 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Multimodal Large Language Model Editing via Invariant Trajectory Learning
Jan 30, 2026Knowledge editing emerges as a crucial technique for efficiently correcting incorrect or outdated knowledge in large language models (LLM). Existing editing methods rely on a rigid mapping from parameter or module modifications to output, which causes the generalization limitation in Multimodal LLM (MLLM). In this paper, we reformulate MLLM editing as an out-of-distribution (OOD) generalization problem, where the goal is to discern semantic shift with factual shift and thus achieve robust editing among diverse cross-modal prompting. The key challenge of this OOD problem lies in identifying invariant causal trajectories that generalize accurately while suppressing spurious correlations. To address it, we propose ODEdit, a plug-and-play invariant learning based framework that optimizes the tripartite OOD risk objective to simultaneously enhance editing reliability, locality, and generality.We further introduce an edit trajectory invariant learning method, which integrates a total variation penalty into the risk minimization objective to stabilize edit trajectories against environmental variations. Theoretical analysis and extensive experiments demonstrate the effectiveness of ODEdit.
Potent but Stealthy: Rethink Profile Pollution against Sequential Recommendation via Bi-level Constrained Reinforcement Paradigm
Nov 14, 2025Sequential Recommenders, which exploit dynamic user intents through interaction sequences, is vulnerable to adversarial attacks. While existing attacks primarily rely on data poisoning, they require large-scale user access or fake profiles thus lacking practicality. In this paper, we focus on the Profile Pollution Attack that subtly contaminates partial user interactions to induce targeted mispredictions. Previous PPA methods suffer from two limitations, i.e., i) over-reliance on sequence horizon impact restricts fine-grained perturbations on item transitions, and ii) holistic modifications cause detectable distribution shifts. To address these challenges, we propose a constrained reinforcement driven attack CREAT that synergizes a bi-level optimization framework with multi-reward reinforcement learning to balance adversarial efficacy and stealthiness. We first develop a Pattern Balanced Rewarding Policy, which integrates pattern inversion rewards to invert critical patterns and distribution consistency rewards to minimize detectable shifts via unbalanced co-optimal transport. Then we employ a Constrained Group Relative Reinforcement Learning paradigm, enabling step-wise perturbations through dynamic barrier constraints and group-shared experience replay, achieving targeted pollution with minimal detectability. Extensive experiments demonstrate the effectiveness of CREAT.
FedFACT: A Provable Framework for Controllable Group-Fairness Calibration in Federated Learning
Jun 04, 2025



With emerging application of Federated Learning (FL) in decision-making scenarios, it is imperative to regulate model fairness to prevent disparities across sensitive groups (e.g., female, male). Current research predominantly focuses on two concepts of group fairness within FL: Global Fairness (overall model disparity across all clients) and Local Fairness (the disparity within each client). However, the non-decomposable, non-differentiable nature of fairness criteria pose two fundamental, unresolved challenges for fair FL: (i) Harmonizing global and local fairness in multi-class classification; (ii) Enabling a controllable, optimal accuracy-fairness trade-off. To tackle the aforementioned challenges, we propose a novel controllable federated group-fairness calibration framework, named FedFACT. FedFACT identifies the Bayes-optimal classifiers under both global and local fairness constraints in multi-class case, yielding models with minimal performance decline while guaranteeing fairness. To effectively realize an adjustable, optimal accuracy-fairness balance, we derive specific characterizations of the Bayes-optimal fair classifiers for reformulating fair FL as personalized cost-sensitive learning problem for in-processing, and bi-level optimization for post-processing. Theoretically, we provide convergence and generalization guarantees for FedFACT to approach the near-optimal accuracy under given fairness levels. Extensive experiments on multiple datasets across various data heterogeneity demonstrate that FedFACT consistently outperforms baselines in balancing accuracy and global-local fairness.
