 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven Paradigm-Based Image Denoising and Mosaicking Approach for High-Resolution Acoustic Camera
Feb 19, 2025In this work, an approach based on a data-driven paradigm to denoise and mosaic acoustic camera images is proposed. Acoustic cameras, also known as 2D forward-looking sonar, could collect high-resolution acoustic images in dark and turbid water. However, due to the unique sensor imaging mechanism, main vision-based processing methods, like image denoising and mosaicking are still in the early stages. Due to the complex noise interference in acoustic images and the narrow field of view of acoustic cameras, it is difficult to restore the entire detection scene even if enough acoustic images are collected. Relevant research work addressing these issues focuses on the design of handcrafted operators for acoustic image processing based on prior knowledge and sensor models. However, such methods lack robustness due to noise interference and insufficient feature details on acoustic images. This study proposes an acoustic image denoising and mosaicking method based on a data-driven paradigm and conducts experimental testing using collected acoustic camera images. The results demonstrate the effectiveness of the proposal.
MeloTrans: A Text to Symbolic Music Generation Model Following Human Composition Habit
Oct 17, 2024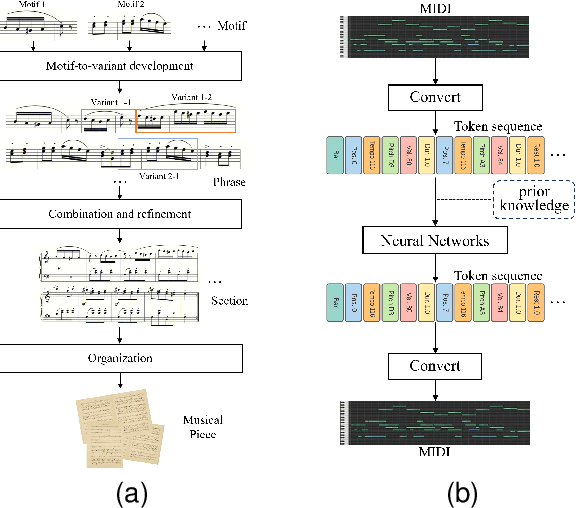

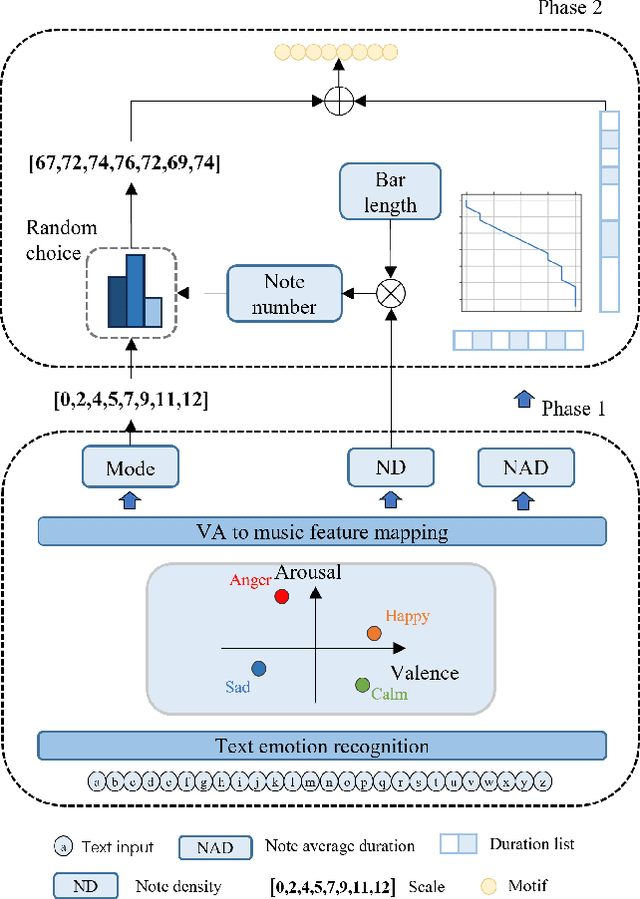
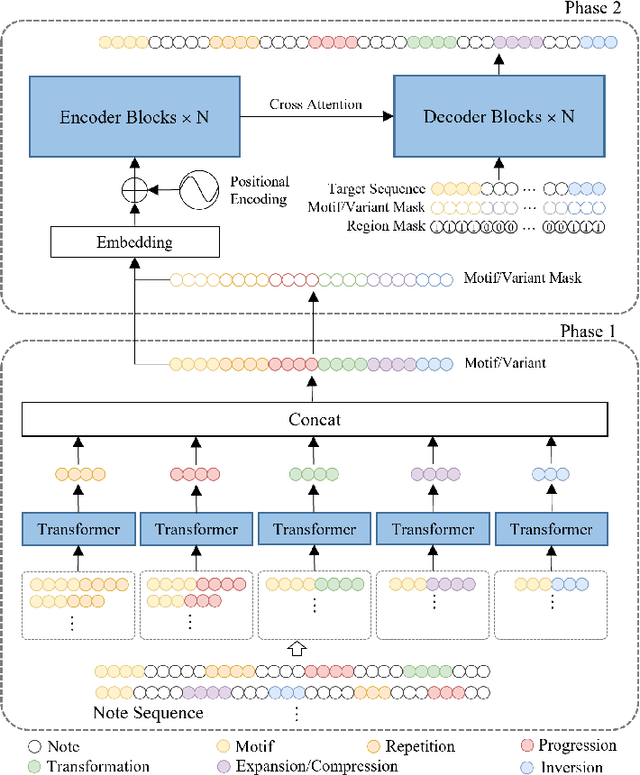
At present, neural network models show powerful sequence prediction ability and are used in many automatic composition models. In comparison, the way humans compose music is very different from it. Composers usually start by creating musical motifs and then develop them into music through