 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Pitfalls of Knowledge Editing for Large Language Models
Oct 03, 2023



As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code will be released at https://github.com/zjunlp/PitfallsKnowledgeEditing.
Editing Large Language Models: Problems, Methods, and Opportunities
May 22, 2023Recent advancements in deep learning have precipitated the emergence of large language models (LLMs) which exhibit an impressive aptitude for understanding and producing text akin to human language. Despite the ability to train highly capable LLMs, the methodology for maintaining their relevancy and rectifying errors remains elusive. To that end, the past few years have witnessed a surge in techniques for editing LLMs, the objective of which is to alter the behavior of LLMs within a specific domain without negatively impacting performance across other inputs. This paper embarks on a deep exploration of the problems, methods, and opportunities relating to model editing for LLMs. In particular, we provide an exhaustive overview of the task definition and challenges associated with model editing, along with an in-depth empirical analysis of the most progressive methods currently at our disposal. We also build a new benchmark dataset to facilitate a more robust evaluation and pinpoint enduring issues intrinsic to existing techniques. Our objective is to provide valuable insights into the effectiveness and feasibility of each model editing technique, thereby assisting the research community in making informed decisions when choosing the most appropriate method for a specific task or context. Code and datasets will be available at https://github.com/zjunlp/EasyEdit.
PromptKG: A Prompt Learning Framework for Knowledge Graph Representation Learning and Application
Oct 01, 2022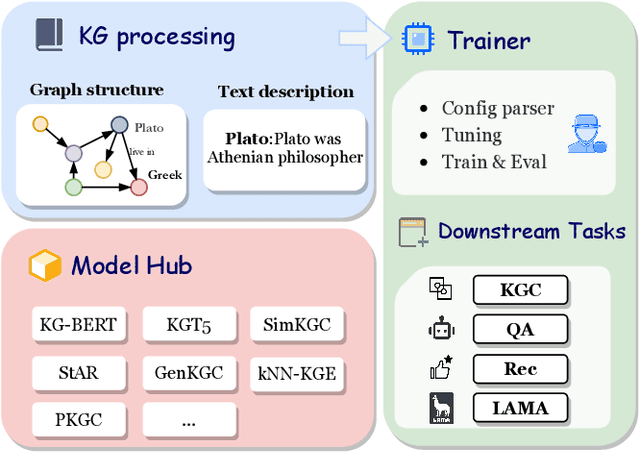



Knowledge Graphs (KGs) often have two characteristics: heterogeneous graph structure and text-rich entity/relation information. KG representation models should consider graph structures and text semantics, but no comprehensive open-sourced framework is mainly designed for KG regarding informative text description. In this paper, we present PromptKG, a prompt learning framework for KG representation learning and application that equips the cutting-edge text-based methods, integrates a new prompt learning model and supports various tasks (e.g., knowledge graph completion, question answering, recommendation, and knowledge probing). PromptKG is publicly open-sourced at https://github.com/zjunlp/PromptKG with long-term technical support.
Construction and Applications of Open Business Knowledge Graph
Sep 30, 2022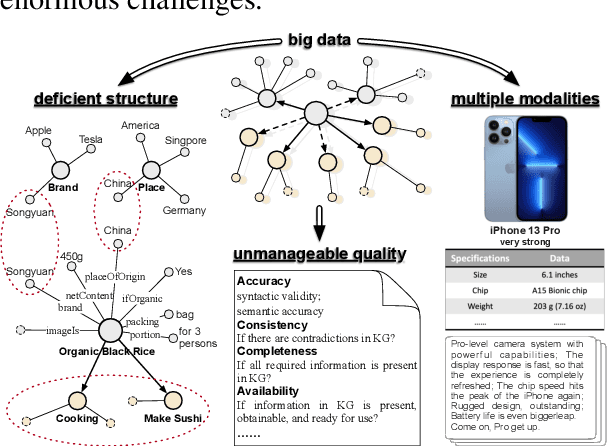

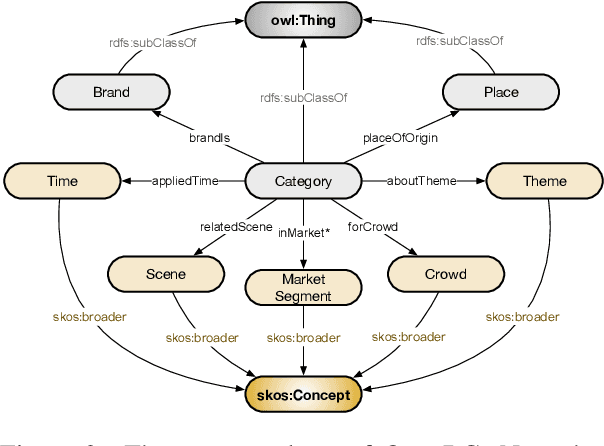
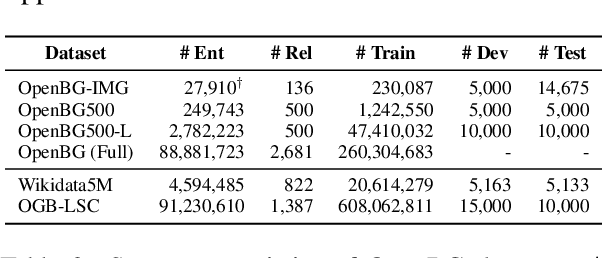
Business Knowledge Graph is important to many enterprises today, providing the factual knowledge and structured data that steer many products and make them more intelligent. Despite the welcome outcome, building business KG brings prohibitive issues of deficient structure, multiple modalities and unmanageable quality. In this paper, we advance the practical challenges related to building KG in non-trivial real-world systems. We introduce the process of building an open business knowledge graph (OpenBG) derived from a well-known enterprise. Specifically, we define a core ontology to cover various abstract products and consumption demands, with fine-grained taxonomy and multi-modal facts in deployed applications. OpenBG is ongoing, and the current version contains more than 2.6 billion triples with more than 88 million entities and 2,681 types of relations. We release all the open resources (OpenBG benchmark) derived from it for the community. We also report benchmark results with best learned lessons \url{https://github.com/OpenBGBenchmark/OpenBG}.
From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer
Feb 08, 2022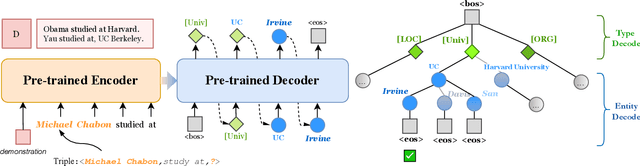

