 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDN:Hybrid Deep-learning and Non-line-of-sight Reconstruction Framework for Photoacoustic Brain Imaging
Aug 21, 2024



Photoacoustic imaging (PAI) combines the high contrast of optical imaging with the deep penetration depth of ultrasonic imaging, showing great potential in cerebrovascular disease detection. However, the ultrasonic wave suffers strong attenuation and multi-scattering when it passes through the skull tissue, resulting in the distortion of the collected photoacoustic (PA) signal. In this paper, inspired by the principles of deep learning and non-line-of-sight (NLOS) imaging, we propose an image reconstruction framework named HDN (Hybrid Deep-learning and Non-line-of-sight), which consists of the signal extraction part and difference utilization part. The signal extraction part is used to correct the distorted signal and reconstruct an initial image. The difference utilization part is used to make further use of the signal difference between the distorted signal and corrected signal, reconstructing the residual image between the initial image and the target image. The test results on a PA digital brain simulation dataset show that compared with the traditional delay-and-sum (DAS) method and deep-learning-based method, HDN achieved superior performance in both signal correction and image reconstruction. Specifically for the SSIM index, the HDN reached 0.606 in imaging results, compared to 0.154 for the DAS method and 0.307 for the deep-learning-based method.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021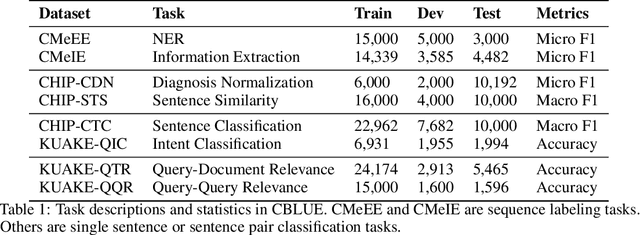
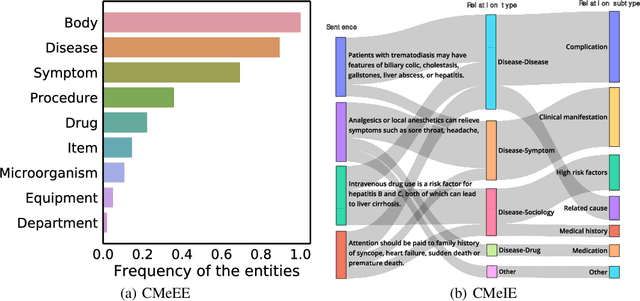
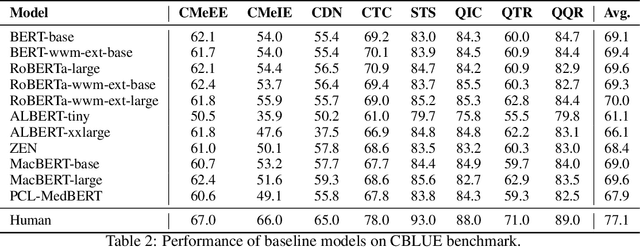
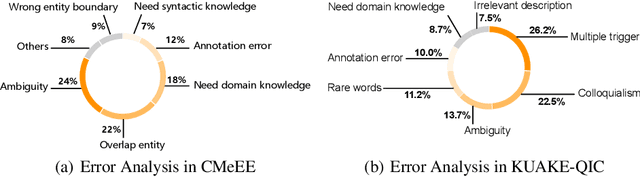
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.