a series of rules. This process ensures that the music has a specific structure and changing pattern. However, it is difficult for neural network models to learn these composition rules from training data, which results in a lack of musicality and diversity in the generated music. This paper posits that integrating the learning capabilities of neural networks with human-derived knowledge may lead to better results. To archive this, we develop the POP909$\_$M dataset, the first to include labels for musical motifs and their variants, providing a basis for mimicking human compositional habits. Building on this, we propose MeloTrans, a text-to-music composition model that employs principles of motif development rules. Our experiments demonstrate that MeloTrans excels beyond existing music generation models and even surpasses Large Language Models (LLMs) like ChatGPT-4. This highlights the importance of merging human insights with neural network capabilities to achieve superior symbolic music generation.
A Self-Supervised Denoising Strategy for Underwater Acoustic Camera Imageries
Jun 05, 2024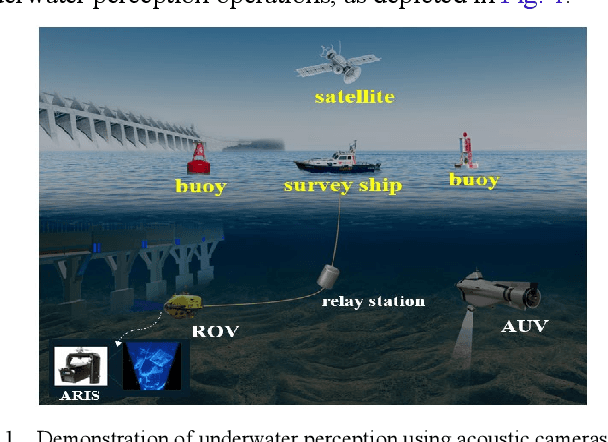
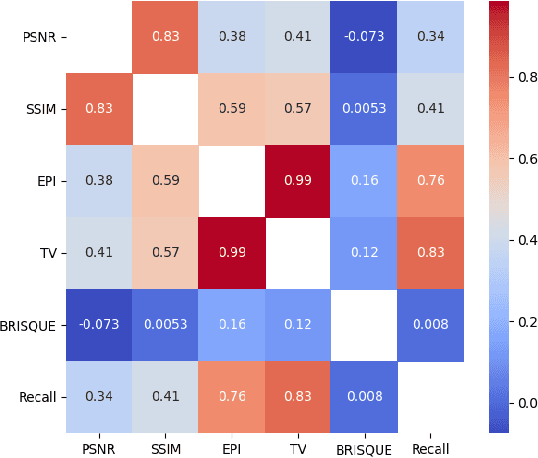
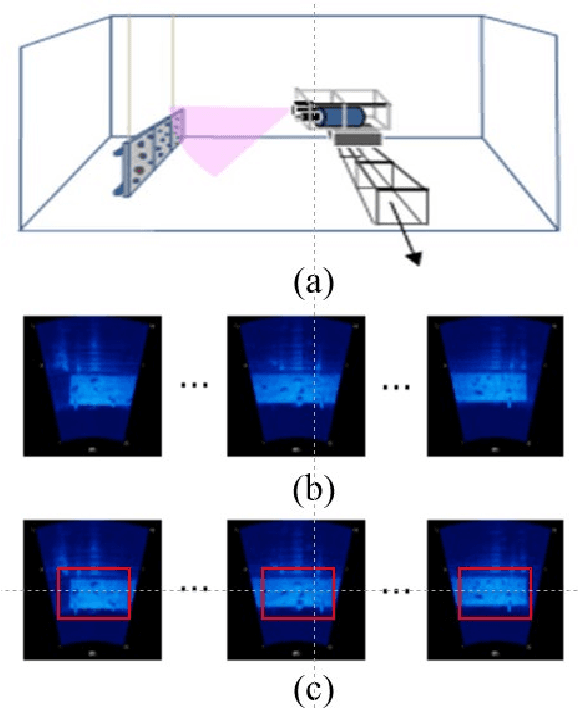

In low-visibility marine environments characterized by turbidity and darkness, acoustic cameras serve as visual sensors capable of generating high-resolution 2D sonar images. However, acoustic camera images are interfered with by complex noise and are difficult to be directly ingested by downstream visual algorithms. This paper introduces a novel strategy for denoising acoustic camera images using deep learning techniques, which comprises two principal components: a self-supervised denoising framework and a fine feature-guided block. Additionally, the study explores the