RAID: An In-Training Defense against Attribute Inference Attacks in Recommender Systems
Apr 15, 2025In various networks and mobile applications, users are highly susceptible to attribute inference attacks, with particularly prevalent occurrences in recommender systems. Attackers exploit partially exposed user profiles in recommendation models, such as user embeddings, to infer private attributes of target users, such as gender and political views. The goal of defenders is to mitigate the effectiveness of these attacks while maintaining recommendation performance. Most existing defense methods, such as differential privacy and attribute unlearning, focus on post-training settings, which limits their capability of utilizing training data to preserve recommendation performance. Although adversarial training extends defenses to in-training settings, it often struggles with convergence due to unstable training processes. In this paper, we propose RAID, an in-training defense method against attribute inference attacks in recommender systems. In addition to the recommendation objective, we define a defensive objective to ensure that the distribution of protected attributes becomes independent of class labels, making users indistinguishable from attribute inference attacks. Specifically, this defensive objective aims to solve a constrained Wasserstein barycenter problem to identify the centroid distribution that makes the attribute indistinguishable while complying with recommendation performance constraints. To optimize our proposed objective, we use optimal transport to align users with the centroid distribution. We conduct extensive experiments on four real-world datasets to evaluate RAID. The experimental results validate the effectiveness of RAID and demonstrate its significant superiority over existing methods in multiple aspects.
Bridging the Gap Between Preference Alignment and Machine Unlearning
Apr 09, 2025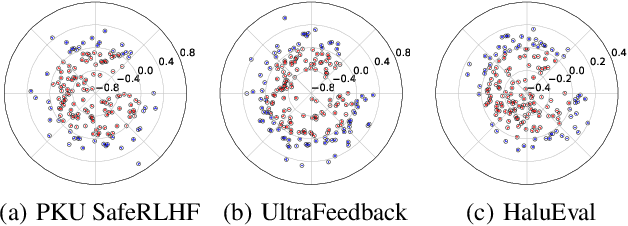
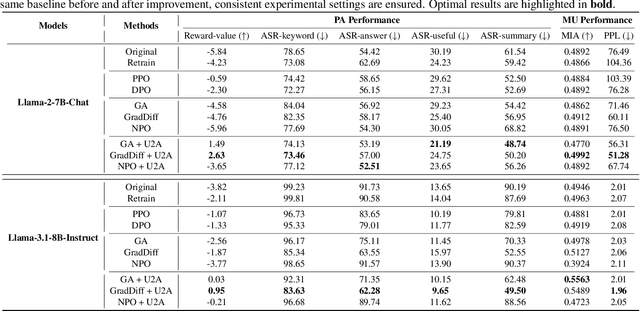
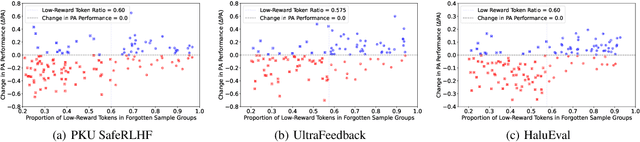

Despite advances in Preference Alignment (PA) for Large Language Models (LLMs), mainstream methods like Reinforcement Learning with Human Feedback (RLHF) face notable challenges. These approaches require high-quality datasets of positive preference examples, which are costly to obtain and computationally intensive due to training instability, limiting their use in low-resource scenarios. LLM unlearning technique presents a promising alternative, by directly removing the influence of negative examples. However, current research has primarily focused on empirical validation, lacking systematic quantitative analysis. To bridge this gap, we propose a framework to explore the relationship between PA and LLM unlearning. Specifically, we introduce a bi-level optimization-based method to quantify the impact of unlearning specific negative examples on PA performance. Our analysis reveals that not all negative examples contribute equally to alignment improvement when unlearned, and the effect varies significantly across examples. Building on this insight, we pose a crucial question: how can we optimally select and weight negative examples for unlearning to maximize PA performance? To answer this, we propose a framework called Unlearning to Align (U2A), which leverages bi-level optimization to efficiently select and unlearn examples for optimal PA performance. We validate the proposed method through extensive experiments, with results confirming its effectiveness.
