 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
May 13, 2026Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
Neuron-Aware Data Selection In Instruction Tuning For Large Language Models
Mar 13, 2026Instruction Tuning (IT) has been proven to be an effective approach to unlock the powerful capabilities of large language models (LLMs). Recent studies indicate that excessive IT data can degrade LLMs performance, while carefully selecting a small subset of high-quality IT data can significantly enhance their capabilities. Therefore, identifying the most efficient subset data from the IT dataset to effectively develop either specific or general abilities in LLMs has become a critical challenge. To address this, we propose a novel and efficient framework called NAIT. NAIT evaluates the impact of IT data on LLMs performance by analyzing the similarity of neuron activation patterns between the IT dataset and the target domain capability. Specifically, NAIT captures neuron activation patterns from in-domain datasets of target domain capabilities to construct reusable and transferable neuron activation features. It then evaluates and selects optimal samples based on the similarity between candidate samples and the expected activation features of the target capabilities. Experimental results show that training on the 10\% Alpaca-GPT4 IT data subset selected by NAIT consistently outperforms methods that rely on external advanced models or uncertainty-based features across various tasks. Our findings also reveal the transferability of neuron activation features across different capabilities of LLMs. In particular, IT data with more logical reasoning and programmatic features possesses strong general transferability, enabling models to develop stronger capabilities across multiple tasks, while a stable core subset of data is sufficient to consistently activate fundamental model capabilities and universally improve performance across diverse tasks.
Are Large Reasoning Models Good Translation Evaluators? Analysis and Performance Boost
Oct 23, 2025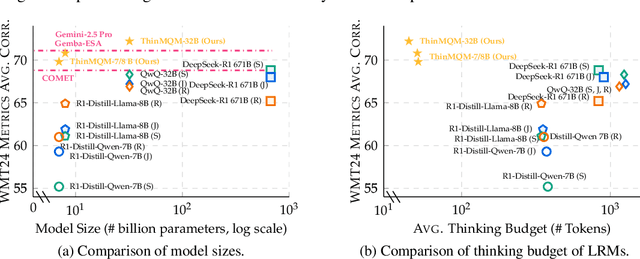
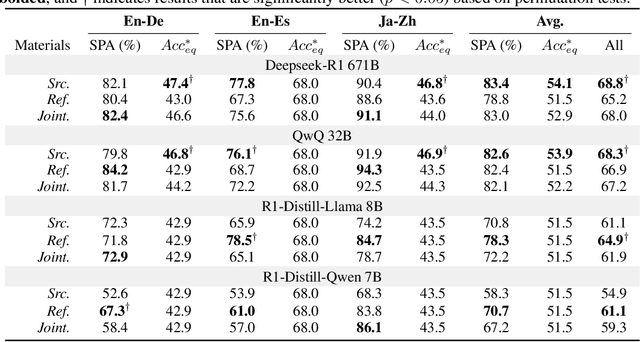
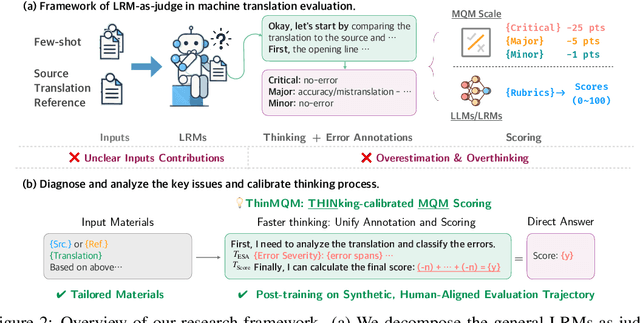

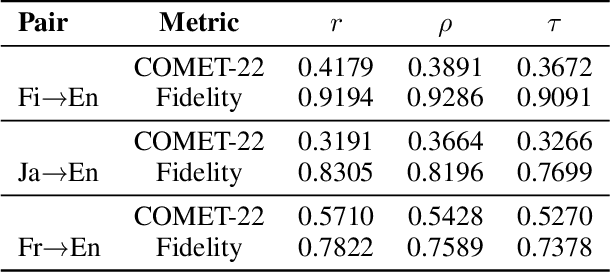
Recent advancements in large reasoning models (LRMs) have introduced an intermediate "thinking" process prior to generating final answers, improving their reasoning capabilities on complex downstream tasks. However, the potential of LRMs as evaluators for machine translation (MT) quality remains underexplored. We provides the first systematic analysis of LRM-as-a-judge in MT evaluation. We identify key challenges, revealing LRMs require tailored evaluation materials, tend to "overthink" simpler instances and have issues with scoring mechanisms leading to overestimation. To address these, we propose to calibrate LRM thinking by training them on synthetic, human-like thinking trajectories. Our experiments on WMT24 Metrics benchmarks demonstrate that this approach largely reduces thinking budgets by ~35x while concurrently improving evaluation performance across different LRM scales from 7B to 32B (e.g., R1-Distill-Qwen-7B achieves a +8.7 correlation point improvement). These findings highlight the potential of efficiently calibrated LRMs to advance fine-grained automatic MT evaluation.
