 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
Aug 31, 2021


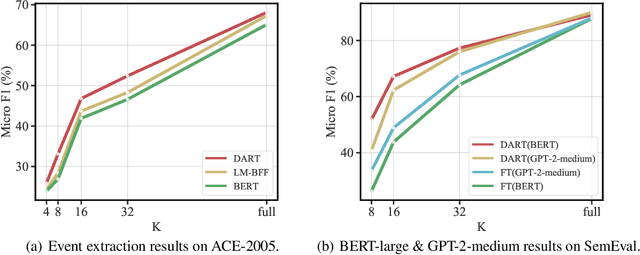
Large-scale pre-trained language models have contributed significantly to natural language processing by demonstrating remarkable abilities as few-shot learners. However, their effectiveness depends mainly on scaling the model parameters and prompt design, hindering their implementation in most real-world applications. This study proposes a novel pluggable, extensible, and efficient approach named DifferentiAble pRompT (DART), which can convert small language models into better few-shot learners without any prompt engineering. The main principle behind this approach involves reformulating potential natural language processing tasks into the task of a pre-trained language model and differentially optimizing the prompt template as well as the target label with backpropagation. Furthermore, the proposed approach can be: (i) Plugged to any pre-trained language models; (ii) Extended to widespread classification tasks. A comprehensive evaluation of standard NLP tasks demonstrates that the proposed approach achieves a better few-shot performance.
OntoED: Low-resource Event Detection with Ontology Embedding
May 27, 2021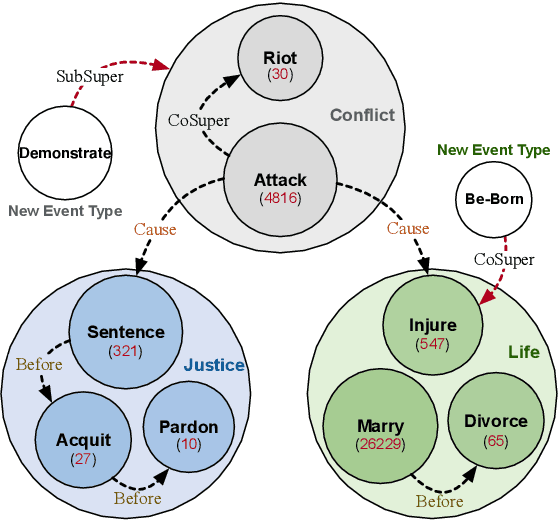

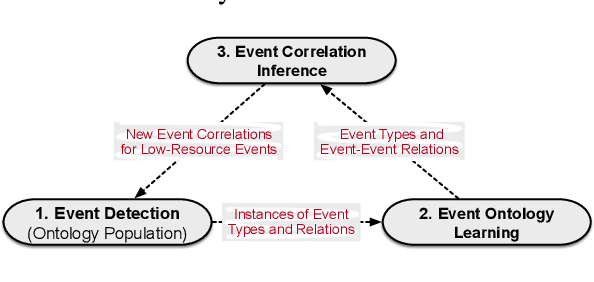

Event Detection (ED) aims to identify event trigger words from a given text and classify it into an event type. Most of current methods to ED rely heavily on training instances, and almost ignore the correlation of event types. Hence, they tend to suffer from data scarcity and fail to handle new unseen event types. To address these problems, we formulate ED as a process of event ontology population: linking event instances to pre-defined event types in event ontology, and propose a novel ED framework entitled OntoED with ontology embedding. We enrich event ontology with linkages among event types, and further induce more event-event correlations. Based on the event ontology, OntoED can leverage and propagate correlation knowledge, particularly from data-rich to data-poor event types. Furthermore, OntoED can be applied to new unseen event types, by establishing linkages to existing ones. Experiments indicate that OntoED is more predominant and robust than previous approaches to ED, especially in data-scarce scenarios.
Normal vs. Adversarial: Salience-based Analysis of Adversarial Samples for Relation Extraction
Apr 11, 2021