A Neuro-inspired Interpretation of Unlearning in Large Language Models through Sample-level Unlearning Difficulty
Apr 09, 2025Driven by privacy protection laws and regulations, unlearning in Large Language Models (LLMs) is gaining increasing attention. However, current research often neglects the interpretability of the unlearning process, particularly concerning sample-level unlearning difficulty. Existing studies typically assume a uniform unlearning difficulty across samples. This simplification risks attributing the performance of unlearning algorithms to sample selection rather than the algorithm's design, potentially steering the development of LLM unlearning in the wrong direction. Thus, we investigate the relationship between LLM unlearning and sample characteristics, with a focus on unlearning difficulty. Drawing inspiration from neuroscience, we propose a Memory Removal Difficulty ($\mathrm{MRD}$) metric to quantify sample-level unlearning difficulty. Using $\mathrm{MRD}$, we analyze the characteristics of hard-to-unlearn versus easy-to-unlearn samples. Furthermore, we propose an $\mathrm{MRD}$-based weighted sampling method to optimize existing unlearning algorithms, which prioritizes easily forgettable samples, thereby improving unlearning efficiency and effectiveness. We validate the proposed metric and method using public benchmarks and datasets, with results confirming its effectiveness.
A Survey on Recommendation Unlearning: Fundamentals, Taxonomy, Evaluation, and Open Questions
Dec 17, 2024



Recommender systems have become increasingly influential in shaping user behavior and decision-making, highlighting their growing impact in various domains. Meanwhile, the widespread adoption of machine learning models in recommender systems has raised significant concerns regarding user privacy and security. As compliance with privacy regulations becomes more critical, there is a pressing need to address the issue of recommendation unlearning, i.e., eliminating the memory of specific training data from the learned recommendation models. Despite its importance, traditional machine unlearning methods are ill-suited for recommendation unlearning due to the unique challenges posed by collaborative interactions and model parameters. This survey offers a comprehensive review of the latest advancements in recommendation unlearning, exploring the design principles, challenges, and methodologies associated with this emerging field. We provide a unified taxonomy that categorizes different recommendation unlearning approaches, followed by a summary of widely used benchmarks and metrics for evaluation. By reviewing the current state of research, this survey aims to guide the development of more efficient, scalable, and robust recommendation unlearning techniques. Furthermore, we identify open research questions in this field, which could pave the way for future innovations not only in recommendation unlearning but also in a broader range of unlearning tasks across different machine learning applications.
Single picture single photon single pixel 3D imaging through unknown thick scattering medium
Oct 08, 2024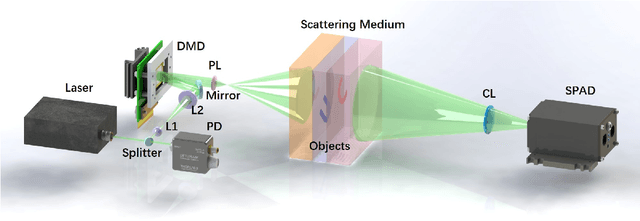

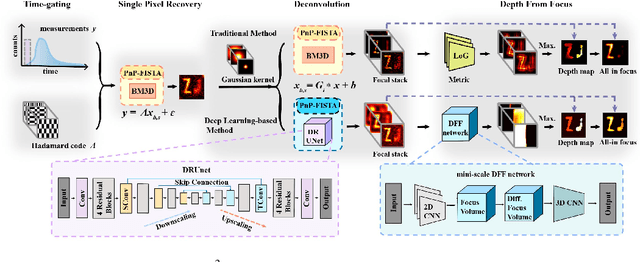
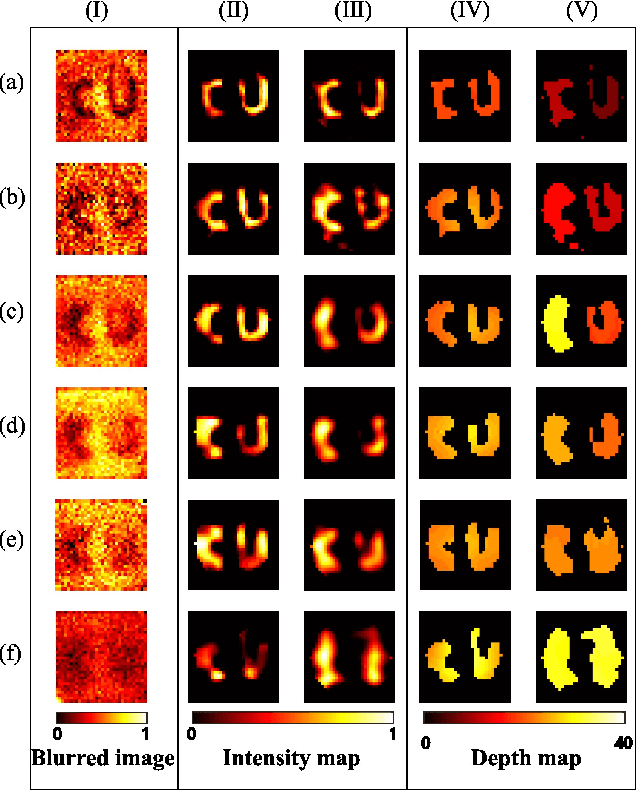
