 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-ImagenTime: Multi-Resolution Time Series Generation through Dual Image Representations
Mar 30, 2026Time series forecasting is vital across many domains, yet existing models struggle with fixed-length inputs and inadequate multi-scale modeling. We propose MR-CDM, a framework combining hierarchical multi-resolution trend decomposition, an adaptive embedding mechanism for variable-length inputs, and a multi-scale conditional diffusion process. Evaluations on four real-world datasets demonstrate that MR-CDM significantly outperforms state-of-the-art baselines (e.g., CSDI, Informer), reducing MAE and RMSE by approximately 6-10 to a certain degree.
Beyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
Bayesian Subspace Gradient Estimation for Zeroth-Order Optimization of Large Language Models
Jan 04, 2026Fine-tuning large language models (LLMs) with zeroth-order (ZO) optimization reduces memory by approximating gradients through function evaluations, but existing methods rely on one-step gradient estimates from random perturbations. We introduce Bayesian Subspace Zeroth-Order optimization (BSZO), a ZO optimizer that applies Kalman filtering to combine finite-difference information across multiple perturbation directions. By treating each finite-difference measurement as a noisy observation, BSZO builds a posterior distribution over the projected gradient and updates it through Bayesian inference, with a residual-based adaptive mechanism to adjust perturbation scales. Theoretical analysis shows that BSZO improves the convergence rate by a factor of $k/γ$ compared to standard ZO methods. Experiments on RoBERTa, Mistral, and OPT models show that BSZO outperforms MeZO, MeZO-Adam, and HiZOO across various tasks, achieving up to 6.67\% absolute average improvement on OPT-13B while keeping memory usage close to inference-only baselines (1.00$\times$--1.08$\times$ of MeZO).
Are Large Reasoning Models Good Translation Evaluators? Analysis and Performance Boost
Oct 23, 2025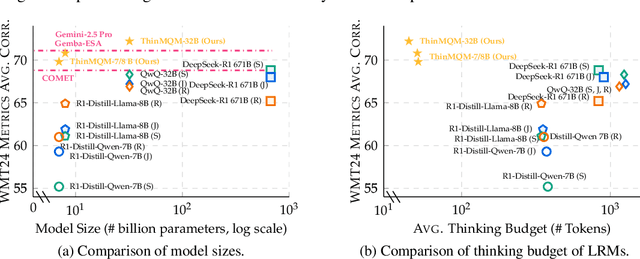
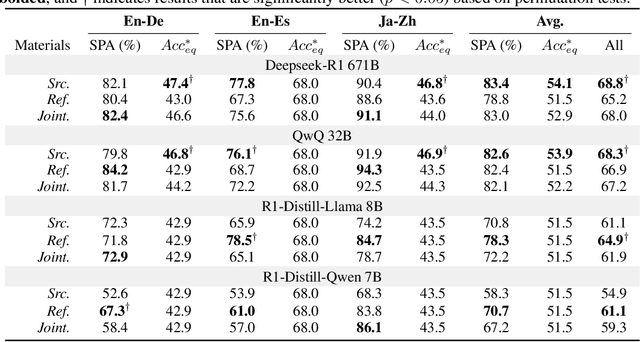
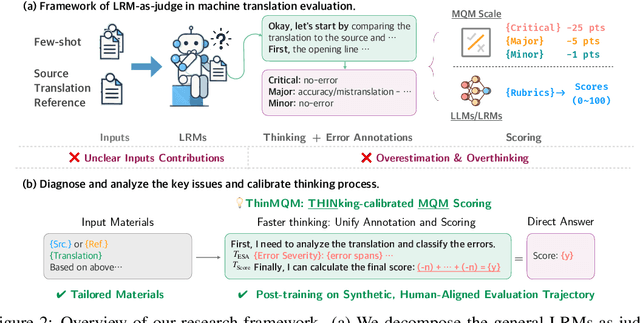

Recent advancements in large reasoning models (LRMs) have introduced an intermediate "thinking" process prior to generating final answers, improving their reasoning capabilities on complex downstream tasks. However, the potential of LRMs as evaluators for machine translation (MT) quality remains underexplored. We provides the first systematic analysis of LRM-as-a-judge in MT evaluation. We identify key challenges, revealing LRMs require tailored evaluation materials, tend to "overthink" simpler instances and have issues with scoring mechanisms leading to overestimation. To address these, we propose to calibrate LRM thinking by training them on synthetic, human-like thinking trajectories. Our experiments on WMT24 Metrics benchmarks demonstrate that this approach largely reduces thinking budgets by ~35x while concurrently improving evaluation performance across different LRM scales from 7B to 32B (e.g., R1-Distill-Qwen-7B achieves a +8.7 correlation point improvement). These findings highlight the potential of efficiently calibrated LRMs to advance fine-grained automatic MT evaluation.
How Does Pretraining Improve Discourse-Aware Translation?
May 31, 2023