relationship between the level of image denoising and the improvement in feature-matching performance. Experimental results show that the proposed denoising strategy can effectively filter acoustic camera images without prior knowledge of the noise model. The denoising process is nearly end-to-end without complex parameter tuning and post-processing. It successfully removes noise while preserving fine feature details, thereby enhancing the performance of local feature matching.
Self-distilled Dynamic Fusion Network for Language-based Fashion Retrieval
May 24, 2024



In the domain of language-based fashion image retrieval, pinpointing the desired fashion item using both a reference image and its accompanying textual description is an intriguing challenge. Existing approaches lean heavily on static fusion techniques, intertwining image and text. Despite their commendable advancements, these approaches are still limited by a deficiency in flexibility. In response, we propose a Self-distilled Dynamic Fusion Network to compose the multi-granularity features dynamically by considering the consistency of routing path and modality-specific information simultaneously. Two new modules are included in our proposed method: (1) Dynamic Fusion Network with Modality Specific Routers. The dynamic network enables a flexible determination of the routing for each reference image and modification text, taking into account their distinct semantics and distributions. (2) Self Path Distillation Loss. A stable path decision for queries benefits the optimization of feature extraction as well as routing, and we approach this by progressively refine the path decision with previous path information. Extensive experiments demonstrate the effectiveness of our proposed model compared to existing methods.