Recent neural-based relation extraction approaches, though achieving promising improvement on benchmark datasets, have reported their vulnerability towards adversarial attacks. Thus far, efforts mostly focused on generating adversarial samples or defending adversarial attacks, but little is known about the difference between normal and adversarial samples. In this work, we take the first step to leverage the salience-based method to analyze those adversarial samples. We observe that salience tokens have a direct correlation with adversarial perturbations. We further find the adversarial perturbations are either those tokens not existing in the training set or superficial cues associated with relation labels. To some extent, our approach unveils the characters against adversarial samples. We release an open-source testbed, "DiagnoseAdv".
Text-guided Legal Knowledge Graph Reasoning
Apr 06, 2021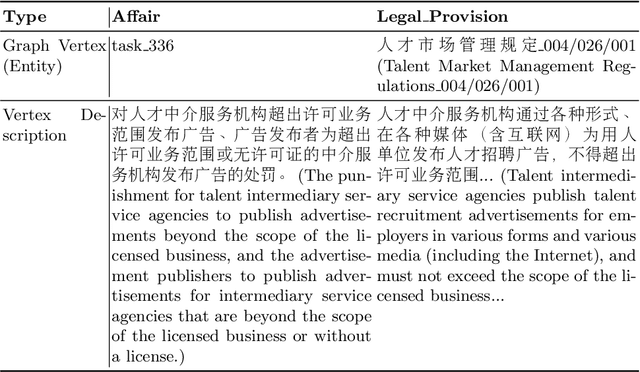
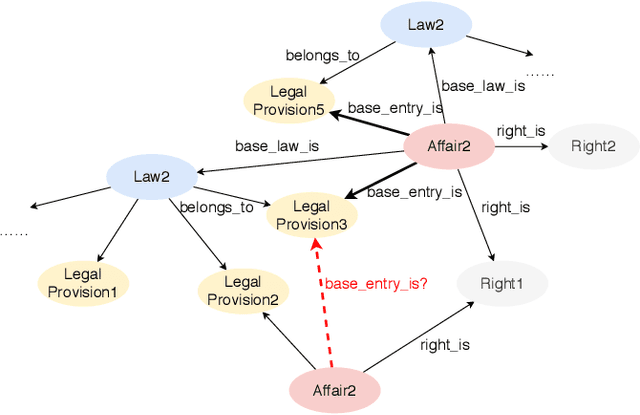

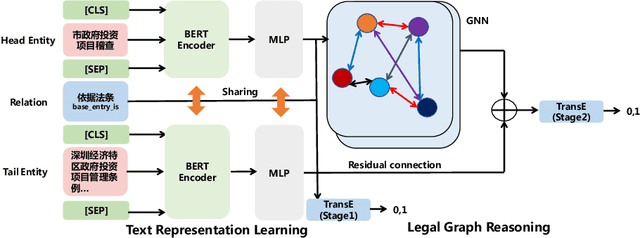
Recent years have witnessed the prosperity of legal artificial intelligence with the development of technologies. In this paper, we propose a novel legal application of legal provision prediction (LPP), which aims to predict the related legal provisions of affairs. We formulate this task as a challenging knowledge graph completion problem, which requires not only text understanding but also graph reasoning. To this end, we propose a novel text-guided graph reasoning approach. We collect amounts of real-world legal provision data from the Guangdong government service website and construct a legal dataset called LegalLPP. Extensive experimental results on the dataset show that our approach achieves better performance compared with baselines. The code and dataset are available in \url{https://github.com/zjunlp/LegalPP} for reproducibility.
Can Fine-tuning Pre-trained Models Lead to Perfect NLP? A Study of the Generalizability of Relation Extraction
Sep 23, 2020


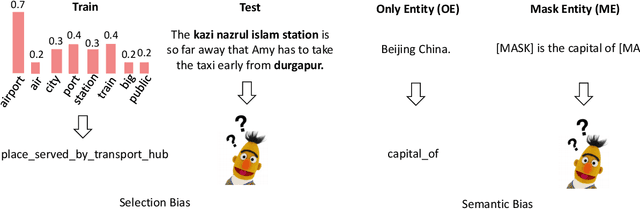
Fine-tuning pre-trained models have achieved impressive performance on standard natural language processing benchmarks. However, the resultant model generalizability remains poorly understood. We do not know, for example, how excellent performance can lead to the perfection of generalization models. In this study, we analyze a fine-tuned BERT model from different perspectives using relation extraction. We also characterize the differences in generalization techniques according to our proposed improvements. From empirical experimentation, we find that BERT suffers a bottleneck in terms of robustness by way of randomizations, adversarial and counterfactual tests, and biases (i.e., selection and semantic). These findings highlight opportunities for future improvements. Our open-sourced testbed DiagnoseRE is available in https://github.com/zjunlp/DiagnoseRE/.