ExGRPO: Learning to Reason from Experience
Oct 02, 2025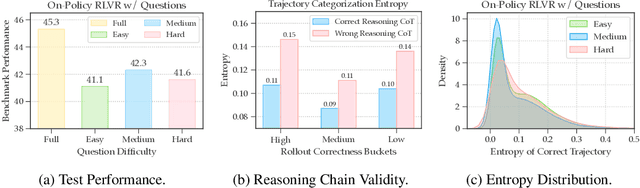
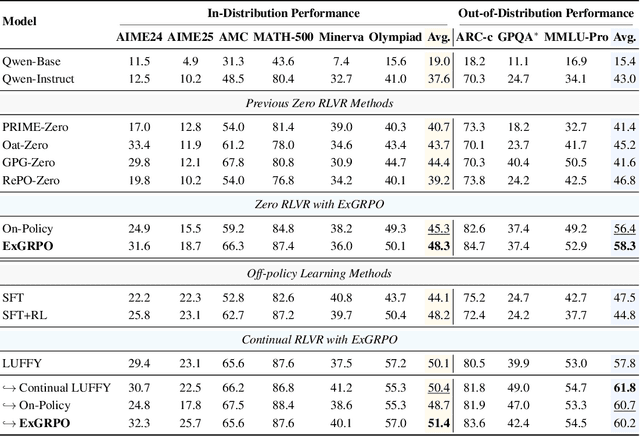
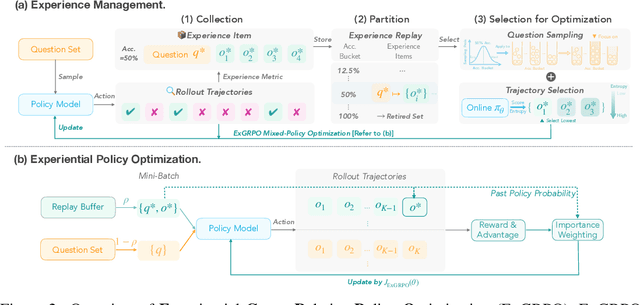
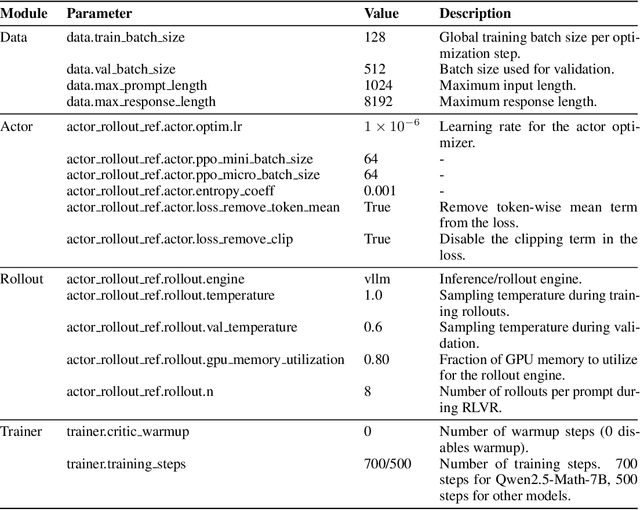
Reinforcement learning from verifiable rewards (RLVR) is an emerging paradigm for improving the reasoning ability of large language models. However, standard on-policy training discards rollout experiences after a single update, leading to computational inefficiency and instability. While prior work on RL has highlighted the benefits of reusing past experience, the role of experience characteristics in shaping learning dynamics of large reasoning models remains underexplored. In this paper, we are the first to investigate what makes a reasoning experience valuable and identify rollout correctness and entropy as effective indicators of experience value. Based on these insights, we propose ExGRPO (Experiential Group Relative Policy Optimization), a framework that organizes and prioritizes valuable experiences, and employs a mixed-policy objective to balance exploration with experience exploitation. Experiments on five backbone models (1.5B-8B parameters) show that ExGRPO consistently improves reasoning performance on mathematical/general benchmarks, with an average gain of +3.5/7.6 points over on-policy RLVR. Moreover, ExGRPO stabilizes training on both stronger and weaker models where on-policy methods fail. These results highlight principled experience management as a key ingredient for efficient and scalable RLVR.