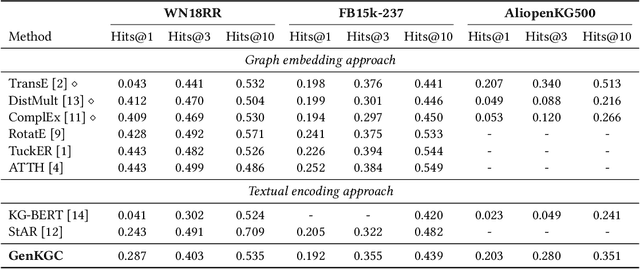
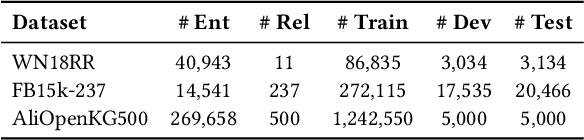
Knowledge graph completion aims to address the problem of extending a KG with missing triples. In this paper, we provide an approach GenKGC, which converts knowledge graph completion to sequence-to-sequence generation task with the pre-trained language model. We further introduce relation-guided demonstration and entity-aware hierarchical decoding for better representation learning and fast inference. Experimental results on three datasets show that our approach can obtain better or comparable performance than baselines and achieve faster inference speed compared with previous methods with pre-trained language models. We also release a new large-scale Chinese knowledge graph dataset AliopenKG500 for research purpose. Code and datasets are available in https://github.com/zjunlp/PromptKGC/tree/main/GenKGC.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
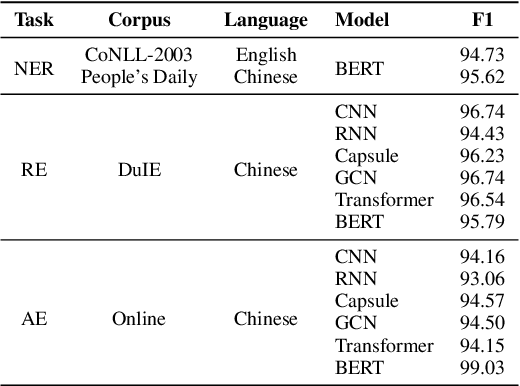
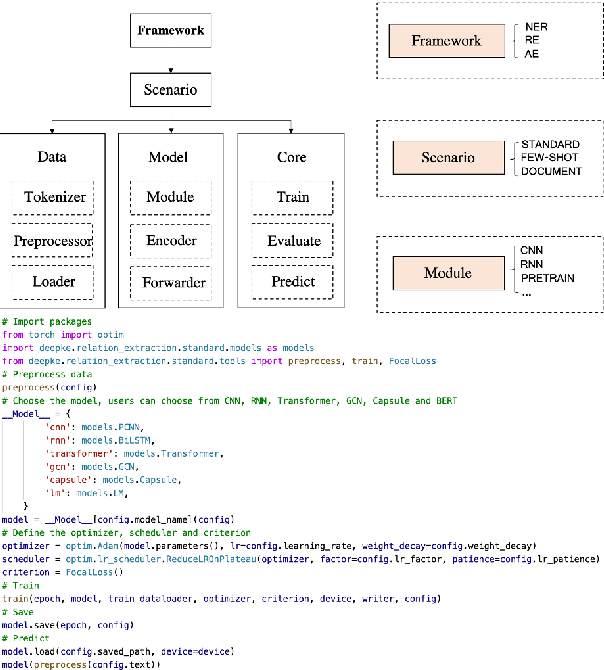
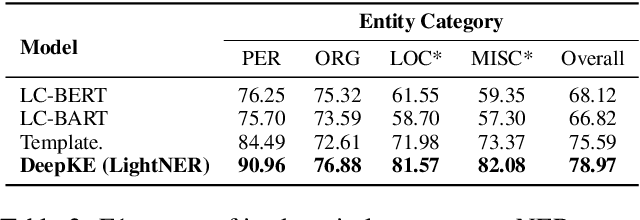
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.