Pretrained language models (PLMs) have produced substantial improvements in discourse-aware neural machine translation (NMT), for example, improved coherence in spoken language translation. However, the underlying reasons for their strong performance have not been well explained. To bridge this gap, we introduce a probing task to interpret the ability of PLMs to capture discourse relation knowledge. We validate three state-of-the-art PLMs across encoder-, decoder-, and encoder-decoder-based models. The analysis shows that (1) the ability of PLMs on discourse modelling varies from architecture and layer; (2) discourse elements in a text lead to different learning difficulties for PLMs. Besides, we investigate the effects of different PLMs on spoken language translation. Through experiments on IWSLT2017 Chinese-English dataset, we empirically reveal that NMT models initialized from different layers of PLMs exhibit the same trends with the probing task. Our findings are instructive to understand how and when discourse knowledge in PLMs should work for downstream tasks.
Deep-Learning-based Vasculature Extraction for Single-Scan Optical Coherence Tomography Angiography
May 03, 2023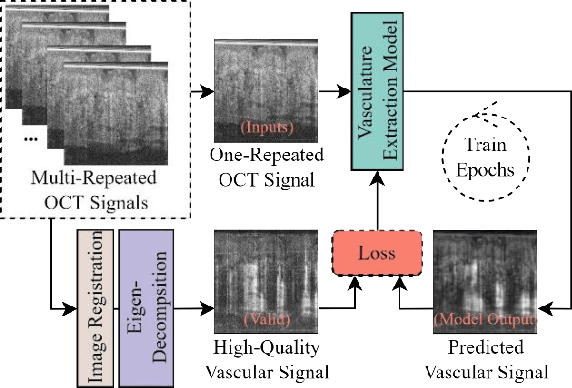
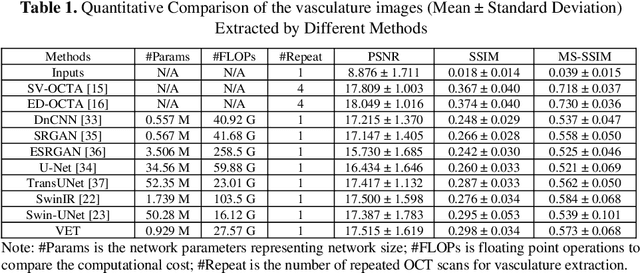

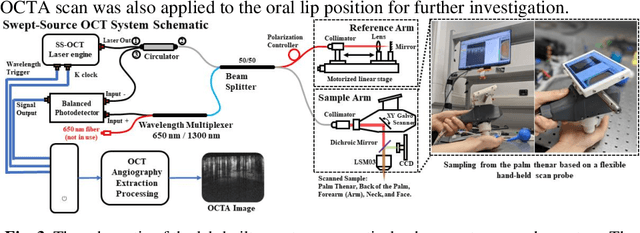
Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that extends the functionality of OCT by extracting moving red blood cell signals from surrounding static biological tissues. OCTA has emerged as a valuable tool for analyzing skin microvasculature, enabling more accurate diagnosis and treatment monitoring. Most existing OCTA extraction algorithms, such as speckle variance (SV)- and eigen-decomposition (ED)-OCTA, implement a larger number of repeated (NR) OCT scans at the same position to produce high-quality angiography images. However, a higher NR requires a longer data acquisition time, leading to more unpredictable motion artifacts. In this study, we propose a vasculature extraction pipeline that uses only one-repeated OCT scan to generate OCTA images. The pipeline is based on the proposed Vasculature Extraction Transformer (VET), which leverages convolutional projection to better learn the spatial relationships between image patches. In comparison to OCTA images obtained via the SV-OCTA (PSNR: 17.809) and ED-OCTA (PSNR: 18.049) using four-repeated OCT scans, OCTA images extracted by VET exhibit moderate quality (PSNR: 17.515) and higher image contrast while reducing the required data acquisition time from ~8 s to ~2 s. Based on visual observations, the proposed VET outperforms SV and ED algorithms when using neck and face OCTA data in areas that are challenging to scan. This study represents that the VET has the capacity to extract vascularture images from a fast one-repeated OCT scan, facilitating accurate diagnosis for patients.