Exposing the Cracks: Vulnerabilities of Retrieval-Augmented LLM-based Machine Translation
Oct 01, 2025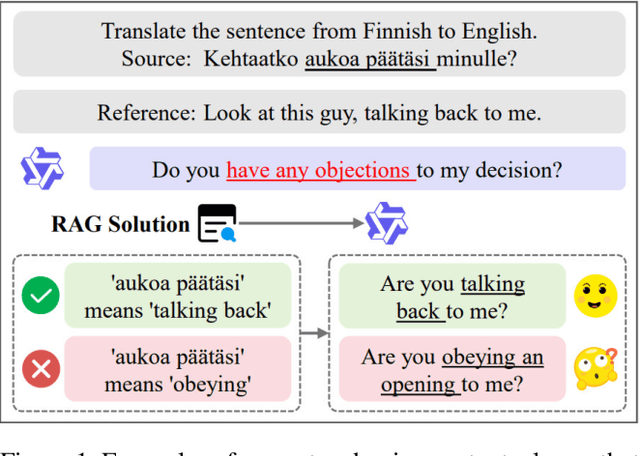

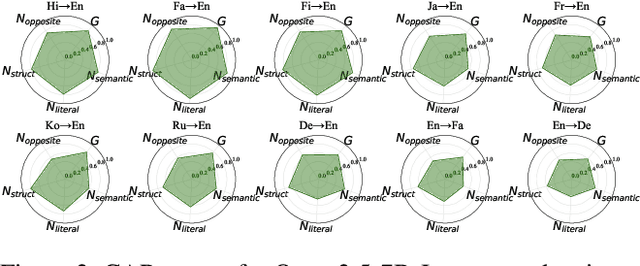
\textbf{RE}trieval-\textbf{A}ugmented \textbf{L}LM-based \textbf{M}achine \textbf{T}ranslation (REAL-MT) shows promise for knowledge-intensive tasks like idiomatic translation, but its reliability under noisy retrieval contexts remains poorly understood despite this being a common challenge in real-world deployment. To address this gap, we propose a noise synthesis framework and new metrics to evaluate the robustness of REAL-MT systematically. Using this framework, we instantiate REAL-MT with Qwen-series models, including standard LLMs and large reasoning models (LRMs) with enhanced reasoning, and evaluate their performance on idiomatic translation across high-, medium-, and low-resource language pairs under synthesized noise. Our results show that low-resource language pairs, which rely more heavily on retrieved context, degrade more severely under noise than high-resource ones and often produce nonsensical translations. Although LRMs possess enhanced reasoning capabilities, they show no improvement in error correction and are even more susceptible to noise, tending to rationalize incorrect contexts. We find that this stems from an attention shift away from the source idiom to noisy content, while confidence increases despite declining accuracy, indicating poor calibration. To mitigate these issues, we investigate training-free and fine-tuning strategies, which improve robustness at the cost of performance in clean contexts, revealing a fundamental trade-off. Our findings highlight the limitations of current approaches, underscoring the need for self-verifying integration mechanisms.