Deep-Learning-based Vasculature Extraction for Single-Scan Optical Coherence Tomography Angiography
May 03, 2023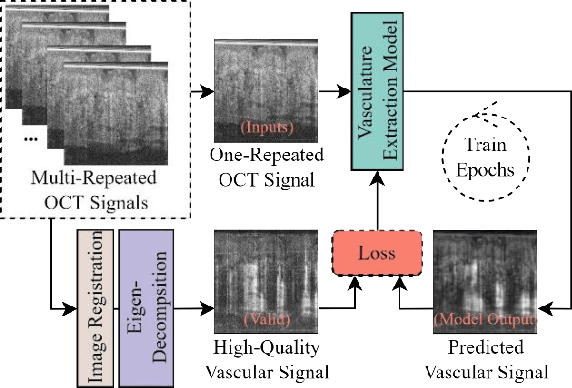
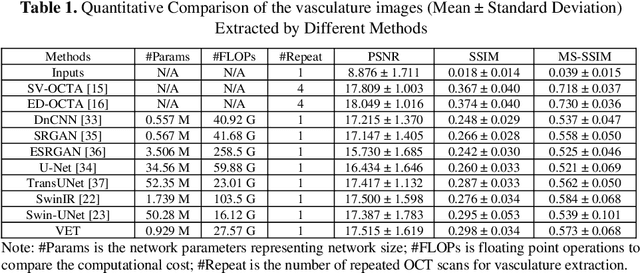

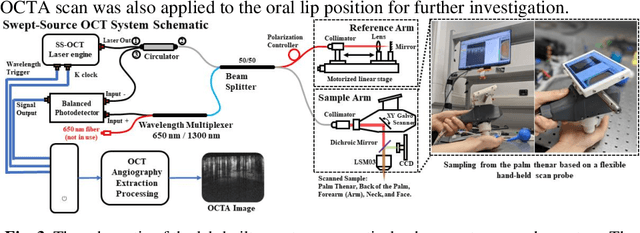
Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that extends the functionality of OCT by extracting moving red blood cell signals from surrounding static biological tissues. OCTA has emerged as a valuable tool for analyzing skin microvasculature, enabling more accurate diagnosis and treatment monitoring. Most existing OCTA extraction algorithms, such as speckle variance (SV)- and eigen-decomposition (ED)-OCTA, implement a larger number of repeated (NR) OCT scans at the same position to produce high-quality angiography images. However, a higher NR requires a longer data acquisition time, leading to more unpredictable motion artifacts. In this study, we propose a vasculature extraction pipeline that uses only one-repeated OCT scan to generate OCTA images. The pipeline is based on the proposed Vasculature Extraction Transformer (VET), which leverages convolutional projection to better learn the spatial relationships between image patches. In comparison to OCTA images obtained via the SV-OCTA (PSNR: 17.809) and ED-OCTA (PSNR: 18.049) using four-repeated OCT scans, OCTA images extracted by VET exhibit moderate quality (PSNR: 17.515) and higher image contrast while reducing the required data acquisition time from ~8 s to ~2 s. Based on visual observations, the proposed VET outperforms SV and ED algorithms when using neck and face OCTA data in areas that are challenging to scan. This study represents that the VET has the capacity to extract vascularture images from a fast one-repeated OCT scan, facilitating accurate diagnosis for patients.
Internal Structure Attention Network for Fingerprint Presentation Attack Detection from Optical Coherence Tomography
Mar 20, 2023



As a non-invasive optical imaging technique, optical coherence tomography (OCT) has proven promising for automatic fingerprint recognition system (AFRS) applications. Diverse approaches have been proposed for OCT-based fingerprint presentation attack detection (PAD). However, considering the complexity and variety of PA samples, it is extremely challenging to increase the generalization ability with the limited PA dataset. To solve the challenge, this paper presents a novel supervised learning-based PAD method, denoted as ISAPAD, which applies prior knowledge to guide network training and enhance the generalization ability. The proposed dual-branch architecture can not only learns global features from the OCT image, but also concentrate on layered structure feature which comes from the internal structure attention module (ISAM). The simple yet effective ISAM enables the proposed network to obtain layered segmentation features belonging only to Bonafide from noisy OCT volume data directly. Combined with effective training strategies and PAD score generation rules, ISAPAD obtains optimal PAD performance in limited training data. Domain generalization experiments and visualization analysis validate the effectiveness of the proposed method for OCT PAD.