Imaging through thick scattering media presents significant challenges, particularly for three-dimensional (3D) applications. This manuscript demonstrates a novel scheme for single-image-enabled 3D imaging through such media, treating the scattering medium as a lens. This approach captures a comprehensive image containing information about objects hidden at various depths. By leveraging depth from focus and the reduced thickness of the scattering medium for single-pixel imaging, the proposed method ensures robust 3D imaging capabilities. We develop both traditional metric-based and deep learning-based methods to extract depth information for each pixel, allowing us to explore the locations of both positive and negative objects, whether shallow or deep. Remarkably, this scheme enables the simultaneous 3D reconstruction of targets concealed within the scattering medium. Specifically, we successfully reconstructed targets buried at depths of 5 mm and 30 mm within a total medium thickness of 60 mm. Additionally, we can effectively distinguish targets at three different depths. Notably, this scheme requires no prior knowledge of the scattering medium, no invasive procedures, reference measurements, or calibration.
HDN:Hybrid Deep-learning and Non-line-of-sight Reconstruction Framework for Photoacoustic Brain Imaging
Aug 21, 2024



Photoacoustic imaging (PAI) combines the high contrast of optical imaging with the deep penetration depth of ultrasonic imaging, showing great potential in cerebrovascular disease detection. However, the ultrasonic wave suffers strong attenuation and multi-scattering when it passes through the skull tissue, resulting in the distortion of the collected photoacoustic (PA) signal. In this paper, inspired by the principles of deep learning and non-line-of-sight (NLOS) imaging, we propose an image reconstruction framework named HDN (Hybrid Deep-learning and Non-line-of-sight), which consists of the signal extraction part and difference utilization part. The signal extraction part is used to correct the distorted signal and reconstruct an initial image. The difference utilization part is used to make further use of the signal difference between the distorted signal and corrected signal, reconstructing the residual image between the initial image and the target image. The test results on a PA digital brain simulation dataset show that compared with the traditional delay-and-sum (DAS) method and deep-learning-based method, HDN achieved superior performance in both signal correction and image reconstruction. Specifically for the SSIM index, the HDN reached 0.606 in imaging results, compared to 0.154 for the DAS method and 0.307 for the deep-learning-based method.
Controllable Unlearning for Image-to-Image Generative Models via $\varepsilon$-Constrained Optimization
Aug 03, 2024



While generative models have made significant advancements in recent years, they also raise concerns such as privacy breaches and biases. Machine unlearning has emerged as a viable solution, aiming to remove specific training data, e.g., containing private information and bias, from models. In this paper, we study the machine unlearning problem in Image-to-Image (I2I) generative models. Previous studies mainly treat it as a single objective optimization problem, offering a solitary solution, thereby neglecting the varied user expectations towards the trade-off between complete unlearning and model utility. To address this issue, we propose a controllable unlearning framework that uses a control coefficient $\varepsilon$ to control the trade-off. We reformulate the I2I generative model unlearning problem into a $\varepsilon$-constrained optimization problem and solve it with a gradient-based method to find optimal solutions for unlearning boundaries. These boundaries define the valid range for the control coefficient. Within this range, every yielded solution is theoretically guaranteed with Pareto optimality. We also analyze the convergence rate of our framework under various control functions. Extensive experiments on two benchmark datasets across three mainstream I2I models demonstrate the effectiveness of our controllable unlearning framework.