Synthesizing Sheet Music Problems for Evaluation and Reinforcement Learning
Sep 04, 2025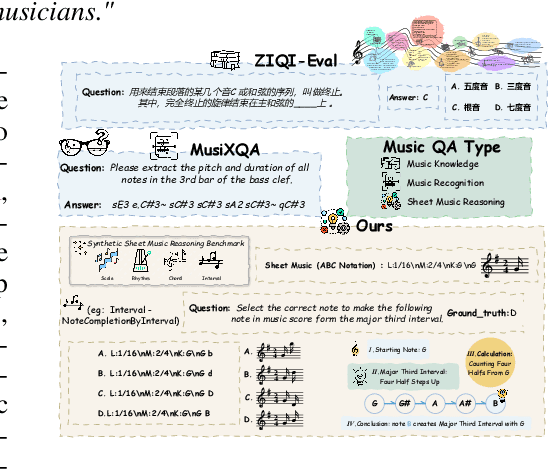

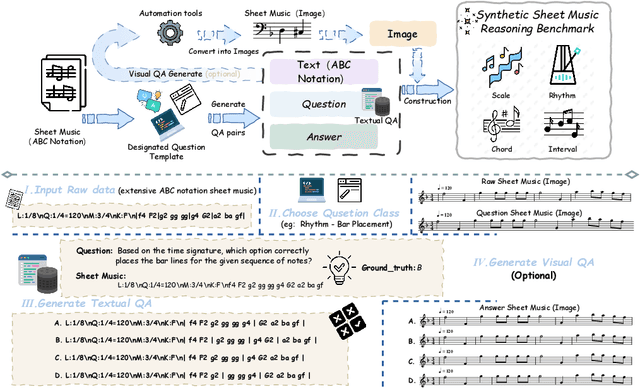
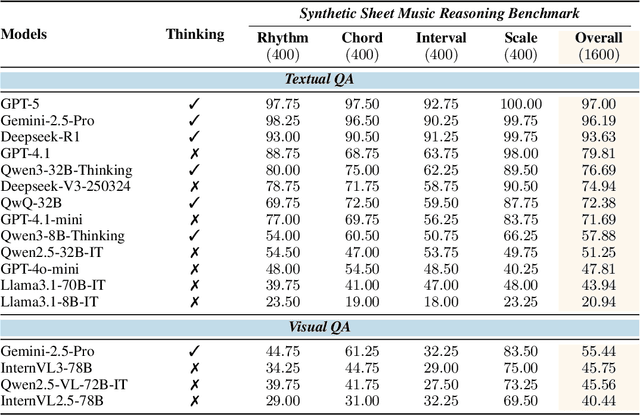
Enhancing the ability of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) to interpret sheet music is a crucial step toward building AI musicians. However, current research lacks both evaluation benchmarks and training data for sheet music reasoning. To address this, we propose the idea of synthesizing sheet music problems grounded in music theory, which can serve both as evaluation benchmarks and as training data for reinforcement learning with verifiable rewards (RLVR). We introduce a data synthesis framework that generates verifiable sheet music questions in both textual and visual modalities, leading to the Synthetic Sheet Music Reasoning Benchmark (SSMR-Bench) and a complementary training set. Evaluation results on SSMR-Bench show the importance of models' reasoning abilities in interpreting sheet music. At the same time, the poor performance of Gemini 2.5-Pro highlights the challenges that MLLMs still face in interpreting sheet music in a visual format. By leveraging synthetic data for RLVR, Qwen3-8B-Base and Qwen2.5-VL-Instruct achieve improvements on the SSMR-Bench. Besides, the trained Qwen3-8B-Base surpasses GPT-4 in overall performance on MusicTheoryBench and achieves reasoning performance comparable to GPT-4 with the strategies of Role play and Chain-of-Thought. Notably, its performance on math problems also improves relative to the original Qwen3-8B-Base. Furthermore, our results show that the enhanced reasoning ability can also facilitate music composition. In conclusion, we are the first to propose the idea of synthesizing sheet music problems based on music theory rules, and demonstrate its effectiveness not only in advancing model reasoning for sheet music understanding but also in unlocking new possibilities for AI-assisted music creation.