Sparse Convex Clustering
Feb 10, 2017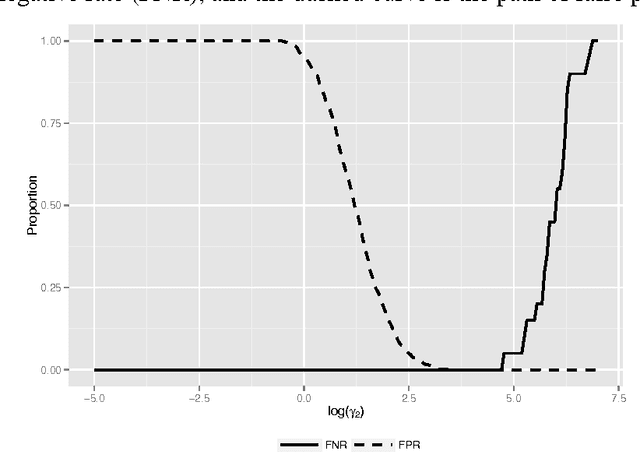
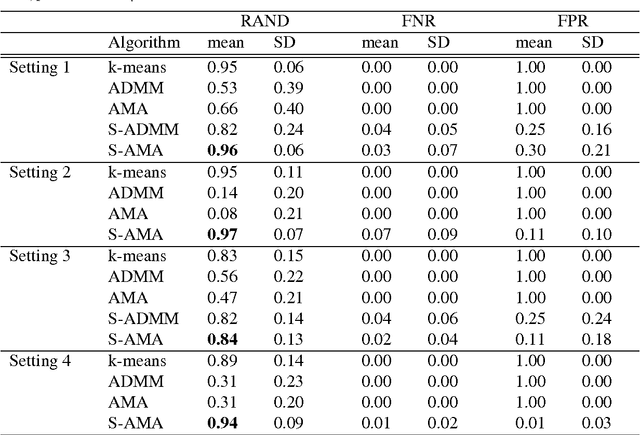
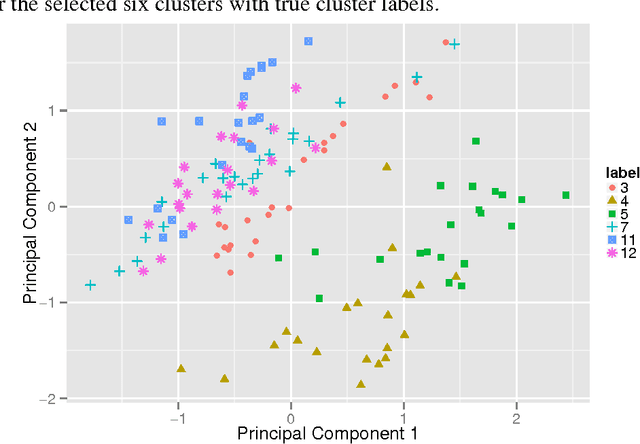
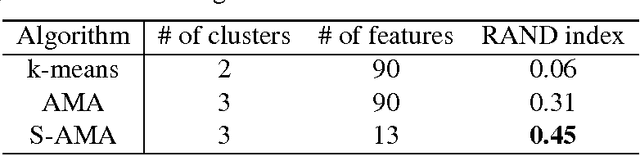
Convex clustering, a convex relaxation of k-means clustering and hierarchical clustering, has drawn recent attentions since it nicely addresses the instability issue of traditional nonconvex clustering methods. Although its computational and statistical properties have been recently studied, the performance of convex clustering has not yet been investigated in the high-dimensional clustering scenario, where the data contains a large number of features and many of them carry no information about the clustering structure. In this paper, we demonstrate that the performance of convex clustering could be distorted when the uninformative features are included in the clustering. To overcome it, we introduce a new clustering method, referred to as Sparse Convex Clustering, to simultaneously cluster observations and conduct feature selection. The key idea is to formulate convex clustering in a form of regularization, with an adaptive group-lasso penalty term on cluster centers. In order to optimally balance the tradeoff between the cluster fitting and sparsity, a tuning criterion based on clustering stability is developed. In theory, we provide an unbiased estimator for the degrees of freedom of the proposed sparse convex clustering method. Finally, the effectiveness of the sparse convex clustering is examined through a variety of numerical experiments and a real data application.