 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Convex Biclustering
Jan 05, 2026Biclustering is an essential unsupervised machine learning technique for simultaneously clustering rows and columns of a data matrix, with widespread applications in genomics, transcriptomics, and other high-dimensional omics data. Despite its importance, existing biclustering methods struggle to meet the demands of modern large-scale datasets. The challenges stem from the accumulation of noise in high-dimensional features, the limitations of non-convex optimization formulations, and the computational complexity of identifying meaningful biclusters. These issues often result in reduced accuracy and stability as the size of the dataset increases. To overcome these challenges, we propose Sparse Convex Biclustering (SpaCoBi), a novel method that penalizes noise during the biclustering process to improve both accuracy and robustness. By adopting a convex optimization framework and introducing a stability-based tuning criterion, SpaCoBi achieves an optimal balance between cluster fidelity and sparsity. Comprehensive numerical studies, including simulations and an application to mouse olfactory bulb data, demonstrate that SpaCoBi significantly outperforms state-of-the-art methods in accuracy. These results highlight SpaCoBi as a robust and efficient solution for biclustering in high-dimensional and large-scale datasets.
Sparse Convex Clustering
Feb 10, 2017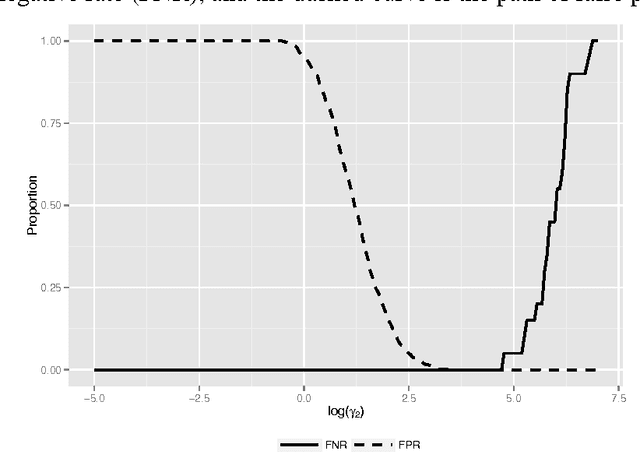
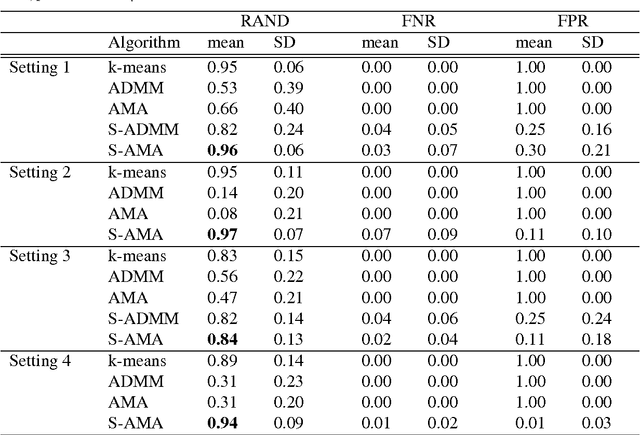
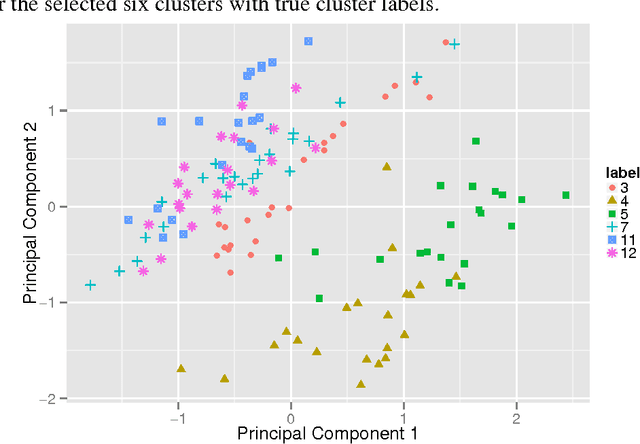
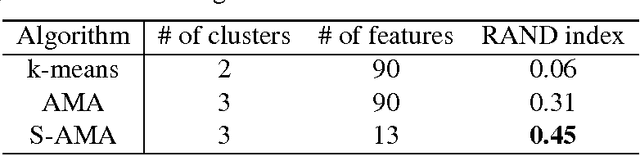
Convex clustering, a convex relaxation of k-means clustering and hierarchical clustering, has drawn recent attentions since it nicely addresses the instability issue of traditional nonconvex clustering methods. Although its computational and statistical properties have been recently studied, the performance of convex clustering has not yet been investigated in the high-dimensional clustering scenario, where the data contains a large number of features and many of them carry no information about the clustering structure. In this paper, we demonstrate that the performance of convex clustering could be distorted when the uninformative features are included in the clustering. To overcome it, we introduce a new clustering method, referred to as Sparse Convex Clustering, to simultaneously cluster observations and conduct feature selection. The key idea is to formulate convex clustering in a form of regularization, with an adaptive group-lasso penalty term on cluster centers. In order to optimally balance the tradeoff between the cluster fitting and sparsity, a tuning criterion based on clustering stability is developed. In theory, we provide an unbiased estimator for the degrees of freedom of the proposed sparse convex clustering method. Finally, the effectiveness of the sparse convex clustering is examined through a variety of numerical experiments and a real data application.