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns
Aug 18, 2025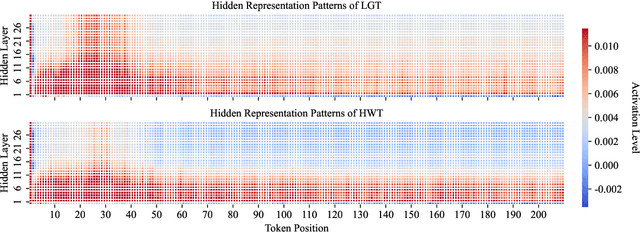

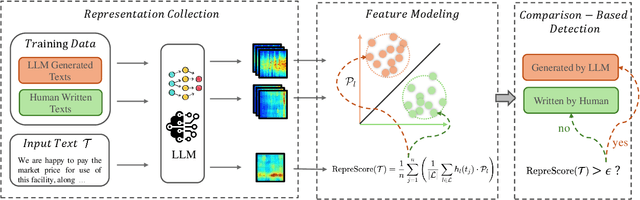

Detecting content generated by large language models (LLMs) is crucial for preventing misuse and building trustworthy AI systems. Although existing detection methods perform well, their robustness in out-of-distribution (OOD) scenarios is still lacking. In this paper, we hypothesize that, compared to features used by existing detection methods, the internal representations of LLMs contain more comprehensive and raw features that can more effectively capture and distinguish the statistical pattern differences between LLM-generated texts (LGT) and human-written texts (HWT). We validated this hypothesis across different LLMs and observed significant differences in neural activation patterns when processing these two types of texts. Based on this, we propose RepreGuard, an efficient statistics-based detection method. Specifically, we first employ a surrogate model to collect representation of LGT and HWT, and extract the distinct activation feature that can better identify LGT. We can classify the text by calculating the projection score of the text representations along this feature direction and comparing with a precomputed threshold. Experimental results show that RepreGuard outperforms all baselines with average 94.92% AUROC on both in-distribution (ID) and OOD scenarios, while also demonstrating robust resilience to various text sizes and mainstream attacks. Data and code are publicly available at: https://github.com/NLP2CT/RepreGuard
Rethinking Prompt-based Debiasing in Large Language Models
Mar 12, 2025
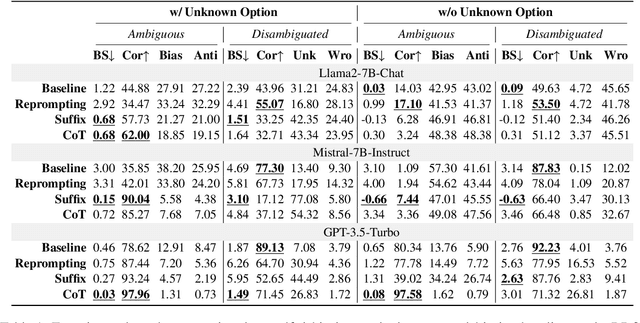
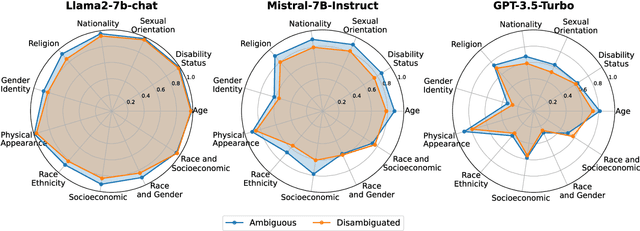
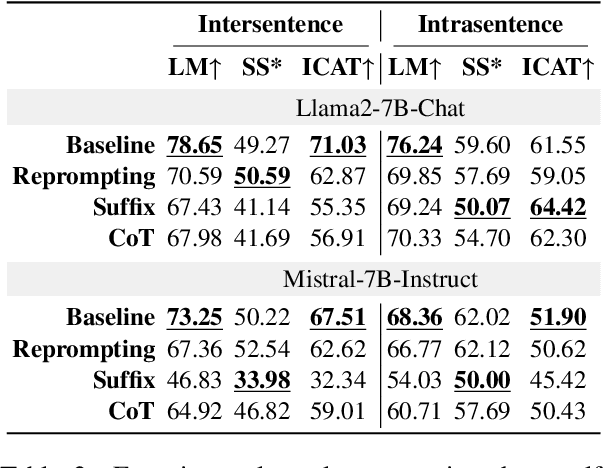
Investigating bias in large language models (LLMs) is crucial for developing trustworthy AI. While prompt-based through prompt engineering is common, its effectiveness relies on the assumption that models inherently understand biases. Our study systematically analyzed this assumption using the BBQ and StereoSet benchmarks on both open-source models as well as commercial GPT model. Experimental results indicate that prompt-based is often superficial; for instance, the Llama2-7B-Chat model misclassified over 90% of unbiased content as biased, despite achieving high accuracy in identifying bias issues on the BBQ dataset. Additionally, specific evaluation and question settings in bias benchmarks often lead LLMs to choose "evasive answers", disregarding the core of the question and the relevance of the response to the context. Moreover, the apparent success of previous methods may stem from flawed evaluation metrics. Our research highlights a potential "false prosperity" in prompt-base efforts and emphasizes the need to rethink bias metrics to ensure truly trustworthy AI.
