unseen event types. To address these problems, we formulate ED as a process of event ontology population: linking event instances to pre-defined event types in event ontology, and propose a novel ED framework entitled OntoED with ontology embedding. We enrich event ontology with linkages among event types, and further induce more event-event correlations. Based on the event ontology, OntoED can leverage and propagate correlation knowledge, particularly from data-rich to data-poor event types. Furthermore, OntoED can be applied to new unseen event types, by establishing linkages to existing ones. Experiments indicate that OntoED is more predominant and robust than previous approaches to ED, especially in data-scarce scenarios.
Noisy-Labeled NER with Confidence Estimation
Apr 12, 2021
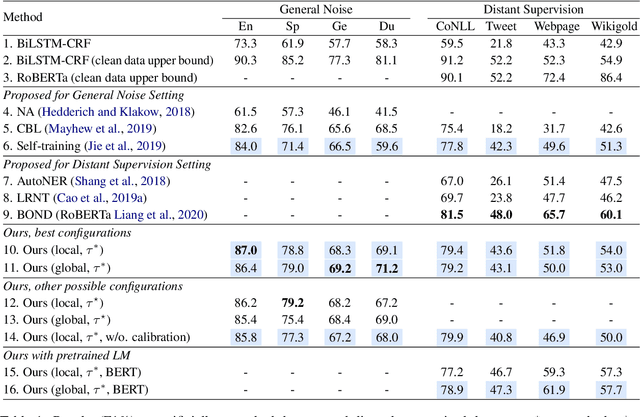
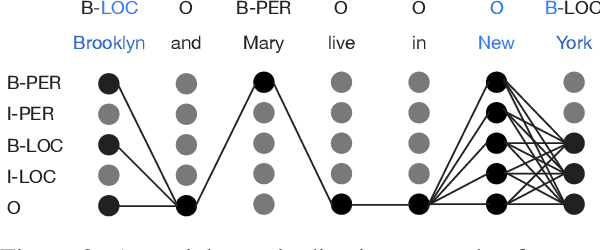
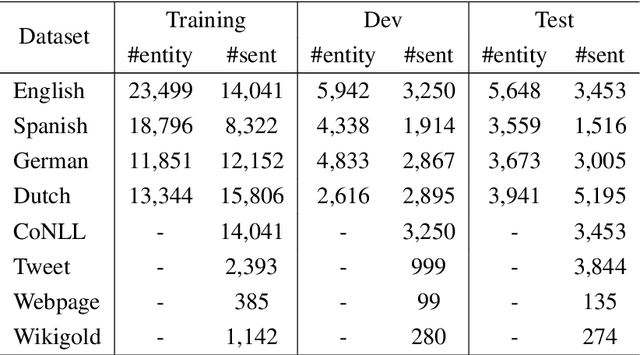
Recent studies in deep learning have shown significant progress in named entity recognition (NER). Most existing works assume clean data annotation, yet a fundamental challenge in real-world scenarios is the large amount of noise from a variety of sources (e.g., pseudo, weak, or distant annotations). This work studies NER under a noisy labeled setting with calibrated confidence estimation. Based on empirical observations of different training dynamics of noisy and clean labels, we propose strategies for estimating confidence scores based on local and global independence assumptions. We partially marginalize out labels of low confidence with a CRF model. We further propose a calibration method for confidence scores based on the structure of entity labels. We integrate our approach into a self-training framework for boosting performance. Experiments in general noisy settings with four languages and distantly labeled settings demonstrate the effectiveness of our method. Our code can be found at https://github.com/liukun95/Noisy-NER-Confidence-Estimation