Intrinsic Model Weaknesses: How Priming Attacks Unveil Vulnerabilities in Large Language Models
Feb 23, 2025Large language models (LLMs) have significantly influenced various industries but suffer from a critical flaw, the potential sensitivity of generating harmful content, which poses severe societal risks. We developed and tested novel attack strategies on popular LLMs to expose their vulnerabilities in generating inappropriate content. These strategies, inspired by psychological phenomena such as the "Priming Effect", "Safe Attention Shift", and "Cognitive Dissonance", effectively attack the models' guarding mechanisms. Our experiments achieved an attack success rate (ASR) of 100% on various open-source models, including Meta's Llama-3.2, Google's Gemma-2, Mistral's Mistral-NeMo, Falcon's Falcon-mamba, Apple's DCLM, Microsoft's Phi3, and Qwen's Qwen2.5, among others. Similarly, for closed-source models such as OpenAI's GPT-4o, Google's Gemini-1.5, and Claude-3.5, we observed an ASR of at least 95% on the AdvBench dataset, which represents the current state-of-the-art. This study underscores the urgent need to reassess the use of generative models in critical applications to mitigate potential adverse societal impacts.
DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios
Oct 31, 2024
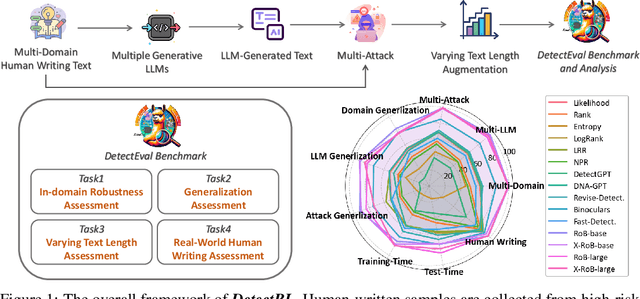
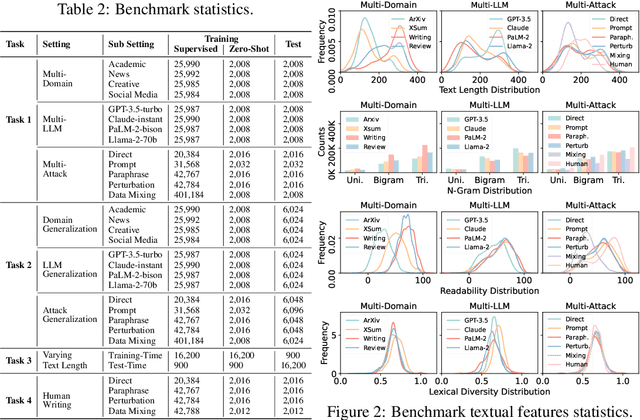
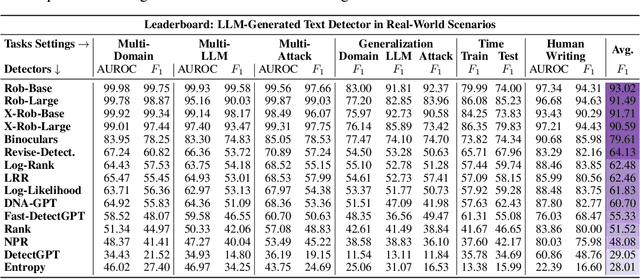
Detecting text generated by large language models (LLMs) is of great recent interest. With zero-shot methods like DetectGPT, detection capabilities have reached impressive levels. However, the reliability of existing detectors in real-world applications remains underexplored. In this study, we present a new benchmark, DetectRL, highlighting that even state-of-the-art (SOTA) detection techniques still underperformed in this task. We collected human-written datasets from domains where LLMs are particularly prone to misuse. Using popular LLMs, we generated data that better aligns with real-world applications. Unlike previous studies, we employed heuristic rules to create adversarial LLM-generated text, simulating advanced prompt usages, human revisions like word substitutions, and writing errors. Our development of DetectRL reveals the strengths and limitations of current SOTA detectors. More importantly, we analyzed the potential impact of writing styles, model types, attack methods, the text lengths, and real-world human writing factors on different types of detectors. We believe DetectRL could serve as an effective benchmark for assessing detectors in real-world scenarios, evolving with advanced attack methods, thus providing more stressful evaluation to drive the development of more efficient detectors. Data and code are publicly available at: https://github.com/NLP2CT/DetectRL.